PowerScale, Isilon OneFS: HBase-ytelsestesting på Isilon
概要: Denne artikkelen illustrerer ytelsestestingen på en Isilon X410-klynge ved hjelp av Yahoo Cloud Serving Benchmarking (YCSB)-pakken og Cloudera Data Hub (CDH) 5.10.
この記事は次に適用されます:
この記事は次には適用されません:
この記事は、特定の製品に関連付けられていません。
すべての製品パージョンがこの記事に記載されているわけではありません。
現象
Ikke nødvendig
原因
Ikke nødvendig
解決方法
MERK: Dette emnet er en del av Bruke Hadoop med OneFS Info Hub.
Innledning
En rekke ytelsestester ble utført på en Isilon X410-klynge ved hjelp av YCSB-benchmarking-pakken og CDH 5.10.
Laboratorietestmiljøet ble konfigurert med fem Isilon x410-noder som kjører OneFS v8.0.0.4 og nyere v8.0.1.1. Network File System (NFS) Big Block streaming benchmarks ble kjørt. Det forventede teoretiske maksimumsmaksimumet for testene var ~700 MB/s (3,5 GB/s) skriveoperasjoner og ~1 GB/s leseoperasjoner (5 GB/s) per node.
De (9) Compute nodes er Dell PowerEdge FC630-servere som kjører CentOS v7.3.1611 hver konfigurert med 2x18C/36T-Intel Xeon® CPU E5-2697 v4 @ 2.30GHz med 512GB RAM. Lokal lagring er 2xSSD i RAID 1 formatert som XFS for både operativsystem og kladdeplass eller spillfiler.
Det var også tre ekstra Edge-servere som ble brukt til å drive YCSB-belastningen.
Backend-nettverket mellom databehandlingsnoder og Isilon er på 10 Gbps med Jumbo Frames angitt (MTU = 9162) for NIC-ene og svitsjportene.
Komponentene i Hadoop-testkonfigurasjonen (figur 1)
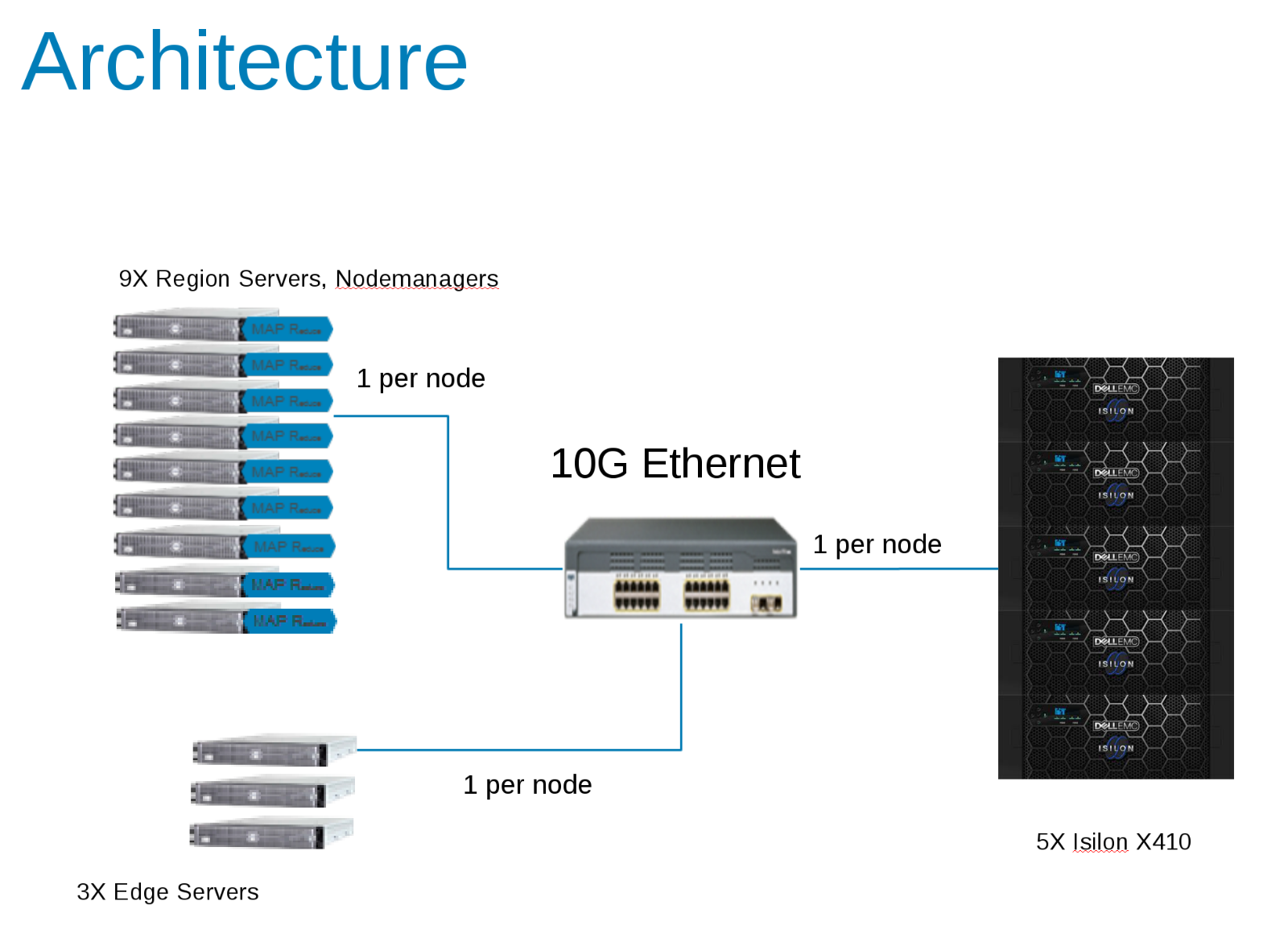
CDH 5.10 ble konfigurert til å kjøre i en tilgangssone på Isilon-klyngen. Servicekontoer ble opprettet i den lokale leverandøren av Isilon og lokalt i klientfilene /etc/passwd. Alle testene ble kjørt med en grunnleggende testklient uten spesielle rettigheter.
Isilon-statistikk ble overvåket med både IIQ- og Grafana/Data Insights-pakken. CDH-statistikk ble overvåket med Cloudera Manager og også med Grafana.
Innledende testing
Den første serien av tester skulle bestemme de relevante parametrene på HBASE-siden som påvirket den totale produksjonen. YCSB-verktøyet ble brukt til å generere belastningen for HBASE. Denne første testen ble kjørt ved hjelp av en enkelt klient (kant server) ved hjelp av "last" fase av YCSB og 40 millioner rader. Denne tabellen ble slettet før hver kjøring.
ycsb load hbase10 -P workloads/workloada1 -p table='ycsb_40Mtable_nr' -p columnfamily=family -threads 256 -p recordcount=40000000
- hbase.regionserver.maxlogs - Maksimalt antall WAL-filer (Write-Ahead Log) - Denne verdien multiplisert med HDFS-blokkstørrelse (dfs.blocksize) er størrelsen på WAL som må spilles på nytt når en server krasjer. Denne verdien er omvendt proporsjonal med frekvensen av spyling til disken.
- hbase.wal.regiongrouping.numgroups - Når du bruker flere HDFS WAL som WALProvider, angir dette hvor mange forhåndslogger hver RegionServer skal kjøre. Resultatene viser antall HDFS-rørledninger. Skrivinger for et gitt område går bare til én enkelt pipeline, og fordeler den totale belastningen på RegionServer.
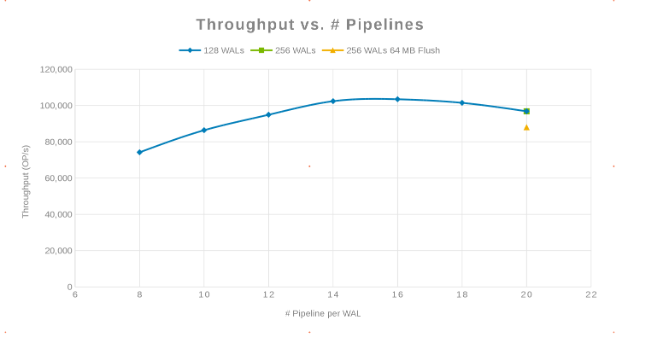
Gjennomstrømning sammenlignet med antall rørledninger (figur 2)
Ventetid sammenlignet med antall rørledninger (figur 3)
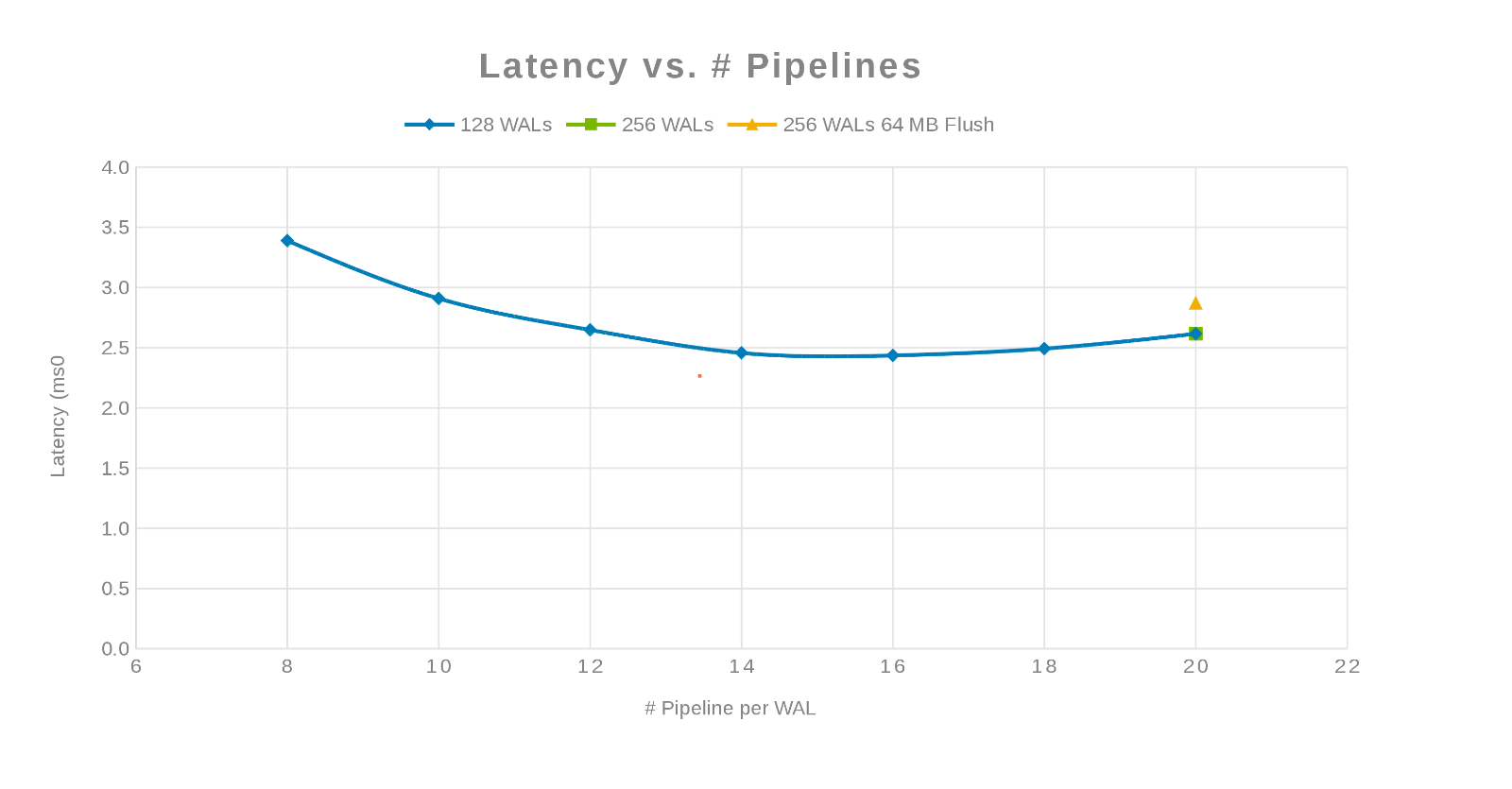
Filosofien her var å parallellisere så mange skriver som mulig. Å øke antall WAL-er og deretter antall tråder (rørledning) per WAL oppnår dette. De to foregående diagrammene viser at for et gitt tall for 'maxlogs', 128 eller 256, vises ingen reell endring. Dette indikerer at testen egentlig ikke påvirker resultatene fra klientsiden. Antall "pipelines" per fil ble variert, noe som viste en trend som indikerer parameteren som er følsom for parallellisering. Det neste spørsmålet er hvor kommer "Isilon-klyngen" i veien, enten med I/O-disk, nettverk, prosessor eller OneFS. For å svare på dette spørsmålet, se på Isilon-statistikkrapporten.
Bruk og belastning på Isilon-nettverket under testen (figur 4)
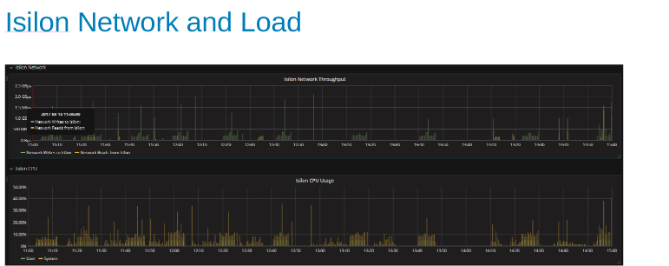
Nettverks- og CPU-grafene forteller oss at Isilon-klyngen er underutnyttet og har plass til mer arbeid. CPU vil være > 80 %, og nettverksbåndbredden vil være mer enn 3 GB/s.
Plott av HDFS-protokollen, statistikk og CPU-utnyttelse under HDFS-protokollbelastning (figur 5)
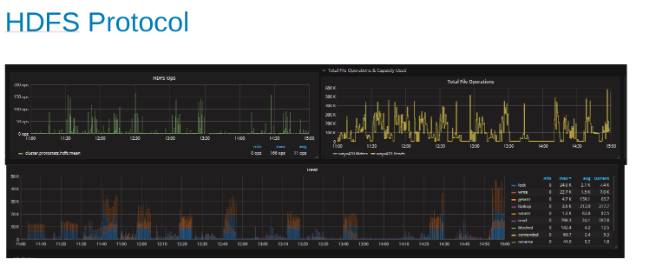
Disse plottene viser HDFS-protokollstatistikk og hvordan OneFS oversetter utdataene. HDFS ops er multipler av dfs.blocksize som er 256MB her. Det interessante her er at 'Heat' -grafen viser OneFS-filoperasjonene og korrelasjonen mellom skriving og låser vises. I dette tilfellet gjør HBase tilføyelser til WAL-ene, slik at OneFS låser WAL-filen for hver skriving som legges til. Som er det som forventes for stabile skriveoperasjoner på et klynget filsystem. Disse ser ut til å bidra til den begrensende faktoren i dette settet av tester.
Oppdateringer av HBase
Denne neste testen var å eksperimentere mer for å finne ut hva som skjer i stor skala. Det opprettes en tabell med 1 milliard rader som tok en time å generere. En YCSB test kjøres som oppdatert 10 millioner av radene ved hjelp av "workloada" innstillinger (50/50 lese / skrive). Denne testen ble kjørt på én enkelt klient. Testen kjørte som en funksjon av antall YCSB-tråder, slik at mest mulig gjennomstrømning kan genereres. Noe justering ble også brukt, og OneFS ble oppgradert til v8.0.1.1 som har ytelsesjusteringer for Data node-tjenesten. Følgende diagram viser økningen i ytelse sammenlignet med forrige sett med løp. For disse kjøringene er hbase.regionserver.maxlogs satt til 256 og hbase.wal.regiongrouping.numgroups til 20.
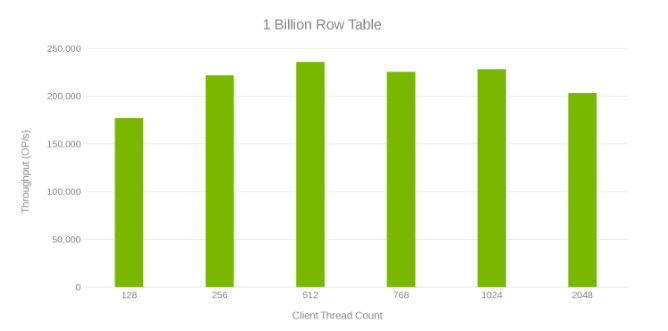
Gjennomstrømming og antall tråder under oppdatering av en tabell på 1 milliard rader (figur 6)
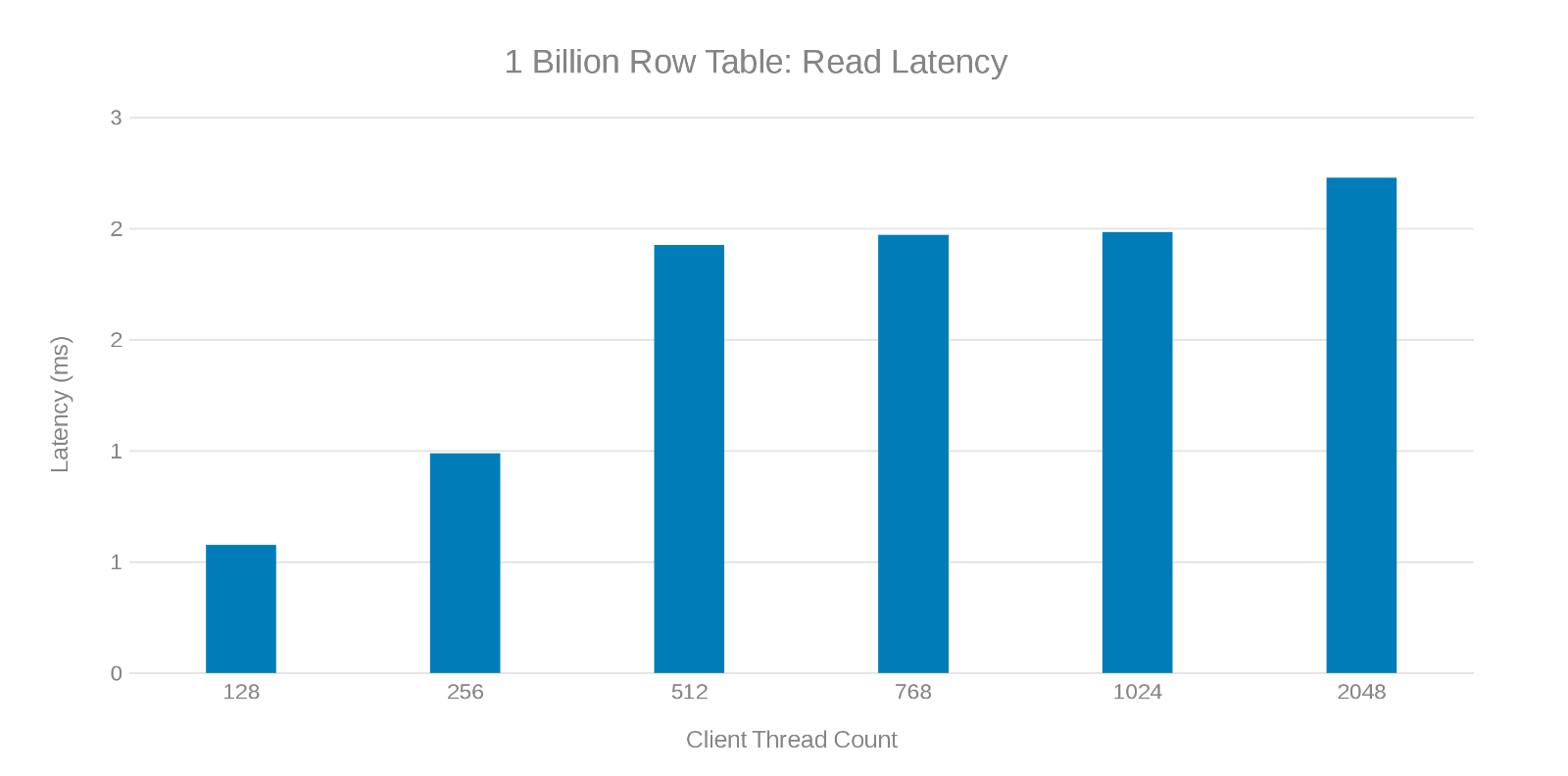
Leseventetid under oppdatering av tabell med 1 milliard rader (figur 7)
Oppdater ventetiden under oppdatering av tabell på 1 milliard rader (figur 8)
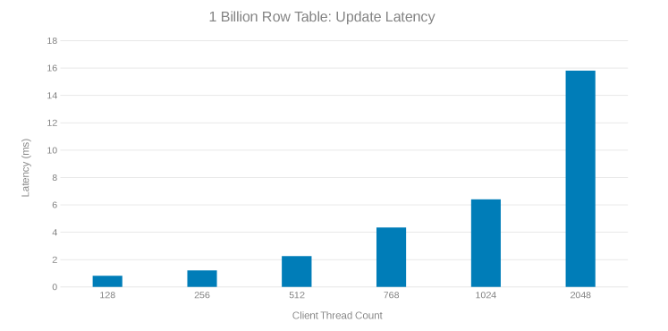
Gjennomgang av disse testkjøringene viser et tilsynelatende fall ved høyt trådantall, som enten kan være et Isilon- eller klientsideproblem. Testing viser og imponerer 200 tusen operasjoner per sekund med en oppdateringsforsinkelse på < 3 ms. Hver av oppdateringstestkjøringene var raske og kunne kjøres fortløpende. Grafen nedenfor viser en jevn balanse på tvers av Isilon-nodene for hver testkjøring.
Varmediagram som viser arbeidsbelastningen på tvers av hver node i Isilon-klyngen (figur 9)
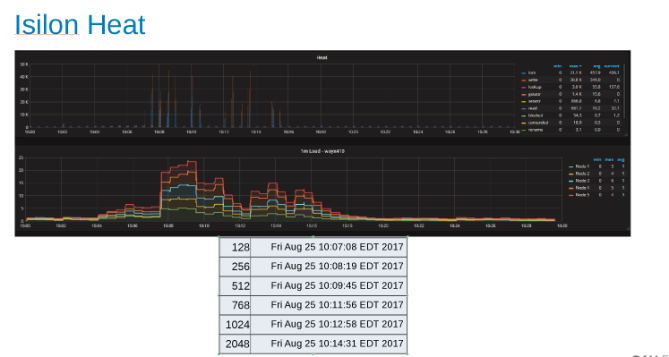
Varmegrafen viser at filoperasjonene er skrivinger og låser som tilsvarer tilføyingsnaturen til WAL-prosessene.
Skalering av områdeserver
Den neste testen var å bestemme hvordan Isilon-nodene (fem noder) ville klare seg mot et annet antall regionservere. Det samme oppdateringsskriptet som ble kjørt i den forrige testen, ble kjørt med en tabell på én milliard rader og en oppdatering på 10 millioner rader ved hjelp av «workloada». Testen brukte en enkelt klient med YCSB-tråder satt til 51. Den samme innstillingen for maxlogs og pipelines brukes (henholdsvis 256 og 20).
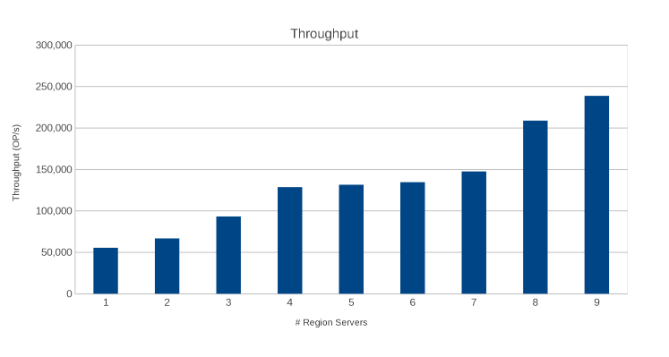
Gjennomstrømming på tvers av områdeservere (figur 10)
Ventetid på tvers av områdeservere (figur 11)
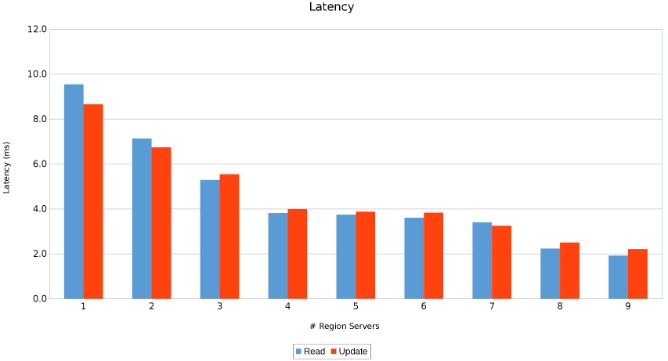
Resultatene er informative, om enn ikke overraskende. Skaleringen av HBase kombinert med utskaleringen av Isilon indikerte at mer er bedre. Denne testen anbefales for klienter å kjøre i sine miljøer som en del av sin egen størrelsesøvelse. Her er det ni servere som sender fem Isilon-noder, og det ser ut til at det fortsatt er plass til flere før man når punktet med avtagende avkastning.
Flere kunder
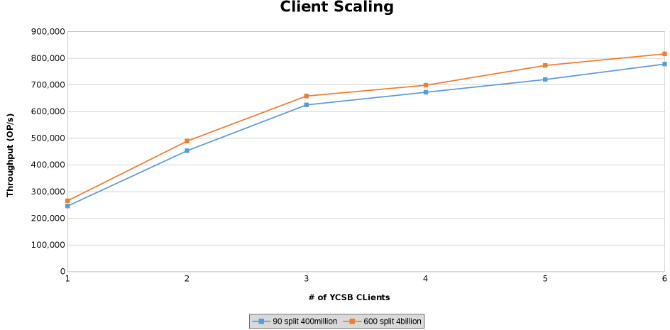
Den siste serien av tester tjente til å teste grensene for maskinvarekonfigurasjonen. Dette ble gjort for å bestemme den øvre grensen for parametrene som ble testet. I denne serien av tester brukes to ekstra servere til å kjøre klienter fra. I tillegg kjøres to YCSB-klienter fra hver server som tillot opptil seks klienter hver. Hver klient kjørte 512 tråder som resulterte i 4096 tråder totalt. To forskjellige tabeller ble opprettet. Én tabell med 4 milliarder rader delt inn i 600 områder, og en annen med 400 millioner rader delt inn i 90 områder.
Dette viser operasjonsgjennomstrømningen under testing av klientskalering (figur 12).
Måling av leseventetid under testing av klientskalering (figur 13)
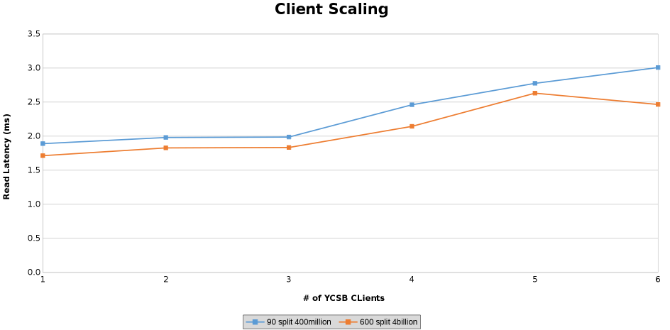
Måling av oppdateringsventetid under testing av klientskalering (figur 14)
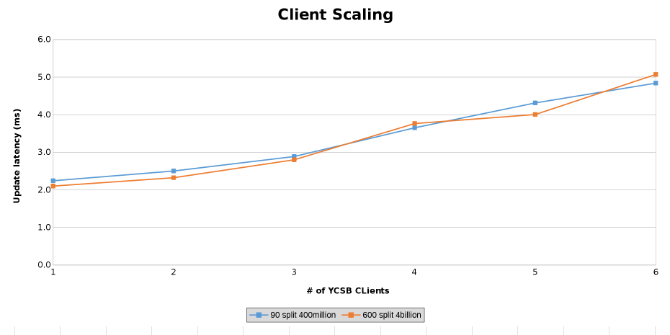
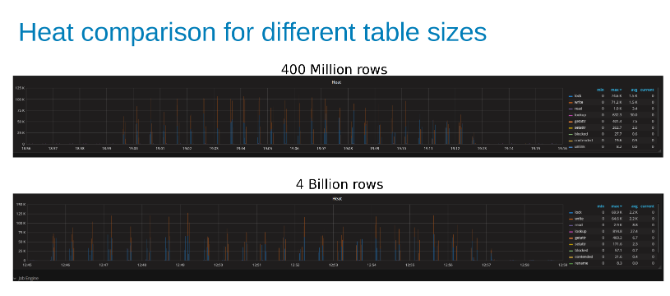
Grafene under viser at størrelsen på tabellen betyr lite i denne testen. Isilon Heat-diagrammene viser igjen at det er noen prosentvis forskjell i antall filoperasjoner. De fleste forskjellene var på linje med forskjellene mellom en tabell med fire milliarder rader og en tabell med 400 millioner rader.
Sammenligning av Isilon-varmen under oppdatering av en tabell på 400 millioner rader sammenlignet med en tabell med 4 milliarder rader (figur 15).
Konklusjon
HBase er en god kandidat for å kjøre på Isilon, hovedsakelig på grunn av utskalering til utskalering av arkitekturer. HBase gjør mye av sin egen caching, og ved å dele tabellen over et stort antall regioner, kan HBase skalere ut med dataene. Med andre ord gjør den en god jobb med å ta vare på sine egne behov, og filsystemet er der for applikasjonsmotstandskraft. Testing var ikke i stand til å presse lasten til det punktet å bryte ting. Hvis HBase er designet for 800 000 operasjoner med mindre enn 3 ms ventetid, støtter denne arkitekturen den. HBase støtter et mylder av ytelsesjusteringer og justeringer for både klientsiden og HBase selv. Testing av alle disse justeringene og justeringene var utenfor omfanget av denne testen.対象製品
Isilon, PowerScale OneFS文書のプロパティ
文書番号: 000128942
文書の種類: Solution
最終更新: 11 3月 2026
バージョン: 7
質問に対する他のDellユーザーからの回答を見つける
サポート サービス
お使いのデバイスがサポート サービスの対象かどうかを確認してください。