Troubleshooting-Handbuch für physische vSAN-Festplatte
Summary: Dies ist ein allgemeines Troubleshooting-Handbuch, mit dem Sie feststellen können, ob ein Problem mit einem physischen Laufwerk in vSAN-Clustern vorliegt.
This article applies to
This article does not apply to
This article is not tied to any specific product.
Not all product versions are identified in this article.
Instructions
Überprüfen des Status des physischen vSAN-Laufwerks über die Webnutzeroberfläche:
Stellen Sie eine Verbindung zum vCenter Server-Webclient her und überprüfen Sie den Festplattenstatus über:
Inventar > Host und Cluster > vSAN-Cluster > vSAN-Datenträgerverwaltung konfigurieren Abbildung 1: Ansicht "vSAN Disk Management" Wählen Sie den betroffenen Host aus und erweitern Sie dann den Abschnitt "Festplatte anzeigen":Abbildung 2: Ansicht der vSAN-Festplattengruppe >>
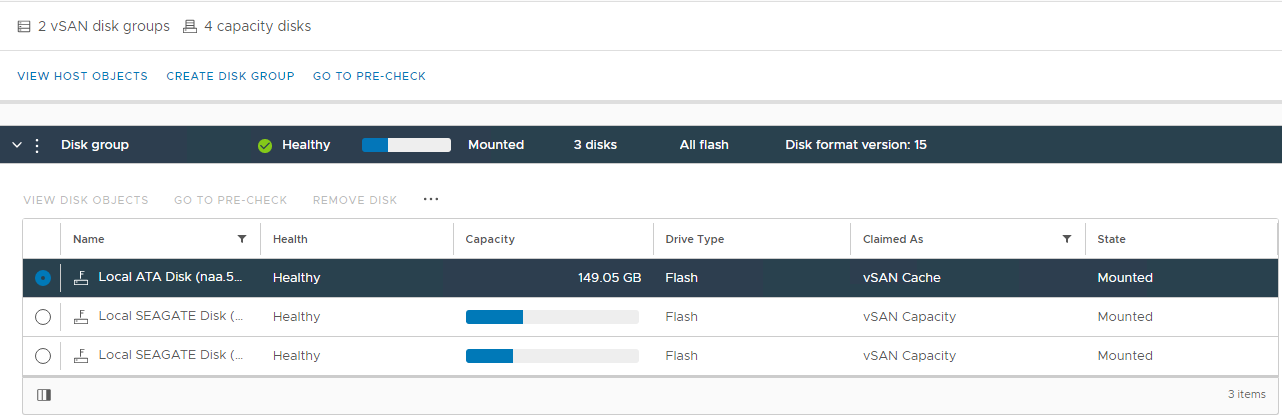 Hier können Sie überprüfen, ob eine Festplatte erkannt wird als:
Hier können Sie überprüfen, ob eine Festplatte erkannt wird als:

Unhealthy
Unmounted
0 Capacity
Permanent Disk Failure
Disk Down
Disk Absent
Suchen Sie außerdem nach festplattenbezogenen Alarmen, die im Abschnitt vSAN Skyline Health ausgelöst werden:
Inventar > Host und Cluster vSAN Cluster > Monitor >> vSAN > Skyline Health > Physisches Laufwerk
Abbildung 3: Skyline-Integritätsansicht

Hier können Sie überprüfen, ob einer der folgenden Alarme ausgelöst wurde:
Bevorstehender permanenter Festplattenausfall. Daten werden evakuiert (Integritätsstatus – gelb).
Bevorstehender permanenter Festplattenausfall, Datenevakuierung aufgrund unzureichender Ressourcen fehlgeschlagen (Integritätsstatus – Rot).
Bevorstehender permanenter Festplattenausfall, Datenevakuierung aufgrund von nicht zugänglichen Objekten fehlgeschlagen (Integritätsstatus – Rot).
Bevorstehender permanenter Festplattenausfall, Datenevakuierung abgeschlossen (Integritätsstatus – gelb)
Sie können den Festplattenstatus auch über die Liste der Storage-Geräte des betroffenen Hosts überprüfen:
Inventar > Host und Cluster vSAN-Cluster > Betroffene vSAN ESXi-Hosts Storage Storage-Geräte >>>>
konfigurieren Abbildung 4: Ansicht Host-Storage-Geräte

Hier können Sie überprüfen, ob der Status eines Datenträgers wie folgt lautet:
0 Kapazitätsfestplatte
fehlt
Festplatte unmountet
Überprüfen Sie, ob eine Neusynchronisierung stattfindet:
Inventar > Host und Cluster vSAN-Cluster >> Überwachen vSAN >> Neusynchronisieren von Objekten:Abbildung 5:
Ansicht "Neusynchronisieren von Objekten"

Überprüfen Sie den Status von vSAN-Objekten:
Inventar > Host und Cluster vSAN Cluster > Monitor >> vSAN Skyline Health > Daten > vSAN object health Abbildung 6: Ansicht der vSAN-Objektintegrität >

Der nächste Schritt besteht darin, über die CLI weitere Informationen über das Problem zu sammeln und die Protokolle zu überprüfen:Überprüfen des Status des physischen vSAN-Laufwerks über die CLI:Stellen Sie eine SSH-Verbindung zum betroffenen Host her und führen Sie die folgenden Befehle aus:
Beispiel:
Beispiel:
Beispiel:
Beispiel:
Beispiel:
Beispiel:
Drücken Sie Strg+C , um den Befehl zu beenden.
Fehlerfrei -- Zustand 7
Zugriff -- Zustand 13
Nicht vorhanden oder herabgesetzt -- Zustand 15
Beispiel:
So ermitteln Sie über die CLI, wo sich die fehlerhafte SSD oder FESTPLATTE befindet:
Listen Sie alle verfügbaren Geräte auf:
Beispiel:
Suchen Sie den Speicherort mit jeder naa-Festplatte aus der Liste:
Beispiel:
So identifizieren Sie die fehlerhafte Festplatte oder SSD, wenn der Gerätename fehlt:
Es ist möglich, dass die fehlerhafte Festplatte nicht erkannt wird und nicht mit der entsprechenden naa identifiziert werden kann. In diesem Szenario müssen alle Festplatten gefunden werden, und diejenige, die sich nicht physisch befindet, ist diejenige, die ausgefallen ist.
Hier ist ein Skript, mit dem die Aufgabe etwas schneller ausgeführt werden kann:
vSAN-relevante Protokolle für Storage-bezogene Probleme:
/var/log/vmkernel.log
Probleme beim Lesen und Schreiben auf vSAN-Festplatten, vSAN-Host-Heartbeats, PDLs, SCSI-Erkennungscodes und I/O-Anforderungen (Lese-/Schreibvorgänge) sowie Cluster-Mitgliedschaftsinformationen.
Beispiel:
/var/log/vobd.log
Berichte über Festplattenintegrität, dauerhaft verlorene Festplatten (PDLs), Festplattenlatenz und Berichte darüber, wann ein Host in den Wartungsmodus wechselt und ihn verlässt.
Beispiel:
/var/log/vsandevicemonitord.log
Es hilft Ihnen festzustellen, ob die Festplatte aufgrund einer übermäßigen Protokollüberlastung oder I/O-Latenzen als fehlerhaft markiert wurde.
Beispiel:
Stellen Sie eine Verbindung zum vCenter Server-Webclient her und überprüfen Sie den Festplattenstatus über:
Inventar > Host und Cluster > vSAN-Cluster > vSAN-Datenträgerverwaltung konfigurieren Abbildung 1: Ansicht "vSAN Disk Management" Wählen Sie den betroffenen Host aus und erweitern Sie dann den Abschnitt "Festplatte anzeigen":Abbildung 2: Ansicht der vSAN-Festplattengruppe >>
Hier können Sie überprüfen, ob eine Festplatte erkannt wird als:
Unhealthy
Unmounted
0 Capacity
Permanent Disk Failure
Disk Down
Disk Absent
Suchen Sie außerdem nach festplattenbezogenen Alarmen, die im Abschnitt vSAN Skyline Health ausgelöst werden:
Inventar > Host und Cluster vSAN Cluster > Monitor >> vSAN > Skyline Health > Physisches Laufwerk
Abbildung 3: Skyline-Integritätsansicht
Hier können Sie überprüfen, ob einer der folgenden Alarme ausgelöst wurde:
Bevorstehender permanenter Festplattenausfall. Daten werden evakuiert (Integritätsstatus – gelb).
Bevorstehender permanenter Festplattenausfall, Datenevakuierung aufgrund unzureichender Ressourcen fehlgeschlagen (Integritätsstatus – Rot).
Bevorstehender permanenter Festplattenausfall, Datenevakuierung aufgrund von nicht zugänglichen Objekten fehlgeschlagen (Integritätsstatus – Rot).
Bevorstehender permanenter Festplattenausfall, Datenevakuierung abgeschlossen (Integritätsstatus – gelb)
Sie können den Festplattenstatus auch über die Liste der Storage-Geräte des betroffenen Hosts überprüfen:
Inventar > Host und Cluster vSAN-Cluster > Betroffene vSAN ESXi-Hosts Storage Storage-Geräte >>>>
konfigurieren Abbildung 4: Ansicht Host-Storage-Geräte
Hier können Sie überprüfen, ob der Status eines Datenträgers wie folgt lautet:
0 Kapazitätsfestplatte
fehlt
Festplatte unmountet
Überprüfen Sie, ob eine Neusynchronisierung stattfindet:
Inventar > Host und Cluster vSAN-Cluster >> Überwachen vSAN >> Neusynchronisieren von Objekten:Abbildung 5:
Ansicht "Neusynchronisieren von Objekten"
HINWEIS: Eine erneute Synchronisierung kann darauf hinweisen, dass Daten von einem betroffenen Laufwerk oder einer betroffenen Laufwerksgruppe evakuiert werden. Es sind weitere Untersuchungen erforderlich, um festzustellen, ob die betroffene Festplatte entfernt oder ersetzt werden kann.
Überprüfen Sie den Status von vSAN-Objekten:
Inventar > Host und Cluster vSAN Cluster > Monitor >> vSAN Skyline Health > Daten > vSAN object health Abbildung 6: Ansicht der vSAN-Objektintegrität >
HINWEIS: Es ist wichtig zu überprüfen, dass keine unzugänglichen Objekte vorhanden sind. "Objekt nicht zugänglich" bedeutet, dass "alle Kopien des Objekts fehlen". Wenn Sie eine Festplatte entfernen oder ersetzen, kann dies zu DL.
Der nächste Schritt besteht darin, über die CLI weitere Informationen über das Problem zu sammeln und die Protokolle zu überprüfen:Überprüfen des Status des physischen vSAN-Laufwerks über die CLI:Stellen Sie eine SSH-Verbindung zum betroffenen Host her und führen Sie die folgenden Befehle aus:
vdq -qHÜberprüfen Sie den Parameter "IsPDL" (permanenter Geräteverlust). Wenn der Wert gleich 1 ist, ist die Festplatte verloren.
Beispiel:
DiskResults:
DiskResult[0]:
Name: naa.600508b1001c4b820b4d80f9f8acfa95
VSANUUID: 5294bbd8-67c4-c545-3952-7711e365f7fa
State: In-use for VSAN
ChecksumSupport: 0
Reason: Non-local disk
IsSSD?: 0
IsCapacityFlash?: 0
IsPDL?: 0
<<truncated>>
DiskResult[18]:
Name:
VSANUUID: 5227c17e-ec64-de76-c10e-c272102beba7
State: In-use for VSAN
ChecksumSupport: 0
Reason: None
IsSSD?: 0
IsCapacityFlash?: 0
IsPDL?: 1
vdq -iHÜberprüfen Sie, ob ein Laufwerk in der Laufwerksgruppe fehlt.
Beispiel:
Mappings: DiskMapping[0]: SSD: naa.58ce38ee2016ffe5 MD: naa.5002538a4819e3e0 DiskMapping[2]: SSD: naa.58ce38ee2016fe55 MD: naa.5002538a48199ca0 MD: naa.5002538a48199e20 MD: naa.5002538a48199e00
esxcli vsan storage listÜberprüfen Sie den Parameter "In CMMDS". Bei "false" geht die Kommunikation mit der Festplatte verloren.
Beispiel:
Device: Unknown
Display Name: Unknown
Is SSD: false
VSAN UUID: 529cadbc-acd1-b588-8643-68336d5512d6
VSAN Disk Group UUID:
VSAN Disk Group Name:
Used by this host: false
In CMMDS: false
On-disk format version: <Unknown>
Deduplication: false
Compression: false
Checksum:
Checksum OK: false
Is Capacity Tier: false
for i in `esxcli storage core device list | grep ^naa` ; do echo $i; esxcli storage core device smart get -d $i; done.Prüfen Sie mit dem Befehl smart get auf Lese-/Schreibfehler.
Beispiel:
naa.55cd2e404c1f35a1 Parameter Value Threshold Worst Raw -------------------------- ----- --------- ----- --- Health Status OK N/A N/A N/A Media Wearout Indicator 100 0 100 86 Read Error Count 130 39 130 133 Power-on Hours 100 0 100 110 Power Cycle Count 100 0 100 106 Drive Temperature 100 0 100 26 Uncorrectable Sector Count 100 0 100 0
naa.55cd2e404c1f35a5 Parameter Value Threshold Worst Raw -------------------------- ----- --------- ----- --- Health Status OK N/A N/A N/A Media Wearout Indicator 100 0 100 10 Read Error Count 130 39 130 53 Power-on Hours 100 0 100 110 Power Cycle Count 100 0 100 106 Drive Temperature 100 0 100 27 Uncorrectable Sector Count 100 0 100 0
esxcli vsan storage list | grep "VSAN Disk Group UUID:" | sort | uniq -cSuchen Sie nach verfügbaren Laufwerksgruppen.
Beispiel:
2 VSAN Disk Group UUID: 5203424c-ee56-497d-75d1-fcf73ae997cb 2 VSAN Disk Group UUID: 52af8e5c-77d1-b552-3310-ec5fef09edf4
while true;do echo " ****************************************** "; echo "" > /tmp/resyncStats.txt ;cmmds-tool find -t DOM_OBJECT -f json |grep uuid |awk -F \" '{print $4}' |while read i;do pendingResync=$(cmmds-tool find -t DOM_OBJECT -f json -u $i|grep -o "\"bytesToSync\": [0-9]*,"|awk -F " |," '{sum+=$2} END{print sum / 1024 / 1024 / 1024;}');if [ ${#pendingResync} -ne 1 ]; then echo "$i: $pendingResync GiB";fi;done |tee -a /tmp/resyncStats.txt;total=$(cat /tmp/resyncStats.txt |awk '{sum+=$2} END{print sum}');echo "Total: $total GiB" |tee -aa /tmp/resyncStats.txt;total=$(cat /tmp/resyncStats.txt |grep Total);totalObj=$(cat /tmp/resyncStats.txt|grep -vE " 0 GiB|Total"|wc -l);echo "`date +%Y-%m-%dT%H:%M:%SZ` $total ($totalObj objects)" >> /tmp/totalHistory.txt; echo `date `; sleep 60; done Überprüfen Sie, ob laufende oder festgefahrene Resynchronisationsvorgänge vorhanden sind.
Beispiel:
Total: 0 GiB Mon Feb 13 17:32:06 UTC 2023
Drücken Sie Strg+C , um den Befehl zu beenden.
cmmds-tool find -f python | grep CONFIG_STATUS -B 4 -A 6 | grep 'uuid\|content' | grep -o 'state\\\":\ [0-9]*' | sort | uniq -cÜberprüfen Sie den Status der Komponenten.
Fehlerfrei -- Zustand 7
Zugriff -- Zustand 13
Nicht vorhanden oder herabgesetzt -- Zustand 15
Beispiel:
425 state\": 7
So ermitteln Sie über die CLI, wo sich die fehlerhafte SSD oder FESTPLATTE befindet:
Listen Sie alle verfügbaren Geräte auf:
esxcli storage core device list | grep "naa" | awk '{print $1}' | grep "naa"
Beispiel:
naa.5000c500852df8d3 naa.55cd2e404c1f35a1 naa.55cd2e404c1f35a5 naa.5000c500852dd5e7
Suchen Sie den Speicherort mit jeder naa-Festplatte aus der Liste:
esxcli storage core device physical get -d
Beispiel:
esxcli storage core device physical get -d naa.5000c500852df8d3 esxcli storage core device physical get -d naa.55cd2e404c1f35a1 esxcli storage core device physical get -d naa.55cd2e404c1f35a5 esxcli storage core device physical get -d naa.5000c500852dd5e7 Physical Location: enclosure 65535 slot 0 Physical Location: enclosure 65535 slot 1 Physical Location: enclosure 65535 slot 2 Physical Location: enclosure 65535 slot 3
So identifizieren Sie die fehlerhafte Festplatte oder SSD, wenn der Gerätename fehlt:
Es ist möglich, dass die fehlerhafte Festplatte nicht erkannt wird und nicht mit der entsprechenden naa identifiziert werden kann. In diesem Szenario müssen alle Festplatten gefunden werden, und diejenige, die sich nicht physisch befindet, ist diejenige, die ausgefallen ist.
Hier ist ein Skript, mit dem die Aufgabe etwas schneller ausgeführt werden kann:
echo "=============Physical disks placement=============="
echo ""
esxcli storage core device list | grep "naa" | awk '{print $1}' | grep "naa" | while read in; do
echo "$in"
esxcli storage core device physical get -d "$in"
sleep 1
echo "===================================================="
done
vSAN-relevante Protokolle für Storage-bezogene Probleme:
/var/log/vmkernel.log
Probleme beim Lesen und Schreiben auf vSAN-Festplatten, vSAN-Host-Heartbeats, PDLs, SCSI-Erkennungscodes und I/O-Anforderungen (Lese-/Schreibvorgänge) sowie Cluster-Mitgliedschaftsinformationen.
Beispiel:
2021-06-22T12:02:08.408Z cpu30:1001397101)ScsiDeviceIO: PsaScsiDeviceTimeoutHandlerFn:12834: TaskMgmt op to cancel IO succeeded for device naa.55cd2e404b7736d0 and the IO did not complete. WorldId 0, Cmd 0x28, CmdSN = 0x428.Cancelling of IO will be 2021-06-22T12:02:08.408Z cpu30:1001397101)retried.
/var/log/vobd.log
Berichte über Festplattenintegrität, dauerhaft verlorene Festplatten (PDLs), Festplattenlatenz und Berichte darüber, wann ein Host in den Wartungsmodus wechselt und ihn verlässt.
Beispiel:
2022-05-31T11:42:46.065Z: [vSANCorrelator] 10605891965954us: [vob.vsan.lsom.devicerepair] vSAN device 521a74ce-c980-c16c-ff3d-38a036233daf is being repaired due to I/O failures, and will be out of service until the repair is complete. If the device is part of a dedup disk group, the entire disk group will be out of service until the repair is complete. 2022-05-31T11:42:46.065Z: [vSANCorrelator] 10606062774178us: [esx.problem.vob.vsan.lsom.devicerepair] Device 521a74ce-c980-c16c-ff3d-38a036233daf is in offline state and is getting repaired
/var/log/vsandevicemonitord.log
Es hilft Ihnen festzustellen, ob die Festplatte aufgrund einer übermäßigen Protokollüberlastung oder I/O-Latenzen als fehlerhaft markiert wurde.
Beispiel:
INFO vsandevicemonitord WARNING - WRITE Average Latency on VSAN device naa.50000xxxxxxxx has exceeded threshold value 2000000 us 2 times. INFO vsandevicemonitord Tier 2 (naa.50000xxxxxxxx) as unhealthy
Affected Products
VMware ESXi 7.x, VMware VSANProducts
VMware, VMware ESXi 6.7.XArticle Properties
Article Number: 000209262
Article Type: How To
Last Modified: 12 Feb 2024
Version: 3
Find answers to your questions from other Dell users
Support Services
Check if your device is covered by Support Services.