PowerScale, Isilon OneFS : Tests des performances HBase sur Isilon (en anglais)
概要: Cet article illustre les tests d’analyse comparative des performances sur un cluster Isilon X410 à l’aide de la suite Yahoo Cloud Serving Benchmarking (YCSB) et de Cloudera Data Hub (CDH) 5.10. ...
この記事は次に適用されます:
この記事は次には適用されません:
この記事は、特定の製品に関連付けられていません。
すべての製品パージョンがこの記事に記載されているわけではありません。
現象
Non requise
原因
Non requise
解決方法
Remarque : Cette rubrique fait partie du Hub d’informations sur l’utilisation de Hadoop avec OneFS.
Introduction
Une série de tests d’analyse comparative des performances a été effectuée sur un cluster Isilon X410 à l’aide de la suite d’analyses comparatives YCSB et de CDH 5.10.
L’environnement de test en laboratoire a été configuré avec cinq nœuds Isilon x410 exécutant OneFS v8.0.0.4 et versions ultérieures v8.0.1.1. Des benchmarks de streaming NFS (Network File System) pour les blocs volumineux ont été exécutés. Le maximum global théorique attendu pour les tests était de ~700 Mo/s (3,5 Go/s) en écriture et de ~1 Go/s en lecture (5 Go/s) par nœud.
Les (9) nœuds de calcul sont des serveurs Dell PowerEdge FC630 exécutant CentOS v7.3.1611, chacun configuré avec 2x18C/36T-processeur Intel Xeon® E5-2697 v4 @ 2,30 GHz avec 512 Go de RAM. Le stockage local est composé de 2 disques SSD en RAID 1 formatés au format XFS pour le système d’exploitation et l’espace de travail ou les fichiers de déversement.
Trois serveurs Edge supplémentaires ont également été utilisés pour gérer la charge YCSB.
Le réseau back-end entre les nœuds de calcul et Isilon est de 10 Gbit/s avec les trames Jumbo définies (MTU=9162) pour les cartes réseau et les ports de commutateur.
Composants de la configuration du test Hadoop (Figure 1)
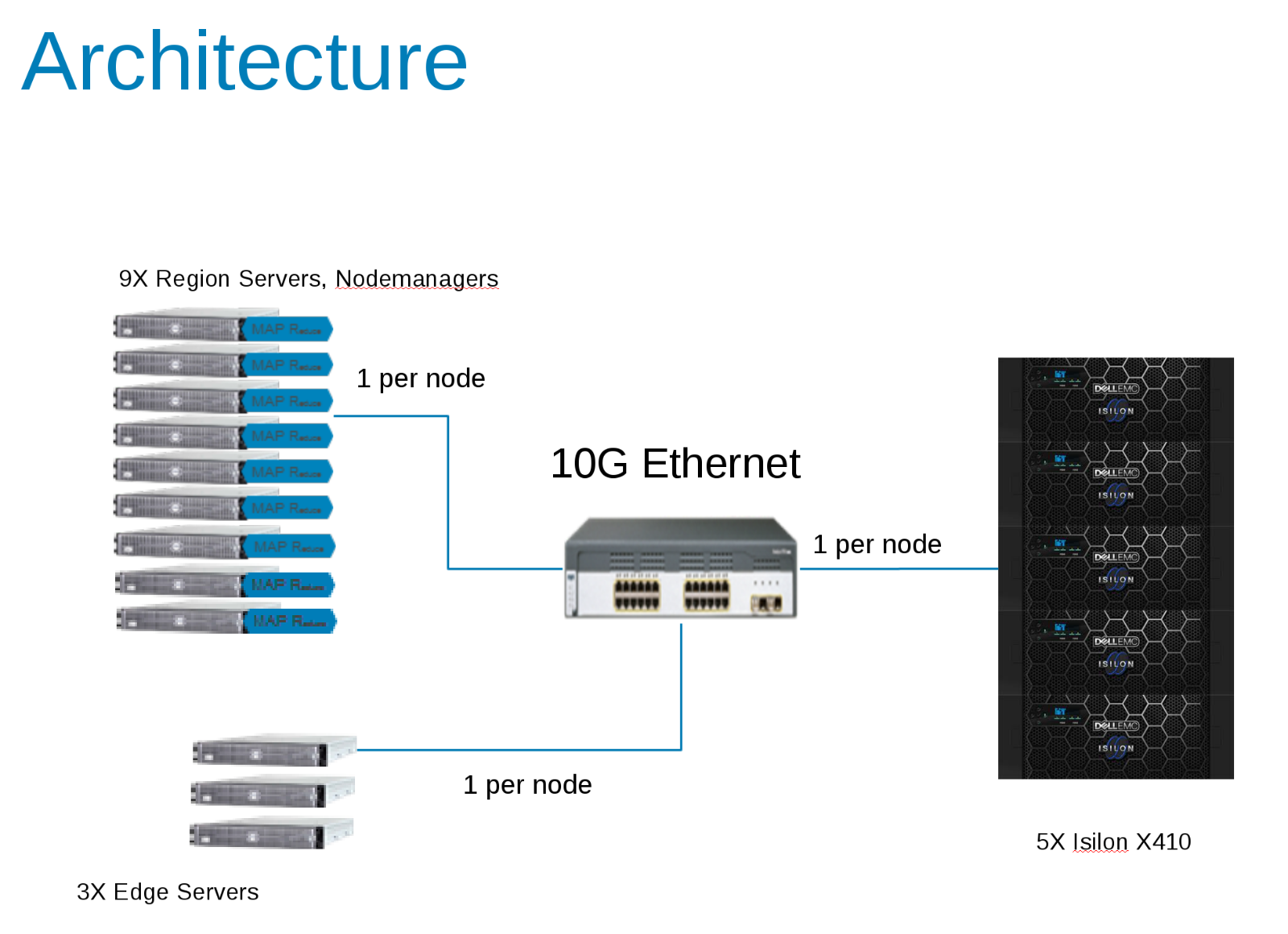
CDH 5.10 a été configuré pour s’exécuter dans une zone d’accès sur le cluster Isilon. Les comptes de service ont été créés dans le fournisseur Isilon Local et localement dans les fichiers clients /etc/passwd. Tous les tests ont été exécutés à l’aide d’un client de test de base sans privilèges particuliers.
Les statistiques Isilon ont été surveillées à l’aide des packages IIQ et Grafana/Data Insights. Les statistiques CDH ont été surveillées avec Cloudera Manager ainsi qu’avec Grafana.
Tests initiaux
La première série de tests visait à déterminer les paramètres pertinents du côté HBASE qui affectaient le rendement global. L’outil YCSB a été utilisé pour générer la charge pour HBASE. Ce test initial a été exécuté à l’aide d’un seul client (serveur de périphérie) à l’aide de la phase de charge de YCSB et de 40 millions de lignes. Cette table a été supprimée avant chaque exécution.
ycsb load hbase10 -P workloads/workloada1 -p table='ycsb_40Mtable_nr' -p columnfamily=family -threads 256 -p recordcount=40000000
- hbase.regionserver.maxlogs : nombre maximal de fichiers WAL (Write-Ahead Log). Cette valeur multipliée par HDFS Block Size (dfs.blocksize) correspond à la taille du WAL qui doit être relue lorsqu’un serveur tombe en panne. Cette valeur est inversement proportionnelle à la fréquence des vidages sur le disque.
- hbase.wal.regiongrouping.numgroups : lors de l’utilisation de plusieurs WAL HDFS en tant que WALProvider, cela définit le nombre de journaux à écriture anticipée que chaque RegionServer doit exécuter. Les résultats indiquent le nombre de pipelines HDFS. Les écritures pour une région donnée ne sont transmises qu’à un seul pipeline, ce qui répartit la charge totale de RegionServer.
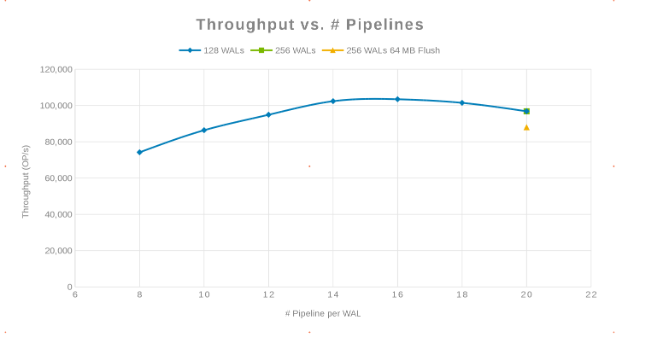
Comparaison du débit avec le nombre de pipelines (Figure 2)
Latence par rapport au nombre de pipelines (Figure 3)
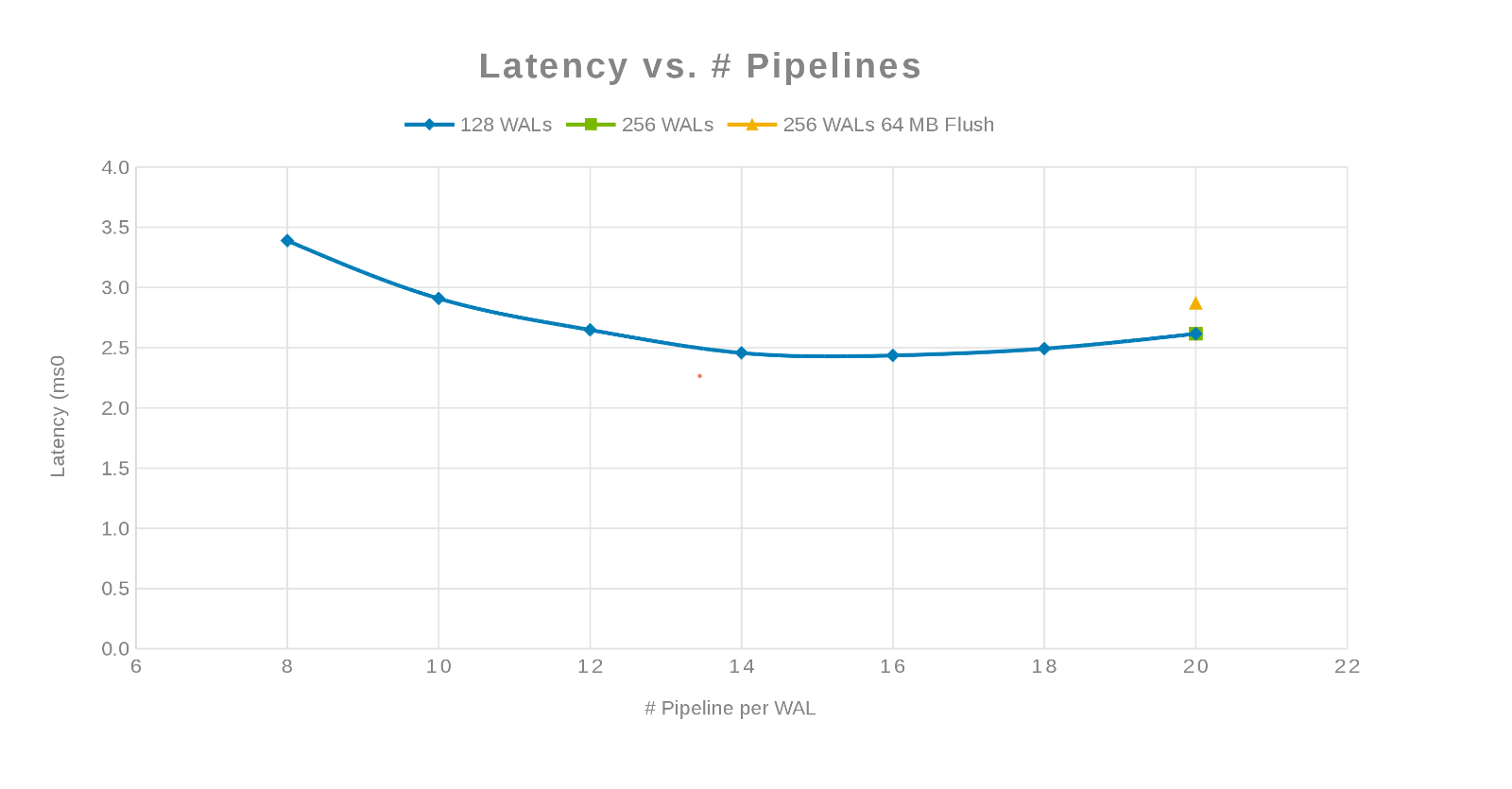
La philosophie ici était de paralléliser autant d’écritures que possible. Pour ce faire, vous devez augmenter le nombre de WAL, puis le nombre de threads (pipeline) par WAL. Les deux graphiques précédents montrent que pour un nombre donné de 'maxlogs', 128 ou 256, aucun changement réel n’est affiché. Cela indique que le test n’a pas vraiment d’impact sur les résultats côté client. Le nombre de « pipelines » par fichier a varié, ce qui montre une tendance indiquant le paramètre sensible à la parallélisation. La question suivante est de savoir où le cluster Isilon « gêne » au niveau des E/S disque, du réseau, du CPU ou de OneFS. Pour répondre à cette question, consultez le rapport statistique Isilon.
Utilisation et charge du réseau Isilon pendant le test (Figure 4)
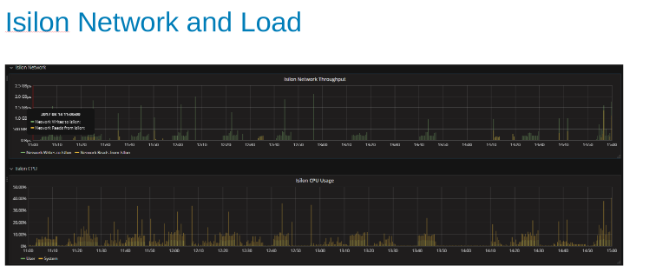
Les graphiques du réseau et du processeur nous indiquent que le cluster Isilon est sous-utilisé et qu’il peut encore du travail. Le processeur serait > de 80 % et la bande passante réseau serait supérieure à 3 Go/s.
Graphiques de la statistique du protocole HDFS et de l’utilisation du processeur lors de la charge du protocole HDFS (Figure 5)
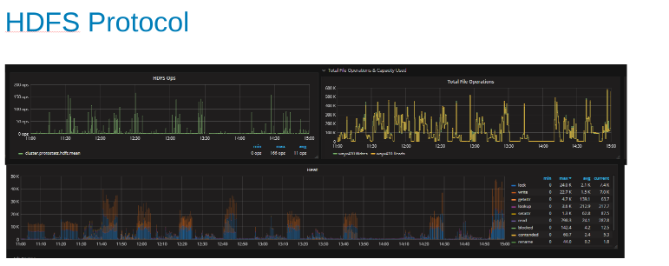
Ces graphiques montrent les statistiques du protocole HDFS et la façon dont OneFS convertit la sortie. Les opérations HDFS sont des multiples de dfs.blocksize, qui est ici de 256 Mo. Ce qui est intéressant ici, c’est que le graphique « Heat » montre les opérations de fichier OneFS et la corrélation des écritures et des verrous est affichée. Dans ce cas, HBase effectue des ajouts au WAL de sorte que OneFS verrouille le fichier WAL pour chaque écriture ajoutée. Ce qui est attendu pour des écritures stables sur un système de fichiers en cluster. Ceux-ci semblent contribuer au facteur limitatif de cette série de tests.
Mises à jour HBase
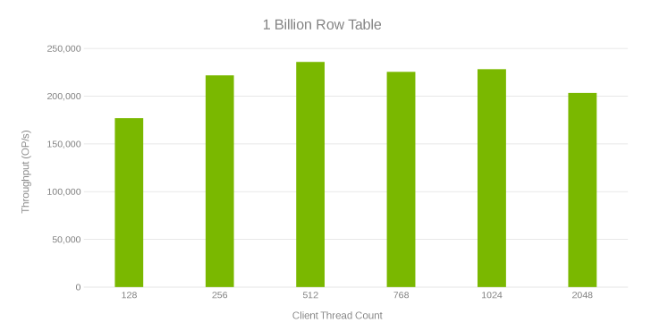
Le test suivant consistait à faire plus d’expériences pour trouver ce qui se passe à grande échelle. Une table de 1 milliard de lignes est créée. La génération a pris une heure. Un test YCSB est exécuté qui a mis à jour 10 millions de lignes à l’aide des paramètres « workloada » (lecture/écriture 50/50). Ce test a été exécuté sur un seul client. Le test s’est exécuté en fonction du nombre de threads YCSB afin que le débit le plus important puisse être généré. En outre, quelques réglages ont été appliqués et OneFS a été mis à niveau vers la version v8.0.1.1, qui comporte des ajustements de performances pour le service de nœud de données. Le graphique suivant montre l’augmentation des performances par rapport à l’ensemble d’exécutions précédent. Pour ces exécutions, hbase.regionserver.maxlogs est défini sur 256 et hbase.wal.regiongrouping.numgroups sur 20.
Débit et nombre de threads lors de la mise à jour d’une table de 1 milliard de lignes (Figure 6)
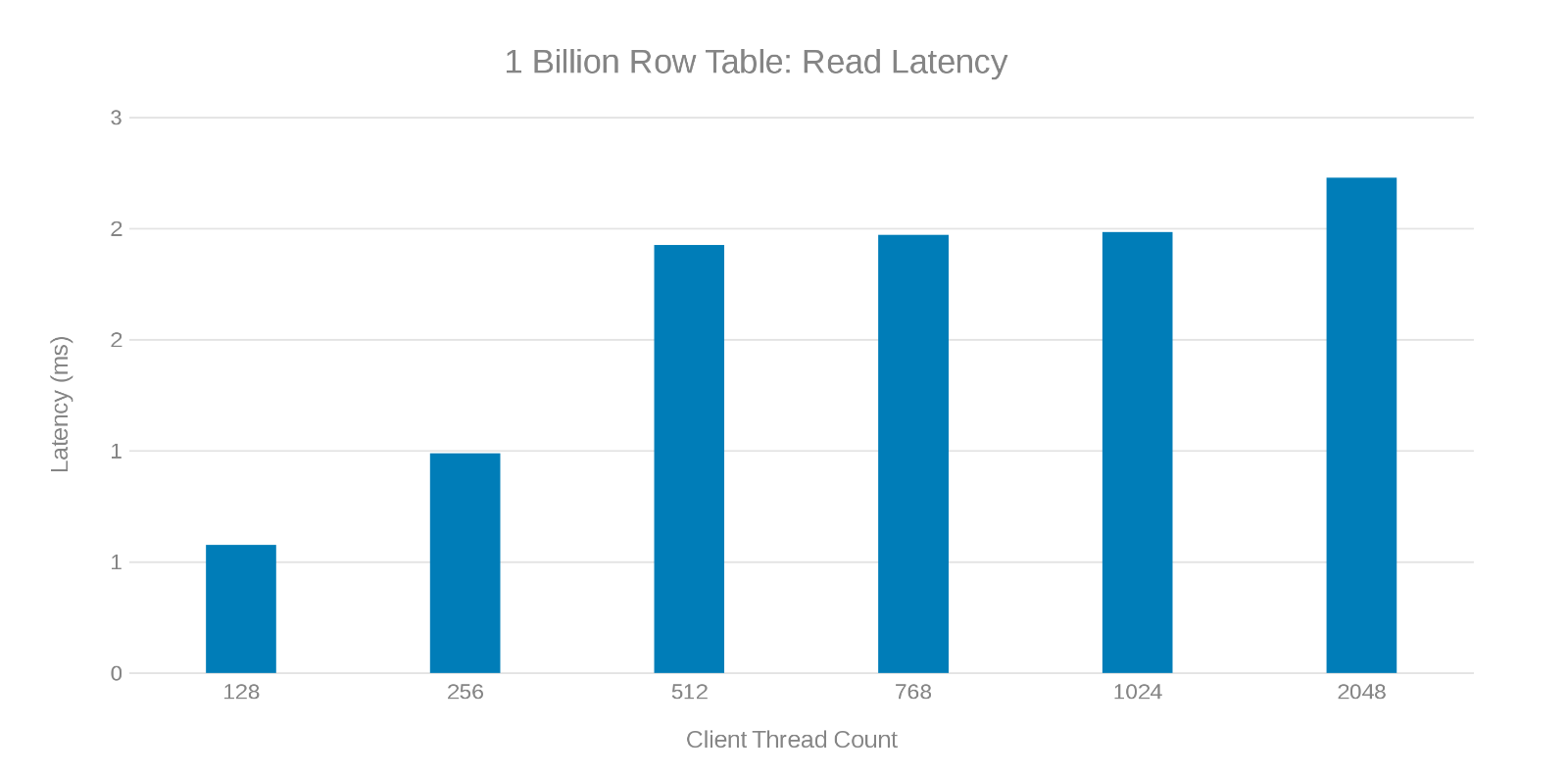
Latence de lecture lors de la mise à jour d’une table de 1 milliard de lignes (Figure 7)
Latence de mise à jour lors de la mise à jour d’une table de 1 milliard de lignes (Figure 8)
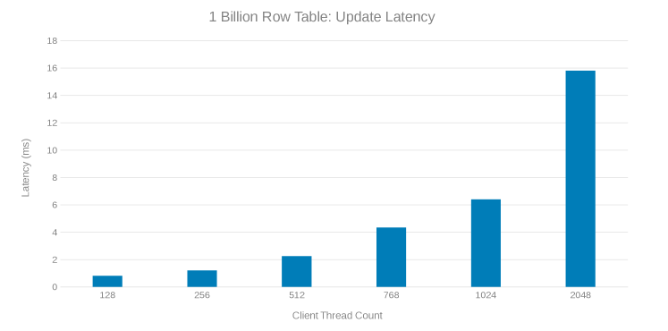
L’examen de ces séries de tests montre une chute apparente à un nombre élevé de threads, ce qui peut être un problème Isilon ou côté client. Les tests montrent et impressionnent 200 000 opérations par seconde à une latence de mise à jour de < 3 ms. Chacune des exécutions de test de mise à jour a été rapide et a pu être exécutée consécutivement. Le graphique ci-dessous montre un équilibre uniforme entre les nœuds Isilon pour chaque série de tests.
Graphique thermique indiquant la charge applicative sur chaque nœud du cluster Isilon (Figure 9)
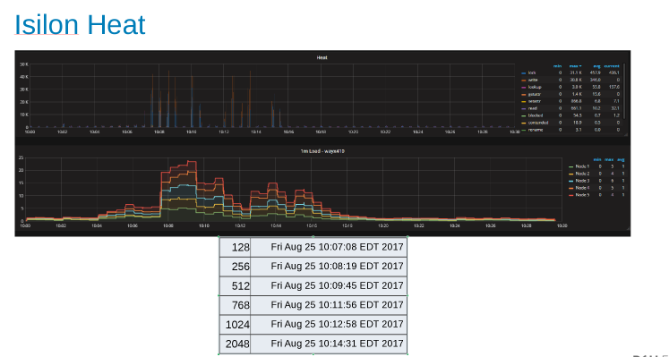
Le graphique Heat montre que les opérations de fichier sont des écritures et des verrous correspondant à la nature d’ajout des processus WAL.
Mise à l’échelle des serveurs de région
Le test suivant consistait à déterminer comment les nœuds Isilon (cinq nœuds) se comporteraient par rapport à un nombre différent de serveurs régionaux. Le même script de mise à jour exécuté dans le test précédent a été exécuté avec une table d’un milliard de lignes et une mise à jour de 10 millions de lignes à l’aide de « workloada ». Le test a utilisé un seul client avec les threads YCSB définis sur 51. Le même paramètre est appliqué pour les maxlogs et les pipelines (256 et 20 respectivement).
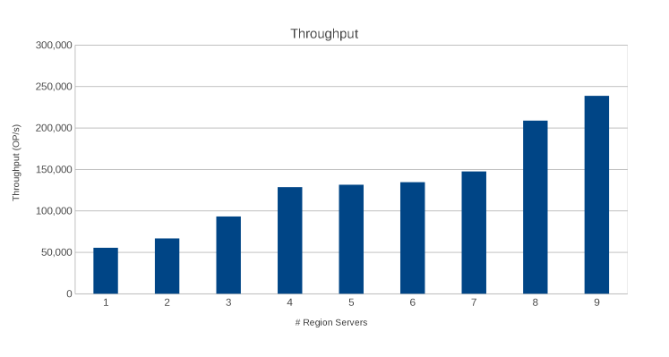
Débit sur les serveurs de la région (Figure 10)
Latence entre les serveurs régionaux (Figure 11)
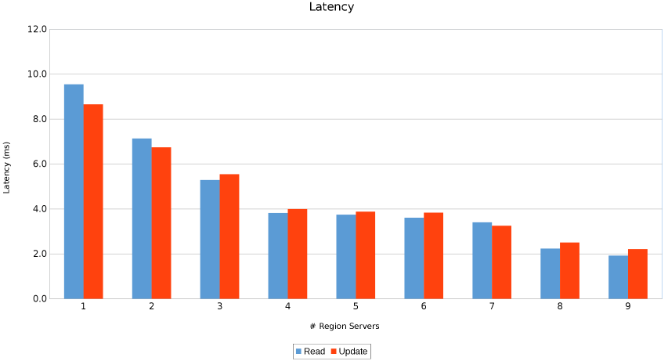
Les résultats sont instructifs, bien qu’ils ne soient pas surprenants. La nature scale-out de HBase, associée à la nature scale-out d’Isilon, indique que plus il y en a, mieux c’est. Il est recommandé aux clients d’exécuter ce test dans leur environnement dans le cadre de leur propre exercice de dimensionnement. Ici, il y a neuf serveurs qui poussent cinq nœuds Isilon et il semble qu’il y ait encore de la place pour plus avant d’atteindre le point de rendements décroissants.
Plus de clients
La dernière série de tests a permis de tester les limites de la configuration matérielle. Cela a été fait pour déterminer la limite supérieure des paramètres testés. Dans cette série de tests, deux serveurs supplémentaires sont utilisés pour exécuter les clients. En outre, deux clients YCSB sont exécutés à partir de chaque serveur, ce qui permet d’obtenir jusqu’à six clients chacun. Chaque client a piloté 512 threads, soit 4 096 threads au total. Deux tables différentes ont été créées. Un tableau avec 4 milliards de lignes divisé en 600 régions et un autre avec 400 millions de lignes divisées en 90 régions.
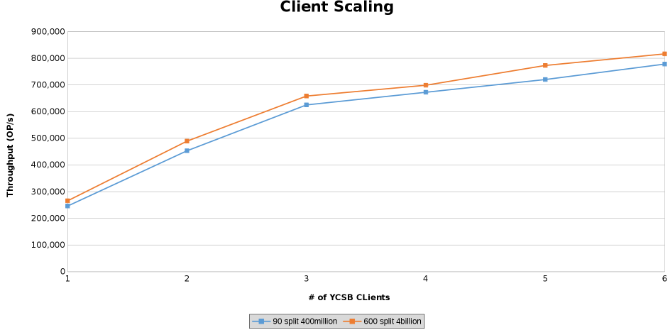
Ce graphique représente le débit des opérations lors des tests de mise à l’échelle des clients (Figure 12).
Mesure de la latence de lecture lors du test de la mise à l’échelle du client (Figure 13)
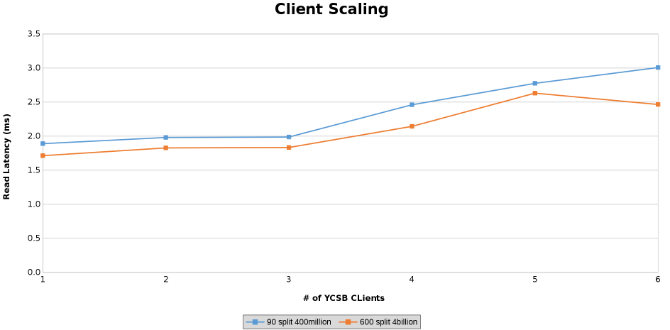
Mesure de la latence de mise à jour lors du test de la mise à l’échelle du client (Figure 14)
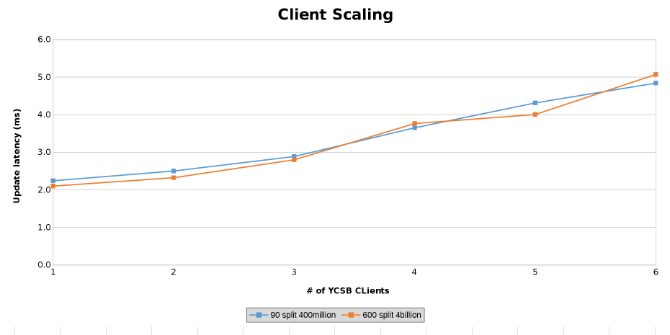
Les graphiques ci-dessous montrent que la taille du tableau importe peu dans ce test. Les graphiques Isilon Heat montrent à nouveau qu’il existe une différence de quelques pourcentages dans le nombre d’opérations de fichiers. La plupart des différences correspondaient aux différences entre une table de quatre milliards de lignes et une table de 400 millions de lignes.
Comparaison de la chaleur de la charge applicative Isilon lors de la mise à jour d’une table de 400 millions de lignes par rapport à une table de 4 milliards de lignes (Figure 15).
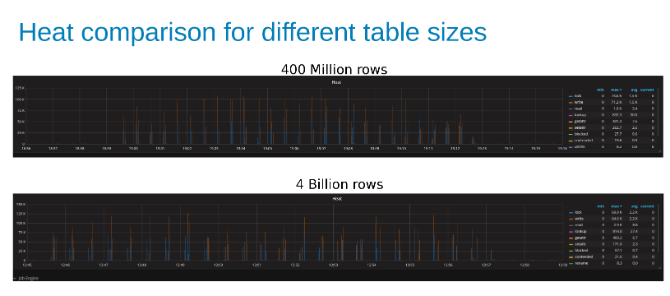
Conclusion
HBase est un bon candidat pour une exécution sur Isilon, principalement en raison de son caractère scale-out pour les architectures scale-out. HBase effectue une grande partie de sa propre mise en cache et, en répartissant la table sur un bon nombre de régions, HBase peut évoluer avec les données. En d’autres termes, il répond bien à ses propres besoins, et le système de fichiers est là pour la résilience des applications. Les tests n’ont pas été en mesure de pousser la charge au point de casser des choses. Si la HBase est conçue pour 800 000 opérations avec moins de 3 ms de latence, cette architecture la prend en charge. HBase prend en charge une multitude d’ajustements et d’ajustements de performances pour le côté client et HBase lui-même. La mise à l’essai de tous ces ajustements et ajustements dépassait le cadre de ce test.対象製品
Isilon, PowerScale OneFS文書のプロパティ
文書番号: 000128942
文書の種類: Solution
最終更新: 11 3月 2026
バージョン: 7
質問に対する他のDellユーザーからの回答を見つける
サポート サービス
お使いのデバイスがサポート サービスの対象かどうかを確認してください。