If you’re in enterprise tech, then you know that the pace of digital transformation is driving technologies, architectures, and solutions to new heights. There is enough new “stuff” going on to make your head spin. All these changes are driving the industry toward revolutionary architectures as the evolutionary past is simply not keeping up. In this blog, I hope to explain the challenges that are driving the industry toward a Memory Centric Architecture (MCA).
Market Dynamics
The industry’s current evolutionary journey is not providing the necessary technology to tackle big challenges ahead – we are swimming in data, billions of IoT devices are coming on line, with machine learning and cognitive computing finding their ways into business results.
At the same time businesses are learning that data has an intrinsic time-based value – meaning that the value of the insights gained from the data quickly declines. Take your time on a web retailer: taking too long to piece together who you are, what you like, where you live, who your friends are, what you bought last time, and what your friends bought can result in a missed opportunity for a directed product marketing advertisement leading to a purchase versus an empty shopping cart and ultimately you moving on to a new website.
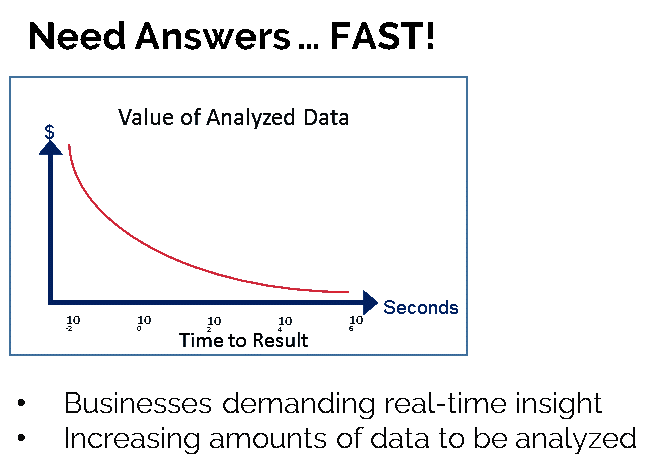
At the technology level, the systems we are building through continued evolution are not advancing fast enough to keep up with these new workloads and use cases. The reality is that the machines we have today were architected five years ago, and ML/DL/AI uses in business are just coming to light, so the industry missed a need. Most of the problems above need a balance between data access and computational horsepower. But the data access is unstructured and data is movement intensive versus computational intensive – simple operators versus complex operators – one taxes memory and the other the CPU.
Below is a historical view of standard 2-socket servers the industry has been building since 2003 (per core view):
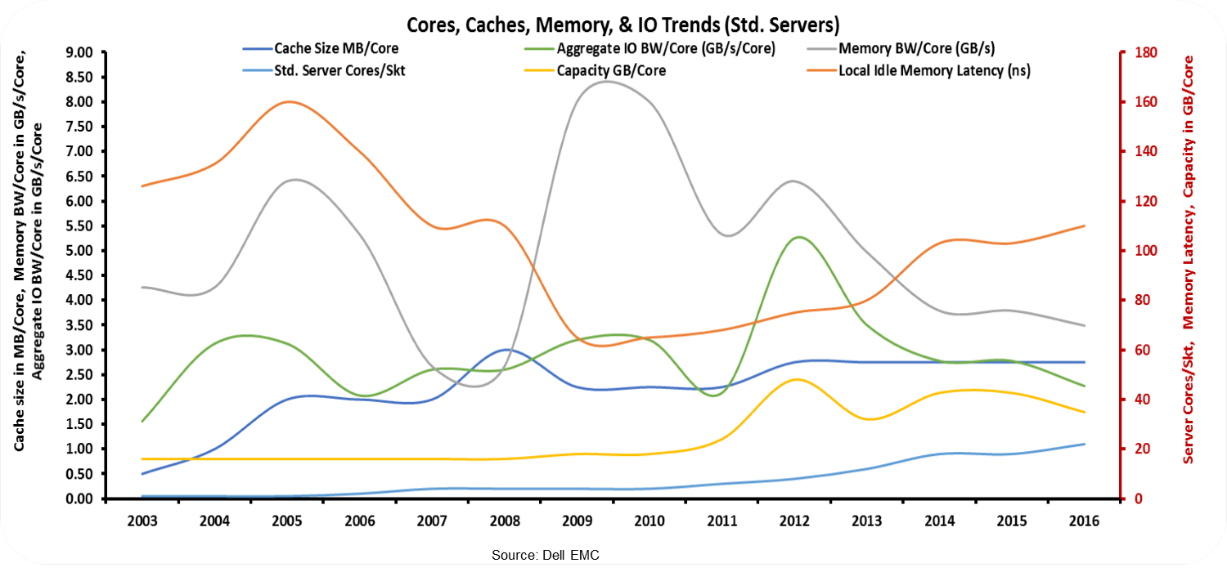
While there won’t be a test at the end, the key points you should take away are:
- Core counts continue to rise (that’s good – Moore’s Law is ok)
- Memory Capacity per Core is flat (Moore’s Law for DRAM is kind of keeping up)
- IO bandwidth per core has been on a downward trend over the last five years (and PCIe Gen4 is a ways out)
- Memory bandwidth per core has been shrinking for the last seven years (nothing new over the horizon at present – just more channels and pins)
- Memory latency per core has been rising over the last eight years (not good considering time value of data)
The other challenge facing the industry is performance gains delivered by Moore’s Law. Remember, Moore’s Law is about transistor per unit area doubling rate, not performance. It just so happens in years past the two were on the same path. With the advent of multicore the rate of performance gains has dropped from 52%/year to 22%/year according to “Computer Architecture, A Quantitative Approach by Hennessy and Patterson” –the de facto standard for Computer Engineering textbooks. But still, 22% is quite good – we keep getting more cores and the cores themselves keep getting slightly better. However, the systems they are attached to (memory & IO) are not keeping up.
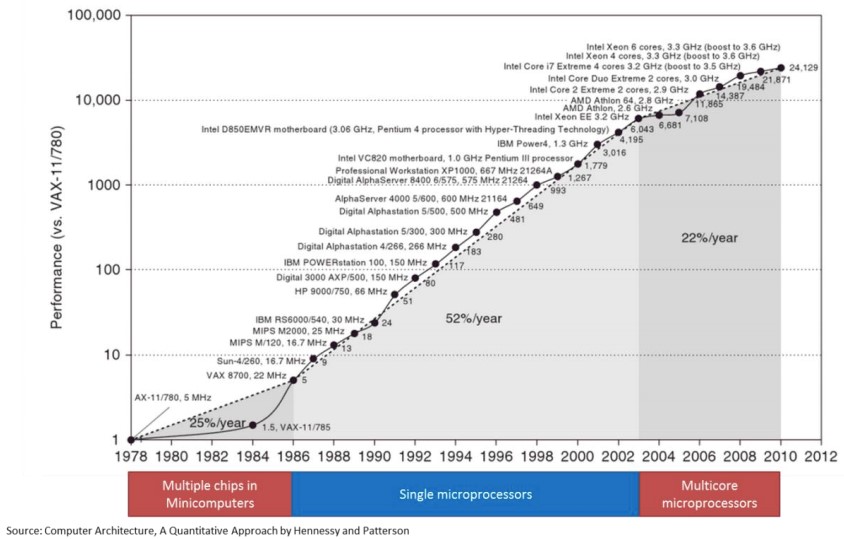
Hence you see the industry trying to adopt all kinds of acceleration technology optimized for these new workloads, and to compensate for reduced performance CAGR. System designers are now challenged on how to add GPUs, FPGA, Smart NIC, Smart Memory, machine learning ASICs and so forth into systems that were not optimized for them.
So we have a system out of balance on the memory front, and the computational performance CAGR rate has fallen off at the same time all these new use cases for big data, machine learning, cognitive computing, IoT, and advanced analytics are on the rise. Add composability, rack scale architectures, and storage class memories and we have a system that can’t keep up through evolutionary change. Revolutionary steps need to be taken.
To add fuel to the fire we have the notion of composable infrastructure and the value it can bring to IT via more dynamic and agile infrastructure to line up with these changing workloads. For many vendors, marketing hype is way ahead of the reality of the hardware architecture required to pull off real composability. I have written a couple of blogs that argue we have some real challenges ahead to create new hardware and software to pull off full composability:
A Practical View of Composable Infrastructure
Reality Check: Is Composable Infrastructure Ready for Prime Time?
Gen-Z – An Open Fabric Technology Standard on the Journey to Composability
It’s pretty clear we have 2 major problems to solve in today’s architecture:
- Memory Tier
- To address memory performance challenges we need to create tiers of different classes of memory
- Memory semantics need to be extended to rack level to make systems truly composable
- Performance
- To address these new optimized acceleration devices we need to bring them into the memory/cache domain of the CPU
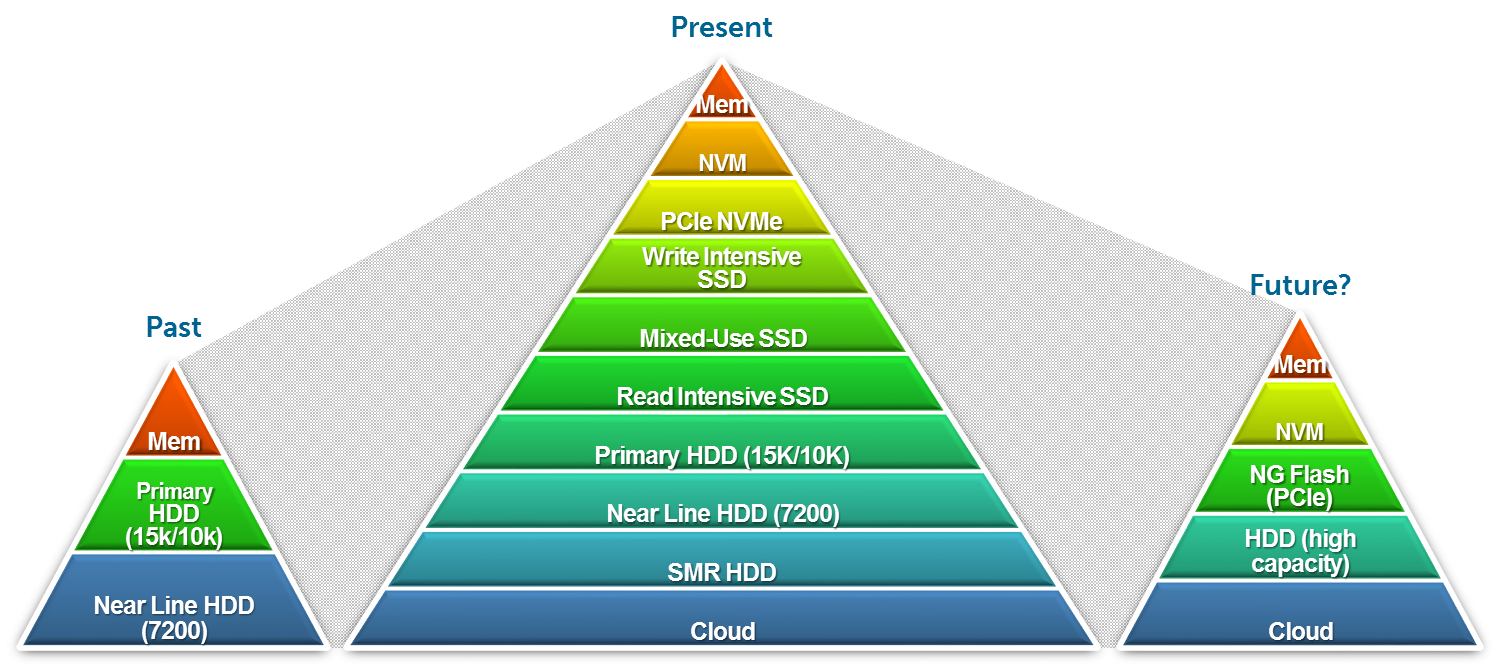
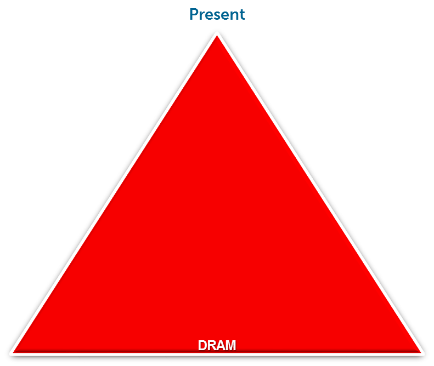
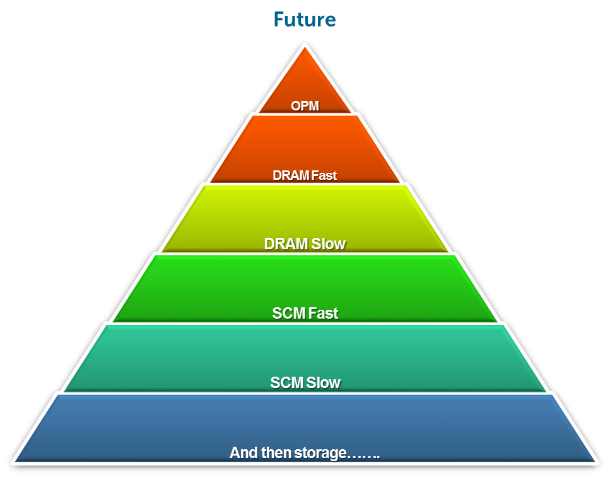
The storage industry has done a wonderful job of providing storage tiers. One could argue maybe too good of job. Below is a view of Past, Present, and possible Future storage tiers. Good news is the future outlook is on track to simplify this a bit.
On the memory front, the picture is much bleaker…it’s DRAM or NOT DRAM. It’s easy this way, but doesn’t scale well. The problem as outlined above shows that the DRAM-only approach can’t keep up with emerging use cases. And if you think about it deeper, we can control thread priorities at an application/operating system level but not down to the DRAM access level. That means when your highest priority thread runs on Core1 and some background thread runs on Core18 they actually get the same priority access to the most congested part of the system – DRAM.
What we need in the future looks like the pyramid below. Start with highest performance On Package Memory (small, high bandwidth, low latency, expensive) and build up to greater capacity, slower, and lower cost memories. But it has to be done in the native language of the CPU – namely load/stores. CPUs only know how to do load/stores, they don’t know anything about TCP/IP, SCSI, iSCSI and so forth.
Industry Teams Up
That is the backdrop that has led 50+ tech titans to recognize the architecture issues we face today and join forces on Gen-Z, CCIX, and OpenCAPI. It’s pretty interesting to see Dell, IBM, HPE, Huawei, Lenovo and others all in the mix together, not to mention CPU/GPU vendors AMD, IBM, ARM, Qualcomm, Cavium, Nvidia, and so on.

Another interesting observation about Gen-Z, CCIX, and OpenCAPI is that they are all truly open standards – anyone can join, contribute, influence, and adopt. There is a lot of IP these companies have thrown into the mix to advance the industry rather than keeping them locked away in proprietary systems.
So, how do they all relate?
CCIX and OpenCAPI will help the performance of these new specialized accelerators to bring them closer to the CPU/Memory domain. They will allow acceleration devices (GPUs/SmartNICs/FPGA) to access and process data irrespective of where it resides, without the need for complex programming environments. This ability to access data coherently dramatically improves performance and usability. They both also push the bounds of IO technology from today’s PCIe Gen3 8Gbpps to 25Gbpps and prepare the industry for higher speeds to come. They will also enable new innovations by enabling more flexibility for attachment of Storage Class memories and bridging to new busses like Gen-Z due to being memory semantic based.
Gen-Z is an open systems interconnect designed to provide memory semantic access to data and devices via direct-attached, switched, or fabric topologies. Not only is Dell a member but also president of the Gen-Z consortium. Gen-Z provides memory media independence for emerging storage class memories and opens the door compute in-memory concepts. Gen-Z also pushes the bounds of IO technology to 25Gbpps and scales beyond the node to enable true rack scale composability.
Putting it all together
The future is bright. The industry is on a journey of open – Open Compute, OpenStack, Open vSwitch, Open Networking. Open source will be adopted more than ever for machine learning, deep learning, cognitive computing, IoT, and so forth. CCIX and OpenCAPI aim to create an open IO ecosystem for advanced acceleration devices. By combining CCIX/OpenCAPI with Gen-Z we’ll be able to create memory tiers and finally tackle composability at rack scale. The industry is working together to accelerate innovation for solving real world problems today, and in an open way that paves the way for the problems we cannot see yet. In my almost 30 years in the industry, this collaboration between peers is the greatest I have ever seen. It’s quite encouraging and exciting to see revolutionary architectures emerge to solve real world problems.
In my next couple of blogs I’ll continue to detail how this will play out and how Dell will lead this transition.