Aceleración del análisis de datos genómicos con NVIDIA Clara Parabricks con el servidor Dell EMC DSS 8440 y GPU NVIDIA T4
Summary: En este artículo, se proporciona información sobre la aceleración del análisis de datos genómicos mediante el uso de parabricks de NVIDIA en Dell EMC DSS 8440 con GPU NVIDIA T4.
This article applies to
This article does not apply to
This article is not tied to any specific product.
Not all product versions are identified in this article.
Instructions
Descripción general
El primer paso para procesar datos de secuenciación de última generación (NGS) se denomina Análisis primario. Este paso es específico del instrumento de secuenciación y genera varios archivos FASTQ que contienen lecturas de secuenciación. En el paso siguiente, conocido como Análisis secundario, las lecturas de secuenciación de FASTQ se asignan a un genoma de referencia o a un transcriptome de referencia. El procesamiento adicional identifica variantes o diferencias entre la muestra de interés y una referencia. Las variantes se anotan e interpretan en los siguientes pasos descendentes. El tiempo de análisis secundario para una única muestra varía de horas a días, según el tamaño de los datos, los recursos informáticos disponibles, el software y el flujo de trabajo analítico.El análisis secundario es un proceso de procesamiento y almacenamiento intensivo, especialmente cuando se procesan de cientos a miles de genomas. Existen muchas estrategias para evitar cuellos de botella en el análisis secundario. Hasta hace poco, la adopción de la aceleración de hardware mediante GPU o FPGA se mantuvo baja debido al software personalizado que requieren los aceleradores de hardware. El software genómico de Parabricks, que NVIDIA adquirió en 2019, ha sido pionero en una pila de software que realiza varios flujos de trabajo de análisis genómico con GPU. Probamos Parabricks con Dell EMC PowerEdge C4140/4x nVIDIA® Tesla® GPU V100 hace aproximadamente dos años. Dell introdujo muchos avances tecnológicos en sus servidores y soluciones de almacenamiento, y NVIDIA Clara Parabricks lanzó versiones sólidas con aceleración mejorada y la adición de llamadores de variantes. Por ejemplo, un diseño de servidor de múltiples GPU basado en el servidor Dell EMC DSS 8440 con NVIDIA® Tesla® GPU T4 parecía prometedor para acelerar el análisis secundario y, al mismo tiempo, ofrecer un atractivo equilibrio entre el precio y el rendimiento. En este blog, se informa una nueva arquitectura de referencia y resultados de análisis comparativos para el análisis secundario de NVIDIA Clara Parabricks en un servidor DSS 8440 y GPU T4 de múltiples Tesla® con almacenamiento Dell EMC Isilon F800.
Arquitectura de referencia
En la figura 1 se ilustra la arquitectura de referencia probada. La arquitectura es modular y fácil de escalar. El software de aplicación NVIDIA Clara Parabricks utiliza una o más GPU, lo que hace que el escalamiento horizontal sea lo más simple posible. Los componentes básicos de hardware constan de Dell EMC PowerEdge R640 como nodo de administración, servidor DSS 8440 para procesamiento de GPU y almacenamiento Dell EMC Isilon F800.
Figura 1Arquitectura de referencia probada
DSS 8440, 2 sockets, servidor de 4U puede tomar hasta 10 GPU NVIDIA® Tesla® V100S Tensor Core, hasta 10 GPU NVIDIA® Quadro RTX™ o hasta 16 GPU NVIDIA Tesla T4, lo que proporciona una gran potencia. La configuración detallada de DSS 8440 se enumera en la Tabla 1.
| Dell EMC DSS 8440 | |
|---|---|
| CPU | 2 Xeon® Gold 6248R de 24 núcleos a 3,0 GHz |
| RAM | 24 de 64 GB a 2933 MTp |
| Sistema operativo | Red Hat Enterprise Linux Server versión 7.4 (Principalpo) |
| Perfil del sistema del BIOS | Rendimiento optimizado |
| Procesador lógico | Deshabilitado |
| Tecnología de virtualización | Deshabilitado |
| Aceleradores | 16 GPU NVIDIA® Tesla® T4 |
| Parabricks | v3.0.0.05 |
Dos switches Z9100-ON proporcionaron la interconexión entre el nodo de procesamiento y el clúster de almacenamiento Isilon F800. Se utiliza un switch adicional, N2248X-ON, para la administración.
Datos de NGS
Los datos para realizar un análisis comparativo del tiempo de ejecución del análisis secundario consistió en tres conjuntos de datos de secuenciación del genoma completo (DDRS), ERR091571,SRR3124837y ERR194161,lo que representa una cobertura de muestra de 10x, 30x y 50x, respectivamente. Estos conjuntos de datos están disponibles en el archivo Otide (ENA) europeo.Evaluación del rendimiento
Mejoras de software Reduzca el tiempo de ejecución NVIDIA continúa presentando mejoras desoftware a NVIDIA Clara Parabricks. En la figura 2, se muestra la reducción del tiempo de ejecución entre dos versiones de Parabricks que ejecutan la canalización de la línea de error mediante el servidor Dell PowerEdge C4140 con un entorno de prueba de 4 GPU V100. La migración de v2.1.0 a v3.0.0 redujo el tiempo de ejecución en un 42 %.

Figura 2 Versión más reciente de la variante de Parabricks que llama al tiempo de ejecución de la canalización.
Rendimiento de DSS 8440 con 16 T4
El tiempo de ejecución para un análisis secundario de NVIDIA Clara Parabricks con una sola GPU T4 es aproximadamente un 30 % más lento que el uso de una GPU V100. Sin embargo, dos (2) GPU T4 proporcionan aproximadamente un 10 % más de TFLOPS que una (1) GPU V100 a aproximadamente la mitad del costo. El DSS 8440 proporciona hasta 16 ranuras PCIe, lo que abre la posibilidad de diseñar un servidor basado en GPU T4 que ofrezca un rendimiento de tiempo de ejecución similar al de un sistema C4140 con cuatro GPU V100, pero a un menor costo.El análisis de Parabricks se realizó mediante un PowerEdge DSS 8440 con 16 GPU T4. Para cada conjunto de datos de muestra DESUS descrito anteriormente, el tiempo de ejecución se registró mediante un análisis secundario de 1, 2, 4, 8 y 16 GPU T4. Los resultados se trazan en las figuras 3 a 5. En general, el tiempo de ejecución no escala linealmente a medida que aumenta la cantidad de GPU por análisis. El patrón de escalamiento es similar a la cantidad de datos por muestra que aumenta de 10 a 50 veces la cobertura.
Aunque no se presentó aquí, una investigación anterior de Dell EMC sobre los resultados de tiempo de ejecución de Parabricks con ocho o más GPU V100 por análisis no escalo tan eficientemente como las GPU T4. Las pruebas adicionales demostraron que 6 GPU T4 generaron resultados de tiempo de ejecución casi idénticos a 4 GPU V100.

Figura 3 Comparaciones de rendimiento con 10x DDRS
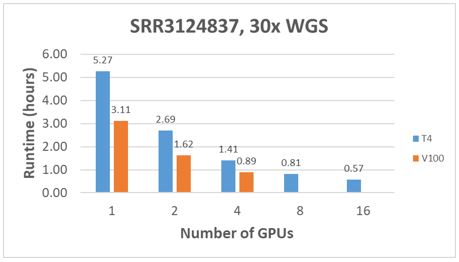
Figura 4 Comparaciones de rendimiento con 30x DDRS
Figura 5 Comparaciones de rendimiento con 50x DDRS
Conclusión
Un DSS 8440 con dieciséis GPU T4 es capaz de procesar treinta y cinco genomas humanos por día. Un rendimiento de análisis diario similar con una arquitectura de CPU x86 tradicional requiere diez nodos de procesamiento PowerEdge C6420. La arquitectura completa se analiza en una publicación anterior de Dell.
Sin embargo, dedicar las 16 GPU T4 a procesar una muestra ofrece poco beneficio, ya que el uso de 16 GPU por análisis es, en el mejor de los casos, un 10 % más rápido que el uso de 8 GPU. El diseño del DSS 8440 permite varios análisis secundarios en paralelo. Mediante la asignación de ocho GPU T4 por muestra, el rendimiento del análisis diario aumenta a aproximadamente 50 genomas por día. El uso de cuatro GPU por muestra aumenta el rendimiento del análisis a aproximadamente 70 genomas por día. Lo que es más importante, esta salida diaria con GPU T4 es menos de la mitad del costo de usar un diseño de GPU V100.
Además de la velocidad, la compatibilidad con otras herramientas de análisis es esencial para la capacidad de comparación de los resultados. Los resultados del análisis de Parabricks en línea son casi idénticos al análisis conocido de la persona que llama BWA-GATK Haplotype de pruebas anteriores. También queríamos comparar los resultados de llamadas de las variantes de Parabricks con otros conjuntos de herramientas, como samtools/mpileup. Estas dos herramientas completamente diferentes alcanzan aproximadamente un 90 % de acuerdo general para las variantes identificadas, y las variaciones en muchas regiones genómicas conocidas que contienen genes importantes coinciden en más del 99 %.
Affected Products
DSS 8440, Isilon F800, Poweredge C4140, PowerEdge R640Article Properties
Article Number: 000180441
Article Type: How To
Last Modified: 22 Feb 2025
Version: 3
Find answers to your questions from other Dell users
Support Services
Check if your device is covered by Support Services.