ゲノム アプリケーション向けの、Cascade Lakeを使用したパフォーマンス スタディ
概要: HPCハイパフォーマンスコンピューティング、HPCおよびAIイノベーションラボ、ゲノミクス、バリアント呼び出し、de novoアセンブリ、次世代シーケンシング、BWA-GATK、SOAPdenovo2、SPAdes、Cascade Lake
この記事は次に適用されます:
この記事は次には適用されません:
この記事は、特定の製品に関連付けられていません。
すべての製品パージョンがこの記事に記載されているわけではありません。
現象
この記事は、HPC and AI Innovation LabのKihoon Yoonによって2019年5月に作成されました。
原因
なし
解決方法
バリアント呼び出しと De novo アセンブリ
概要
第2世代インテル® Xeon® スケーラブル プロセッサーはSkylakeの後継であり、シングル プロセッサー(Cascade Lake AP 9282)で最大56コアを提供します。インテルが提供するコア数の増加に加えて、Optaneのサポート、より高速なDRAM(1 DPC構成のDDR4-2933)、およびより多くのDRAM構成(1TB、2TB、4TB)があります。一般的に消費者が新しいプロセッサーに、より高いパフォーマンス、優れた効率、および低電力を期待していることは明らかです。ただし、一部のお客様は、 新しい命令のサポート、階層化されたエコシステムの最適化、新しいテクノロジーのサポート、新しい製品の方向性など、それほど明白ではない改善を求めています。Cascade Lakeは、二次的な特性に重点を置いたSkylakeを基盤として構築されており、改善点はそれほど明白ではありません。
通常、次世代シーケンシング(NGS)データ解析のアプリケーションはオープンソースであり、新しい技術が登場してもすぐには更新されません。つまり、Cascade Lakeによる改善は、NGSアプリケーションのパフォーマンスに影響を与える可能性が低くなります。
このブログでは、Variant Callingと De Novo assemblyという2つの異なるゲノミクス ワークロードでCascade Lake CPUがどのように動作するかについて説明します。
バリアント呼び出しと De Novo アセンブリの詳細なテスト構成を表 1 に示します。
表 1 バリアント呼び出しと De Novo アセンブリのテスト構成
|
|
Dell PowerEdge R640 |
Dell PowerEdge R940 |
|||||||
|
Skylake |
カスケード湖 |
Skylake |
カスケード湖 |
||||||
|
CPU |
6154 x 2 |
6148 x 2 |
6152 x 2 |
6138 x 2 |
6248 x 2 |
6252 x 2 |
6230 x 2 |
8168 x 4 |
8280M x 4 |
|
ベース周波数(GHz) |
3.0 |
2.4 |
2.1 |
2.0を切り替える方法 |
2.5 |
2.1 |
2.1 |
2.7 |
2.7 |
|
コア数 |
18 |
20 |
22 |
20 |
20 |
24 |
20 |
24 |
28 |
|
TDP(W) |
200 |
150 |
140 |
140 |
150 |
125 |
125 |
205 |
205 |
|
メモリー |
24 x 16GB DDR4-2666MHz、2 DPC |
12 x 32GB DDR4-2933MHz、1 DPC |
48 x 32GB DDR4-2666MHz、2 DPC |
24 x 64GB DDR4-2933MHz、1 DPC |
|||||
|
ストレージ |
10x 1.2TB SAS 12 Gbps、RAID 0の10K |
18x 1.2TB SAS 12 Gbps、10K(RAID 0) |
|||||||
|
システムBIOS |
2.1.3 |
||||||||
|
カーネル |
3.10.0-957.el7.x86_64 |
||||||||
|
OS |
Red Hat Enterprise Linux Serverリリース7.6(Maipo) |
||||||||
|
シーケンス読み取り |
ERR194161、バリアント呼び出しのための50倍の全ヒトゲノムと ERR318658、32億回のヒトゲノム全読み取りによる de novo アセンブリー |
||||||||
バリアント呼び出し
BWA-GATK パイプライン
図 1に示すように、各ステップはテストされた各 CPU でまったく異なる動作をし、テストした CPU によるさまざまなステップ間のパフォーマンスの差は 0.61% から 46.34% の範囲です。ただし、全体的なランタイムの違いはそれほど顕著ではありません(表2)。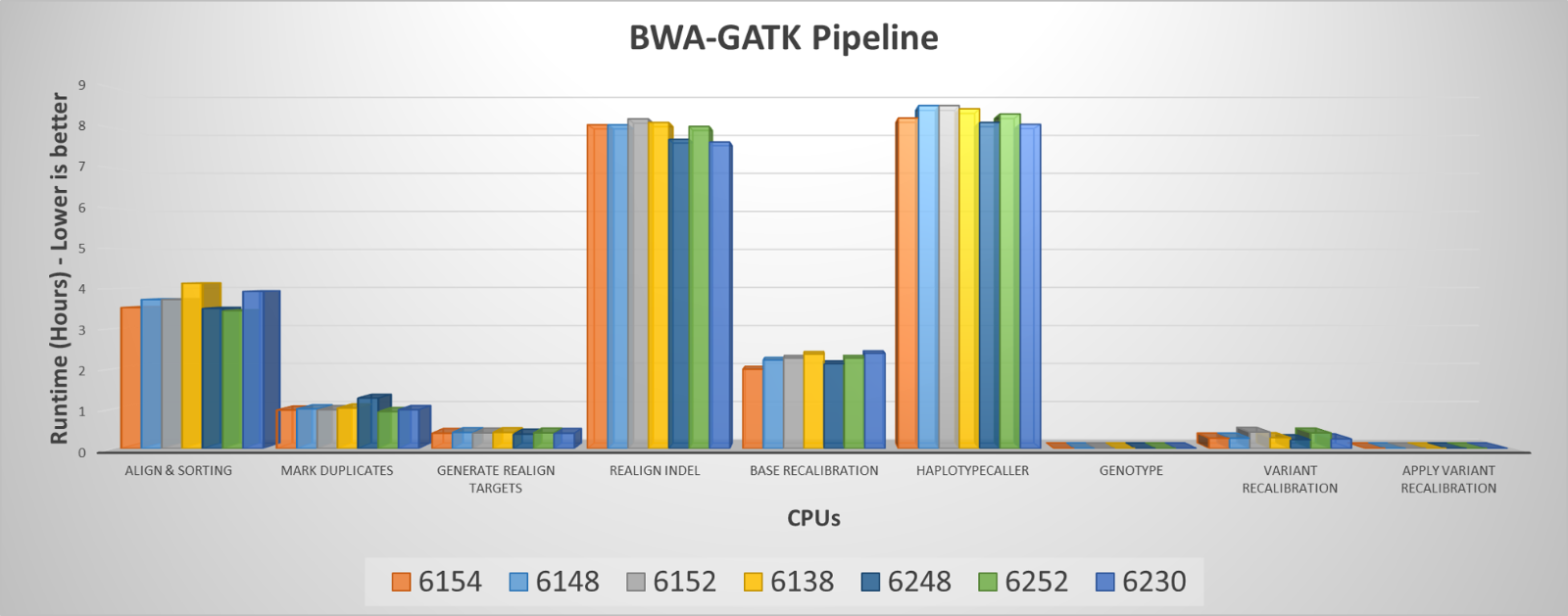
図 1 バリアント呼び出しパイプラインの各ステップの実行時間
Cascade Lake 6248は、ほとんどのステップと全体的なランタイムにおいて優れたパフォーマンスを示しましたが、[Mark Duplicates]ステップのパフォーマンスは低く、Cascade Lake 6252よりも27%遅くなりました。このステップで6248のパフォーマンスが低い理由は不明ですが、繰り返しテストすると一貫した結果が得られます。さまざまな手順でこのように動作に一貫性がないため、ワークフローに適切なCPUを選択する際には、全体的なパフォーマンスを考慮する方が理にかなっています。
表2 Skylake CPUとCascade Lake CPUの合計ランタイム比較
|
CPU |
価格 |
仕様 |
合計 BWA-GATK ランタイム (時間) |
|
|
Skylake |
6148 |
$3,072.00 - $3078.00 |
2.4 GHz、20コア、150W |
24.26 |
|
6154 |
3,543.00ドル |
3.0 GHz、18コア、200W |
23.47 |
|
|
6152 |
$3,655.00 - $3661.00 |
2.1 GHz、22コア、140W |
24.58 |
|
|
6138 |
$2,612.00 - $2618.00 |
2.0 GHz、20コア、125W |
24.83 |
|
|
カスケード湖 |
6248 |
$3,072.00 - $3,078.00 |
2.5 GHz、20コア、150W |
23.36 |
|
6252 |
$3,655.00 - $3,662.00 |
2.1 GHz、24コア、150W |
23.82 |
|
|
6230 |
$1,894.00 - $1,900.00 |
2.1 GHz、20コア、125W |
23.68 |
|
Cascade Lake 6248を使用すると全体的に最高のパフォーマンスを実現できますが、電力が限られているお客様にはCascade Lake 6230も適した選択肢ではありません。ここに示す結果は単一のサンプル テストに基づいているため、スループット テストの結果なしにCascade Lake 6230と6248がCascade Lake 6252よりも優れているかどうかを判断することは困難です。ただし、スループットを考慮すると、Cascade Lake 6252はコア数が多いため、スループット テストでのパフォーマンスを上回る可能性があります。より多くのサンプルを同時に処理できます。それでも、Cascade Lake 6230は、テスト済みのCPUの中で最もコスト パフォーマンスに優れた選択肢になる可能性があります。
de novoアセンブリー
De Novo Assemblyの場合、Skylake 8168とCascade Lake 8280Mを、R940の同じ容量の1.5TBのシステム メモリーと比較しています。Cascade Lake 8280Mを選択した主な理由は、コア数が多いことと、より多くのメモリーをサポートすることにあります。これは、 De Novo アセンブリーのデータ サイズが時間の経過とともに増加し続ける場合に有益です。
SOAPデノボ2
Skylake 8168からCascade Lake 8280Mへのアップグレードによる最大パフォーマンスの向上は約1%です(図2のCascade Lake 8280Mの比較では、Skylake 8168の92コアとCascade Lake 8280Mの108コア)。このテストでは、CPUあたり1コアをOSやその他のハウスキーピング用に残しました。 結果は、さまざまな数のコアを使用した場合、Cascade Lake 8280Mが平均で2%遅くなることを示していますが、8168の92コアと8280Mの108コアを比較したところ、Cascade Lake 8280MのパフォーマンスがSkylake 8168よりもわずかに優れていることが確認されました。
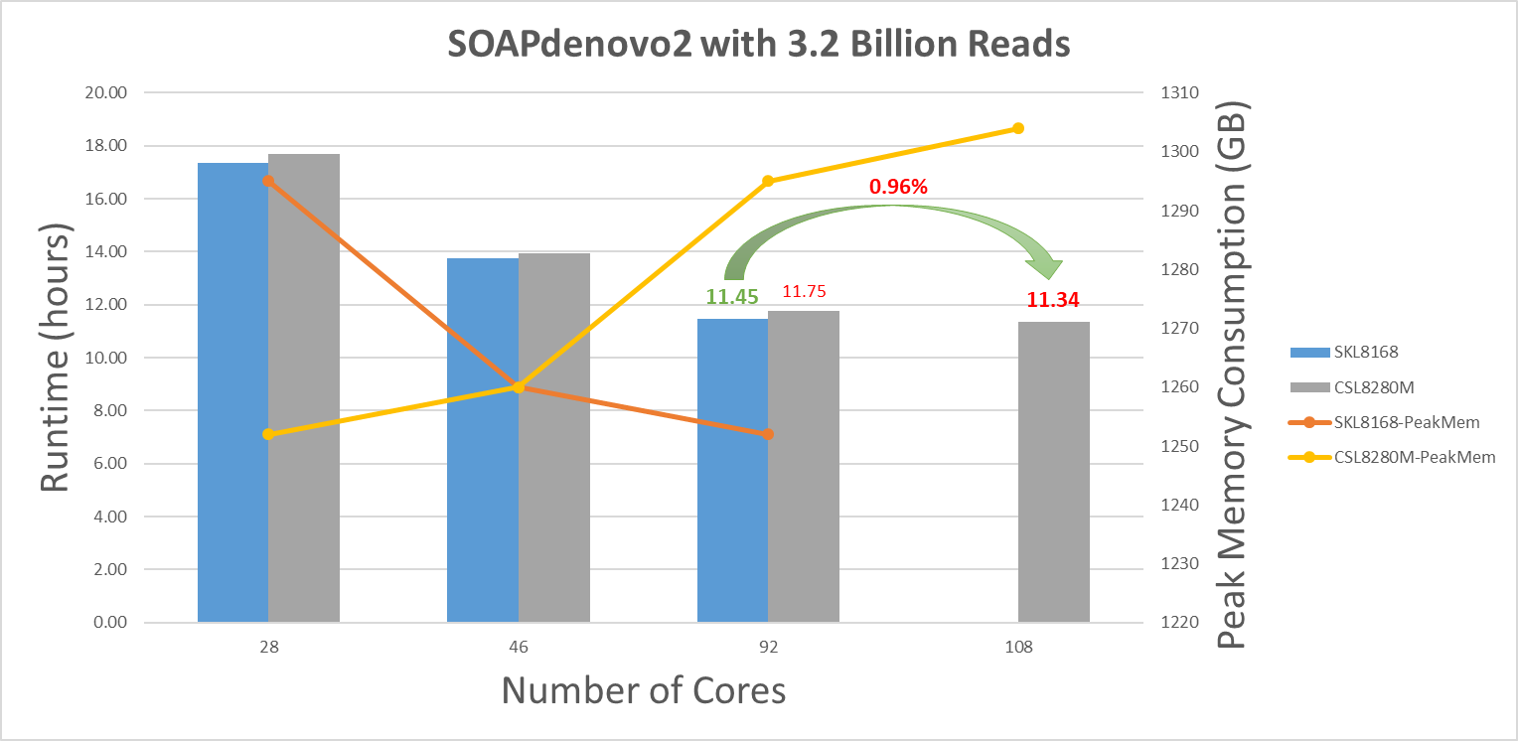
図2 さまざまな数のコアを使用したSOAPdenovo2のランタイムとピークメモリ消費量のプロット
SOAPdenovo2は、メモリー帯域幅が制限されているようです。ピーク メモリー消費量は、Cascade Lake CPU上の1 DPC構成のプロセスに使用されるコアが増えるにつれて絶えず上昇し、Skylake CPU上の2 DPC構成ではピーク メモリー消費量が減少します。以前に公開された ブログメモリー帯域幅は、同じタイプのデュアル ランクDIMMを使用した1 DPC構成と2 DPC構成で11%異なる場合があります。より良い結論を出すために、Cascade Lake 8280M CPU上の2つのDPC構成(DDR4-2666)を使用して、さらにテストを行う必要があります。
スペード
図3に示すように、Cascade 8280Mはさまざまな数のコアを使用したテスト全体でパフォーマンスが向上しており、CPUとCPUの比較(92コア8168と108コア8280Mの比較)では5%高いパフォーマンスを達成できます。ピーク メモリ消費量のパターンは、2 つの CPU 間でほぼ同じです。ただし、1 DPC構成のCascade Lake 8280Mは、2 DPC構成のSkylake 8168よりもメモリー消費量が高くなります。SOAPdenovo2テストからわかるように、メモリー帯域幅はそれほど重要ではないようですが、DDR4-2666MHzを使用した2 DPC構成は 、De Novo Assemblyのより良い構成になる可能性があります。
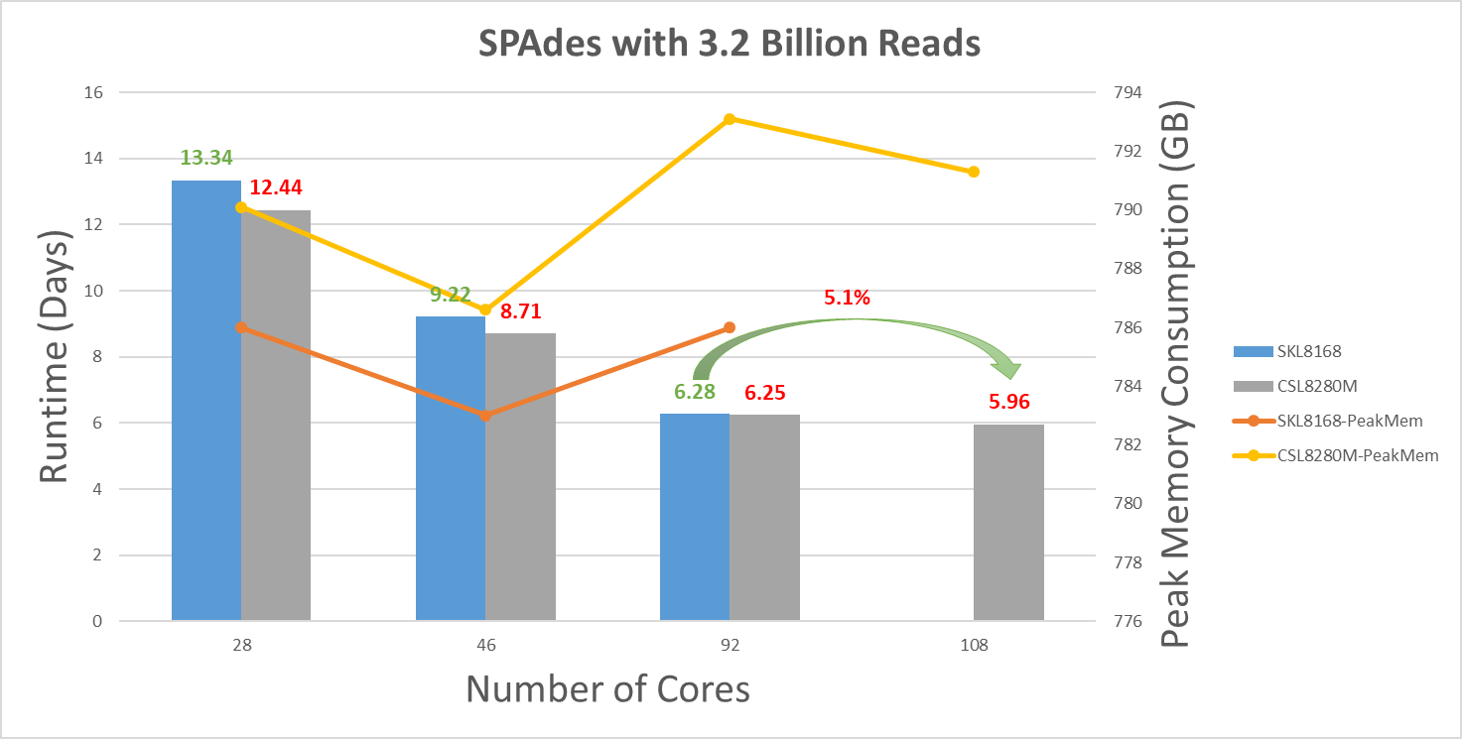
図3 さまざまな数のコアを持つSPAdeのランタイムとピーク メモリー消費量のプロット
結論
全体として、ここでテストしたCascade Lake CPUは、Variant Callingや De Novo Assemblyなどのゲノミクス ワークロードにおいて、Skylake CPUよりも優れたパフォーマンスを示していません。Cascade Lake CPUはSkylake CPUをベースにしており、純粋なパフォーマンスを向上させるのではなく、サポート機能を改善することを目的としているため、同様のパフォーマンスがある程度期待されていました。ただし、Cascade Lakeは、TDPが低く、コア数が多いという点で、Skylakeよりも多くの選択肢を提供します。DDR4 2933 MHz DIMMSを搭載した1 DPC構成では、SOAPdenovo2のパフォーマンスが向上しないことは注目に値します。De Novo Assemblyアプリケーションの場合は、メモリ帯域幅が大きい方が良いようです。Cascade Lake CPUの1 DPC構成では、メモリーをDDR4 2933MHzにアップグレードするメリットはありません。特に De Novo アセンブリー アプリケーションでは、DDR4 2666MHzで2つのDPC構成をセットアップすることをお勧めします。
対象製品
PowerEdge R640文書のプロパティ
文書番号: 000146815
文書の種類: Solution
最終更新: 09 3月 2026
バージョン: 4
質問に対する他のDellユーザーからの回答を見つける
サポート サービス
お使いのデバイスがサポート サービスの対象かどうかを確認してください。