PowerScale, Isilon OneFS: Prestandatest av HBase på Isilon
Summary: I den här artikeln beskrivs prestandatesterna på ett Isilon X410-kluster med sviten Yahoo Cloud Serving Benchmarking (YCSB) och Cloudera Data Hub (CDH) 5.10.
This article applies to
This article does not apply to
This article is not tied to any specific product.
Not all product versions are identified in this article.
Symptoms
Krävs inte
Cause
Krävs inte
Resolution
Obs! Det här avsnittet är en del av Använda Hadoop med OneFS Info Hub.
Introduktion
En serie prestandatester utfördes på ett Isilon X410-kluster med YCSB-benchmarking suite och CDH 5.10.
Labbtestmiljön konfigurerades med fem Isilon x410-noder som körde OneFS v8.0.0.4 och senare v8.0.1.1. Prestandatest för NFS (Network File System) Large Block Streaming kördes. Det förväntade teoretiska aggregatet maximalt för testerna var ~700 MB/s (3,5 GB/s) skrivningar och ~1 GB/s läsningar (5 GB/s) per nod.
Beräkningsnoderna (9) är Dell PowerEdge FC630-servrar som kör CentOS v7.3.1611, var och en konfigurerad med 2x18C/36T-Intel Xeon® CPU E5-2697 v4 @ 2,30 GHz med 512 GB RAM. Lokal lagring är 2 × SSD i RAID 1-format som XFS för både operativsystem och virtuellt lagringsutrymme eller spill-filer.
Det fanns också ytterligare tre Edge-servrar som användes för att driva YCSB-belastningen.
Backend-nätverket mellan beräkningsnoder och Isilon är 10 Gbit/s med jumboramar inställda (MTU=9162) för nätverkskorten och switchportarna.
Komponenterna i Hadoop-testkonfigurationen (bild 1)
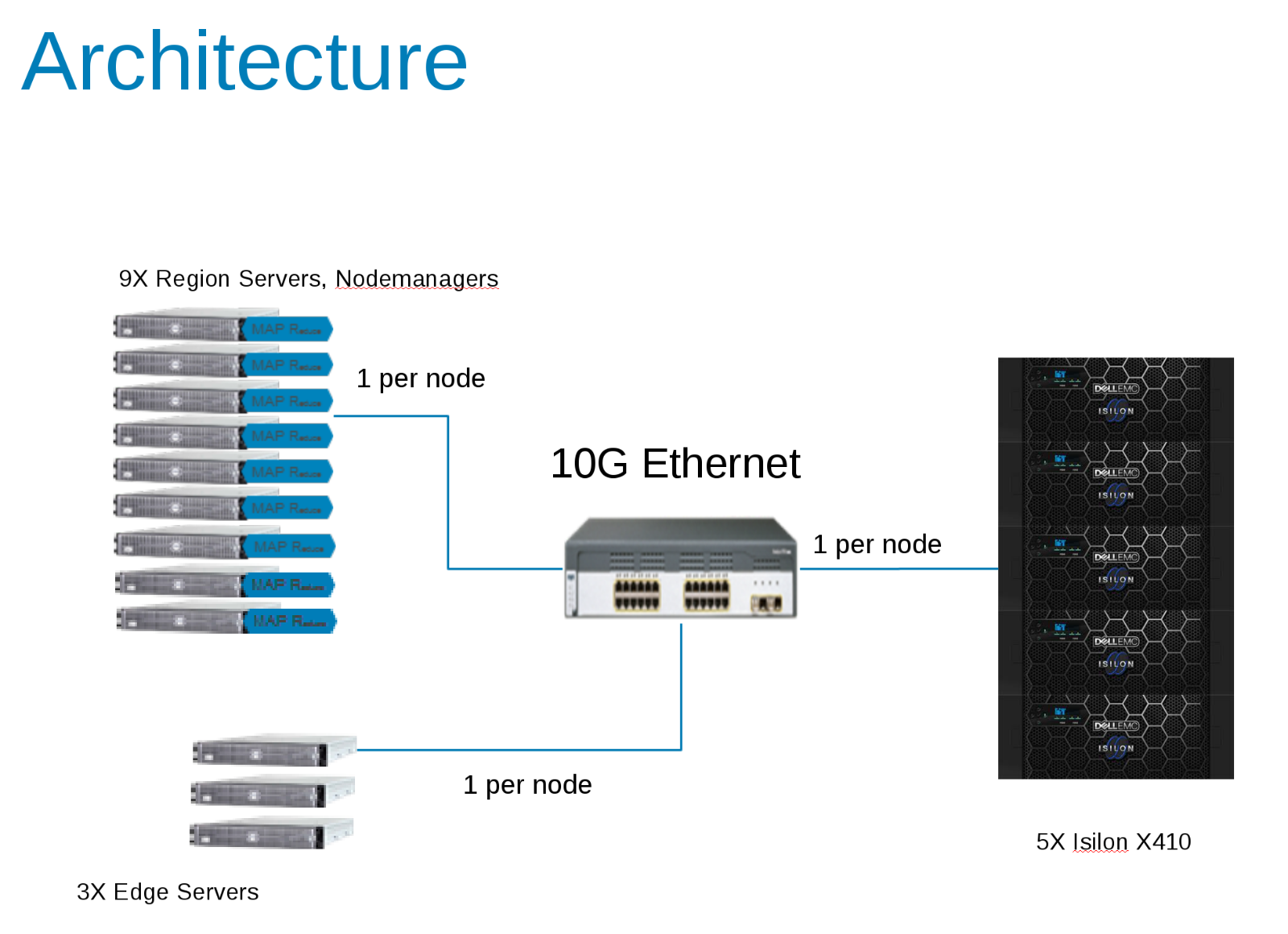
CDH 5.10 konfigurerades för att köras i en åtkomstzon på Isilon Cluster. Tjänstkonton skapades i den lokala Isilon-providern och lokalt i klientens /etc/passwd-filer. Alla tester kördes med en grundläggande testklient utan särskilda privilegier.
Isilon-statistik övervakades med både IIQ och Grafana/Data Insights-paketet. CDH-statistik övervakades med Cloudera Manager och även med Grafana.
Inledande testning
Den första serien av tester var att bestämma de relevanta parametrarna på HBASE-sidan som påverkade den totala produktionen. YCSB-verktyget användes för att generera belastningen för HBASE. Det här första testet kördes med en enda klient (edge-server) med hjälp av "load"-fasen i YCSB och 40 miljoner rader. Den här tabellen togs bort före varje körning.
ycsb load hbase10 -P workloads/workloada1 -p table='ycsb_40Mtable_nr' -p columnfamily=family -threads 256 -p recordcount=40000000
- hbase.regionserver.maxlogs – Maximalt antal WAL-filer (Write-Ahead Log) – Det här värdet multiplicerat med HDFS-blockstorleken (dfs.blocksize) är storleken på WAL som måste spelas upp igen när en server kraschar. Det här värdet är omvänt proportionellt mot tömningsfrekvensen till disken.
- hbase.wal.regiongrouping.numgroups – När du använder flera HDFS WAL som WALProvider anger detta hur många write-ahead-logs varje RegionServer ska köra. Resultatet visar antalet HDFS-pipelines. Skrivningar för en viss region går bara till en enda pipeline, vilket sprider den totala RegionServer-belastningen.
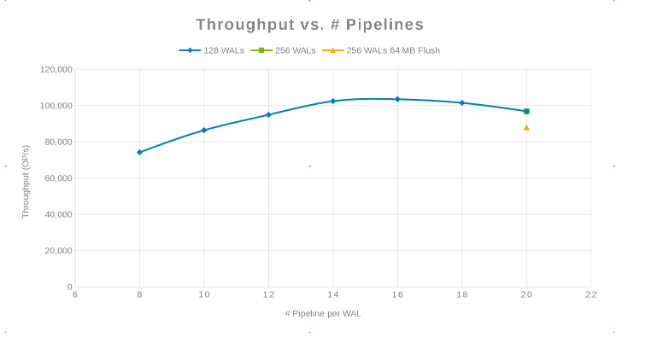
Dataflöde jämfört med antalet pipelines (bild 2)
Svarstid jämfört med antalet pipelines (bild 3)
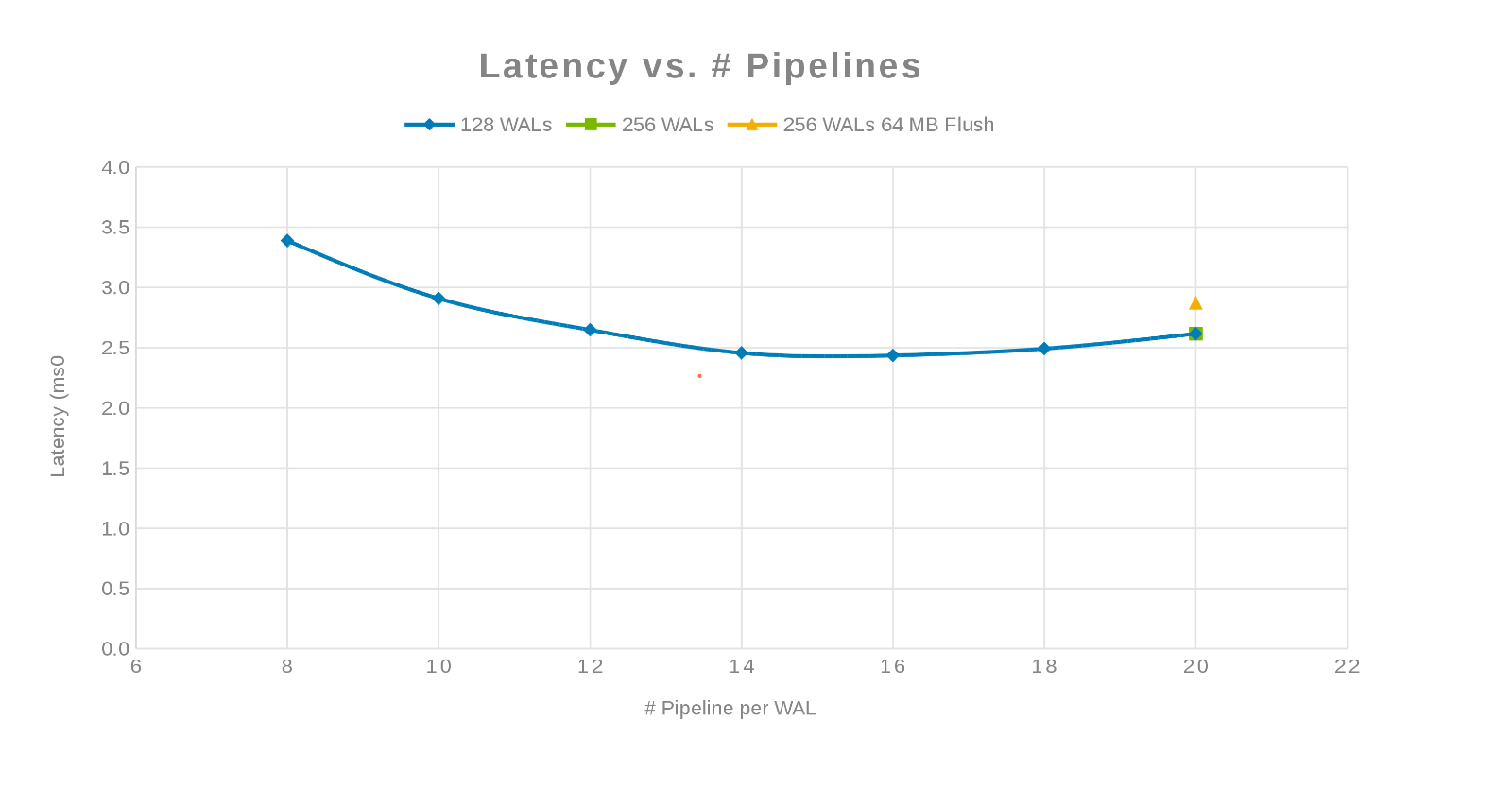
Filosofin här var att parallellisera så många skrivningar som möjligt. Genom att öka antalet WAL och sedan antalet trådar (pipeline) per WAL åstadkoms detta. De föregående två diagrammen visar att för ett givet tal för "maxlogs", 128 eller 256, visas ingen verklig förändring. Detta indikerar att testet egentligen inte påverkar resultaten från klientsidan. Antalet "pipelines" per fil varierade, vilket visade en trend som anger vilken parameter som är känslig för parallellisering. Nästa fråga är var Isilon-klustret "kommer i vägen" med antingen disk-I/O, nätverk, CPU eller OneFS. För att få svar på den frågan kan du titta i Isilon-statistikrapporten.
Isilon-nätverkets användning och belastning under testet (bild 4)
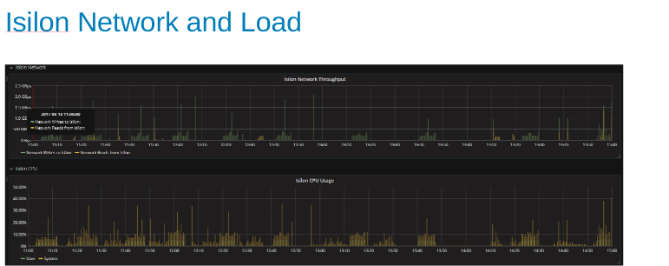
Nätverks- och processordiagrammen visar att Isilon-klustret är underutnyttjat och har utrymme för mer arbete. CPU skulle vara > 80 % och nätverksbandbredden skulle vara mer än 3 GB/s.
Diagram över HDFS-protokollstatistik och CPU-användning under HDFS-protokollbelastning (bild 5)
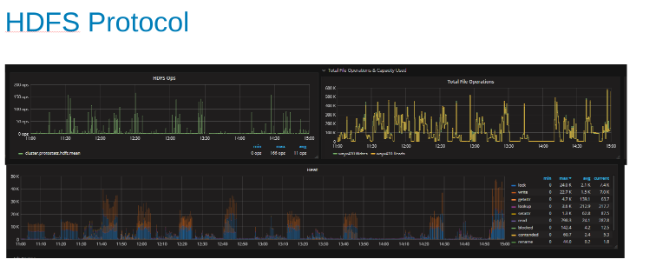
Dessa diagram visar HDFS-protokollstatistiken och hur OneFS översätter utdata. HDFS-åtgärderna är multiplar av dfs.blocksize som är 256 MB här. Det intressanta här är att grafen "Heat" visar OneFS-filåtgärderna och korrelationen mellan skrivningar och lås visas. I det här fallet gör HBase tillägg till WAL:erna så OneFS låser WAL-filen för varje skrivning som läggs till. Vilket är vad som förväntas för stabila skrivningar i ett klustrat filsystem. Dessa verkar bidra till den begränsande faktorn i denna uppsättning tester.
HBase-uppdateringar
Nästa test var att experimentera mer för att ta reda på vad som händer i stor skala. En tabell på 1 miljard rader skapas, vilket tog en timme att generera. Ett YCSB-test körs som uppdaterar 10 miljoner av raderna med hjälp av "workloada"-inställningarna (50/50 läs/skrivning). Det här testet kördes på en enda klient. Testet kördes som en funktion av antalet YCSB-trådar så att mest dataflöde kan genereras. Dessutom tillämpades viss finjustering och OneFS uppgraderades till v8.0.1.1 som har prestandajusteringar för datanodtjänsten. I följande diagram visas uppgången i prestanda jämfört med föregående uppsättning körningar. För dessa körningar är hbase.regionserver.maxlogs inställt på 256 och hbase.wal.regiongrouping.numgroups till 20.
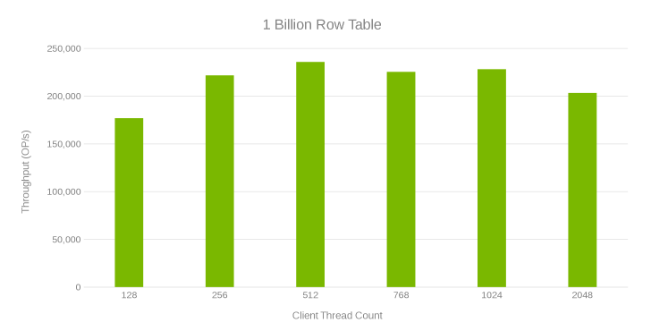
Dataflöde och antal trådar vid uppdatering av tabell med 1 miljard rader (bild 6)
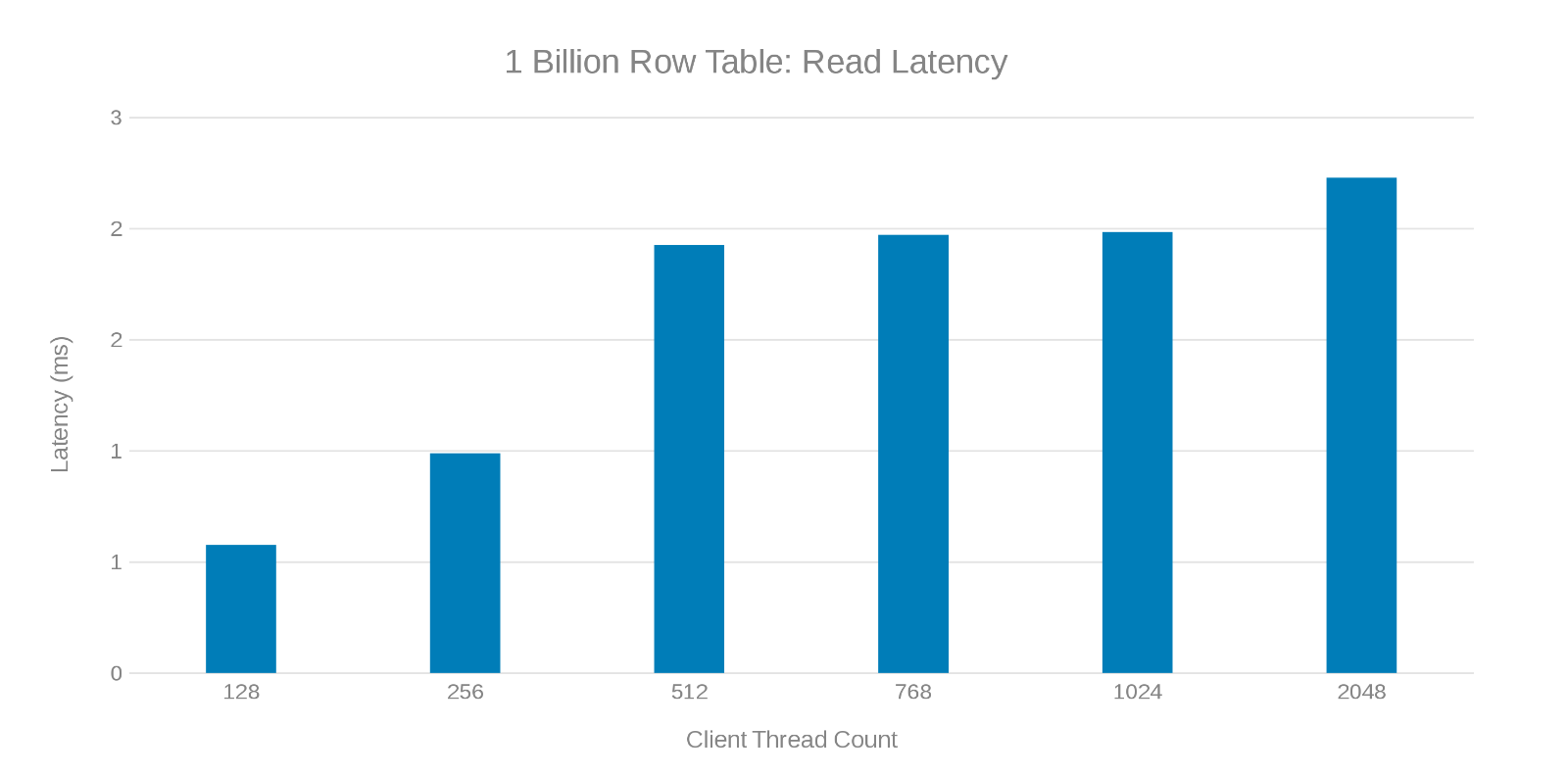
Lässvarstid vid uppdatering av tabell med 1 miljard rader (bild 7)
Uppdatera svarstiden vid uppdatering av tabellen med 1 miljard rader (bild 8)
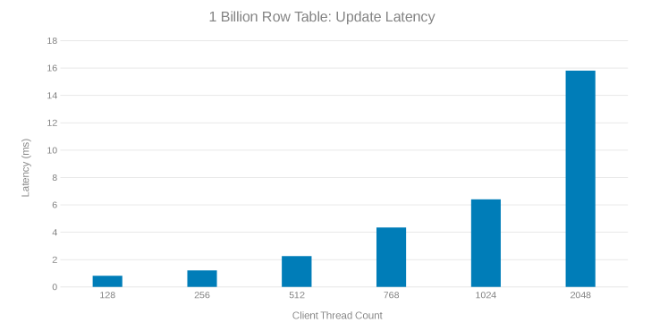
Granskning av dessa testkörningar visar en uppenbar minskning vid högt trådantal, vilket kan vara antingen ett problem på Isilon eller klientsidan. Tester visar och imponerar på 200 tusen åtgärder per sekund med en uppdateringslatens på < 3 ms. Var och en av uppdateringstestkörningarna var snabba och kunde köras i följd. Diagrammet nedan visar en jämn balans mellan Isilon-noderna för varje testkörning.
Värmediagram som visar arbetsbelastningen över varje nod i Isilon Cluster (bild 9)
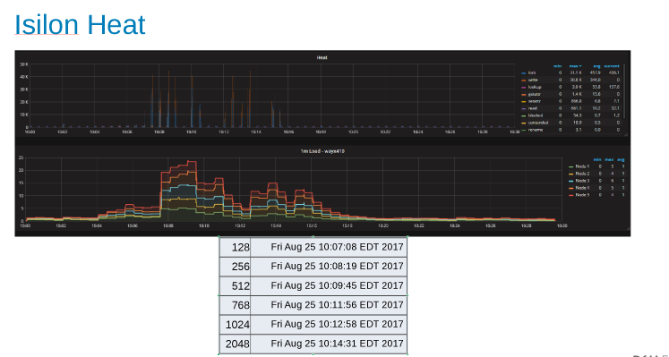
Värmediagrammet visar att filåtgärderna är skrivningar och lås som motsvarar WAL-processernas tilläggsnatur.
Skalning av regionserver
Nästa test var att fastställa hur Isilon-noderna (fem noder) skulle klara sig mot olika antal regionservrar. Samma uppdateringsskript som kördes i det tidigare testet kördes med en tabell på en miljard rader och en uppdatering på 10 miljoner rader med hjälp av "workloada". Testet använde en enda klient med YCSB-trådar inställda på 51. Samma inställning för maxlogs och pipelines tillämpas (256 respektive 20).
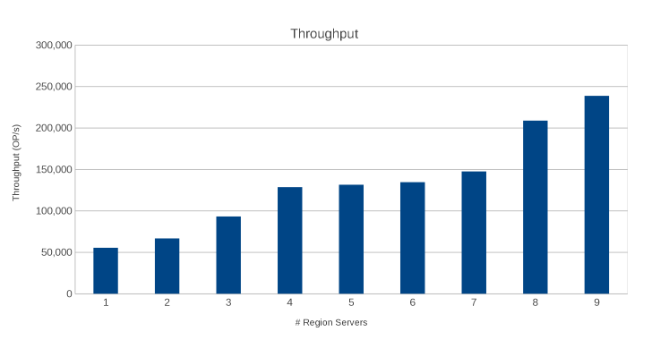
Dataflöde mellan regionservrar (bild 10)
Latens mellan regionservrar (bild 11)
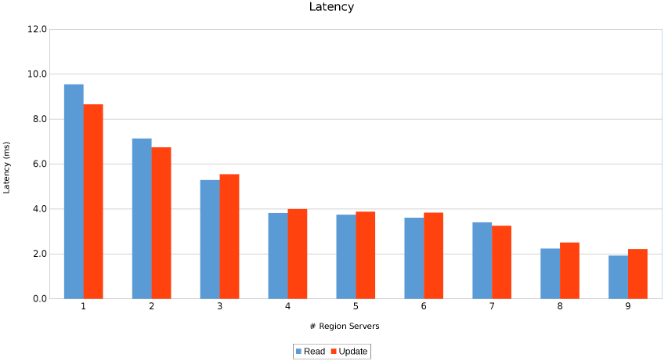
Resultaten är informativa, om än inte överraskande. HBases utskalning i kombination med Isilons utskalning indikerade att mer är bättre. Det här testet rekommenderas för klienter att köra i sina miljöer som en del av sin egen storleksövning. Här finns det nio servrar som trycker på fem Isilon-noder och det ser ut som att det fortfarande finns utrymme för fler innan avkastningen minskar.
Fler kunder
Den senaste serien tester tjänade till att testa gränserna för hårdvarukonfigurationen. Detta gjordes för att fastställa den övre gränsen för de parametrar som testades. I den här testserien används ytterligare två servrar för att köra klienter från. Dessutom körs två YCSB-klienter från varje server, vilket tillåter upp till sex klienter vardera. Varje klient körde 512 trådar, vilket resulterade i 4096 trådar totalt. Två olika tabeller skapades. En tabell med 4 miljarder rader uppdelade i 600 regioner och en annan med 400 miljoner rader uppdelade i 90 regioner.
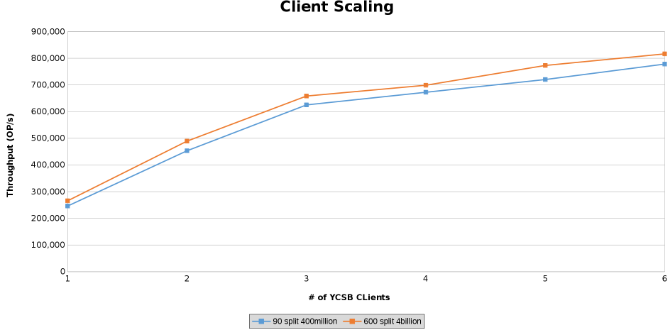
Detta visar dataflödet för åtgärder vid testning av klientskalning (bild 12).
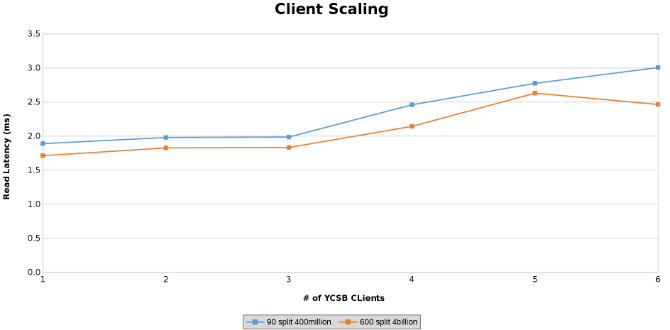
Mätning av läslatens under testning av klientskalning (bild 13)
Mätning av uppdateringslatens under testning av klientskalning (bild 14)
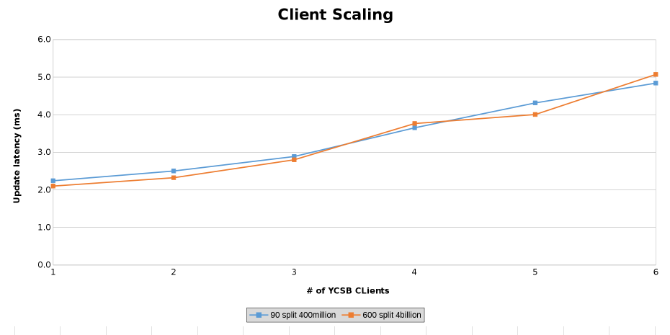
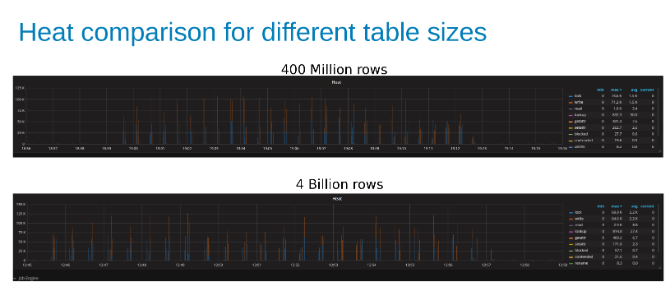
Graferna nedan visar att storleken på tabellen spelar liten roll i det här testet. Isilon Heat-diagrammen visar återigen att det är några procentuella skillnader i antalet filåtgärder. De flesta skillnaderna var i linje med skillnaderna mellan en tabell med fyra miljarder rader och en tabell med 400 miljoner rader.
Jämförelse av Isilon-arbetsbelastningens värme vid uppdatering av en tabell med 400 miljoner rader jämfört med en tabell med 4 miljarder rader (bild 15).
Slutsats
HBase är ett bra alternativ för att köras på Isilon, främst på grund av utskalningsarkitekturer. HBase gör mycket av sin egen cachelagring och genom att dela upp tabellen över ett stort antal regioner kan HBase skala ut med data. Med andra ord gör den ett bra jobb med att ta hand om sina egna behov, och filsystemet finns där för applikationsmotståndskraft. Testningen kunde inte pressa belastningen till den grad att saker gick sönder. Om HBase är utformat för 800 000 åtgärder med mindre än 3 ms svarstid stöder den här arkitekturen det. HBase stöder en mängd prestandajusteringar och justeringar för både klientsidan och själva HBase. Testning av alla dessa justeringar och justeringar låg utanför ramen för detta test.Affected Products
Isilon, PowerScale OneFSArticle Properties
Article Number: 000128942
Article Type: Solution
Last Modified: 11 Mar 2026
Version: 7
Find answers to your questions from other Dell users
Support Services
Check if your device is covered by Support Services.