

As GenAI is busy revolutionizing business operations, its reliance on huge compute power and GPUs for customization, training, and inference is growing. Today’s appetite for AI operations demands robust storage and a scalable architecture to allow for an ever-growing number of concurrent connections.
Dell Technologies and NVIDIA have partnered to provide an integrated solution, combining leading AI platforms, scale-out file systems and award-winning servers to meet today’s increasingly demanding AI workflows.
Let’s take a look at how GenAI benefits from a solution that combines PowerScale storage, PowerEdge servers and PowerSwitch networking, along with NVIDIA AI Enterprise and NEMO.
An Optimized Architecture for Performance, Concurrency and Scale
Dell’s PowerScale architecture is a leading scale-out NAS platform, clustering up to 252 nodes into a single storage system, designed to accelerate AI model training and inferencing across on-premises, edge and cloud environments. Its all-flash platform uses OneFS and NVMe disks, enabling full cluster capacity and performance through a single namespace, supporting extreme concurrency and low-latency data transfers.
By offering scalable storage, PowerScale allows businesses to expand on-demand. Clusters can grow to 186PB of capacity and over 2.5TB read/write throughput within a single namespace. This ensures robust AI workflow support.
Optimized for high concurrent IO during AI training, PowerScale supports NFSoRDMA and NVIDIA’s GPU Direct Storage (GDS) for low-latency data transfers. PowerScale OneFS also supports RDMA over converged Ethernet (RoCEv2), bypassing CPU and OS to enhance data transfer efficiency, combined with MagnumIO for efficient data movement between NVIDIA GPU memory and PowerScale storage to drive AI innovations faster.
The PowerEdge XE9680 server, equipped with eight NVIDIA H100 GPUs and NVIDIA AI software, is designed for high throughput and scalability. It features enhanced performance and networking via NVIDIA ConnectX-7 SmartNICs, supporting advanced applications like NLP. The NVIDIA H100 GPU, with NVLink Switch System, accelerates AI workloads with a dedicated Transformer Engine, delivering 30 times faster LLMs.
Testing PowerEdge for AI Training Workloads
To assess the GPU performance and storage scalability of this architecture, we trained a popular LLM — using two different configurations on a LLAMA 2 model architecture: One 7B parameter model with a single PowerEdge XE9680 server equipped with 8 NVIDIA H100 GPUs, and a 70B parameter model with six PowerEdge XE9680 servers equipped with 48 NVIDIA H100 GPUs.
Using these readily available LLAMA 2 model sizes for consumption, this assessment would help us better understand the infrastructure resource usage and requirements for various training workloads.
Both configurations included NVIDIA AI Enterprise. This software layer of the NVIDIA AI platform is central to the solution design and accelerates the data science pipeline and streamlines AI development and deployment. This secure, cloud-native platform includes over 100 frameworks, pre-trained models and tools for data processing, model training, optimization and deployment.
The initial data load for both model examples had minimal performance impact on the storage, as language- and text-based models have smaller datasets. This results in low read activity on the file system. Checkpoint data, however, is more impactful. The 70B parameter model required significantly more write throughput than the 7B parameter model during checkpoint operations, affecting the OneFS file system.
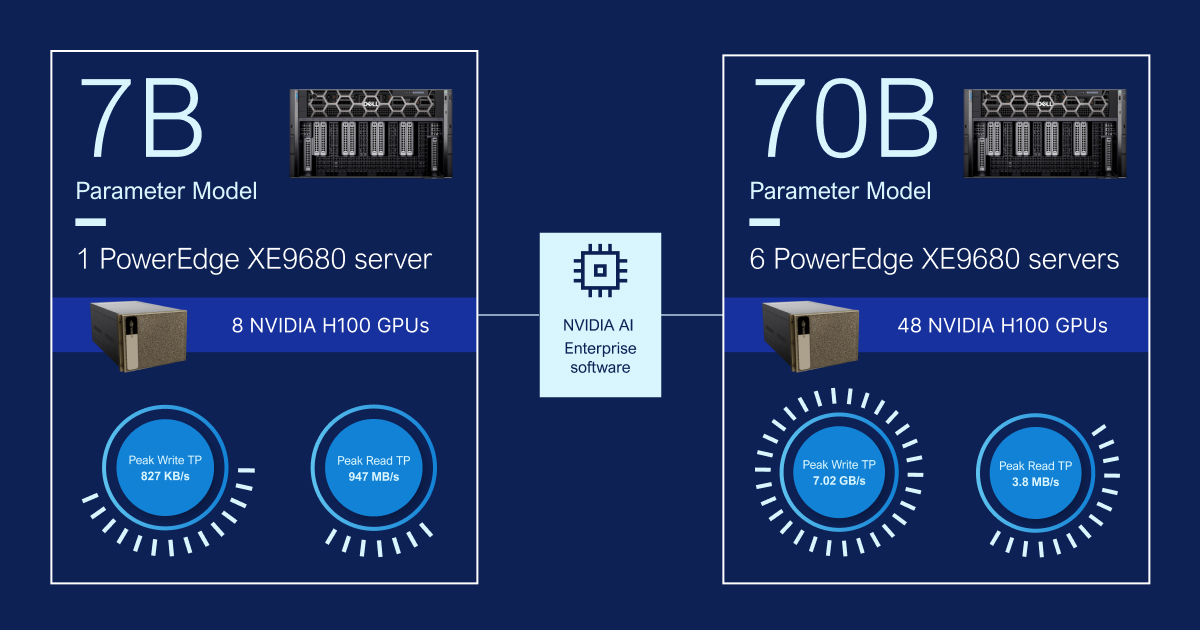
Benchmark results depend on workload, application requirements and system design. Relative performance will vary, so this workload should not replace specific customer application benchmarks for critical capacity planning or product evaluation. For Dell PowerEdge server benchmarking, refer to the MLPerf benchmarking page.
Testing PowerScale for Image Model Training
This validation aimed to understand storage performance changes when training an image dataset. Two configurations were assessed: one with two 8-way servers powered by 16xH100 GPUs in a four-node PowerScale F600P cluster, and another with the same server setup in an eight-node PowerScale F600P cluster We used a ResNet-50 model architecture, a standard benchmark for image classification on storage and GPU compute platforms.
The validation setup was designed to measure the Dell PowerScale file system impact during training operations and examine the change in file system performance and training performance, after adding PowerScale nodes.
When the PowerScale cluster scales from 4 to 8 nodes, there is a 41% reduction in CPU cycles and a 50% reduction in NFS ops across the cluster nodes. The training performance remains consistent for both images/sec per GPU (approx. 5,370) and GPU utilization (99%).
Proven Performance and Scalability for GenAI Workloads
The Dell Reference Design for Generative AI Model Training with PowerScale offers a scalable, high-performance architecture for training LLMs. It leverages NVIDIA AI Enterprise and NVIDIA NeMo to streamline GenAI model development and training — supported by robust Dell infrastructure.
Validation with LLAMA 2 model architecture provides reliable, flexible solutions for GenAI training, addressing network architecture, software design and storage performance. This design serves as a guide for understanding storage requirements and performance impacts, based on model and data set differences during training phases, making it adaptable for many different enterprise use cases.
To find out more, explore the full system configuration details and results here, and the GenAI model training design.
