PowerEdge: Cómo solucionar fallas dobles y perforaciones en arreglos RAID
Summary: En este artículo, se proporciona información sobre fallas dobles y perforaciones en un arreglo RAID y se aconseja cómo solucionar el problema.
This article applies to
This article does not apply to
This article is not tied to any specific product.
Not all product versions are identified in this article.
Instructions
Tabla de contenido
- Reparación de fallas dobles y perforaciones de RAID
- Errores de datos y fallas dobles
- Perforaciones: ¿Qué son y a qué se deben?
- Prevención de problemas antes de que se presenten y resolución de perforaciones después de que ocurren
- Videos instructivos para crear/eliminar un arreglo o importar/exportar una configuración externa
Advertencia: Seguir estos pasos da como resultado la pérdida de todos los datos en el arreglo. Antes de realizar los pasos, asegúrese de que todos los datos en el arreglo estén respaldados y de que seguir estos pasos no afecte a ningún otro arreglo.
Reparación de fallas dobles y perforaciones de RAID
- Descartar la caché preservada (si existe)
- Borre las configuraciones ajenas (si hay)
- Elimine el arreglo
- Compruebe si hay unidades defectuosas
- Retire y vuelva a insertar las unidades defectuosas
- Borrar cualquier configuración externa nuevamente
- Reemplace todas las unidades defectuosas, incluidas las unidades con fallas predictivas
- Actualizar el firmware (controladora, backplane (BP), unidades) si es necesario
- Crear el arreglo
- Realizar una inicialización completa (no una inicialización rápida)
- En esta etapa, el arreglo debe estar listo para usarse
Errores de datos y fallas dobles
Los arreglos RAID no son inmunes a los errores de datos. La controladora RAID y el firmware del disco duro contienen funciones para detectar y corregir diversos tipos de errores de datos antes de que se escriban en un arreglo o una unidad.
- Los errores de datos pueden ser causados por bloques defectuosos físicos, como un "Head Crash" o la degradación de la capacidad del disco para almacenar bits de forma magnética en una ubicación específica.
- Un bloque defectuoso, también conocido como una dirección de bloque lógico (LBA) incorrecta, también puede deberse a errores de datos lógicos, como un "cambio de bits" o la escritura de datos incorrectos en una unidad.
- Los LBA defectuosos se informan comúnmente como el código de detección 3/11/0.
- Las controladoras RAID basadas en hardware de Dell ofrecen funciones como la lectura de patrullaje y la verificación de congruencia para corregir muchas situaciones de error de datos.
Realizar operaciones regulares de comprobación de coherencia corregirá las fallas únicas, ya sea un bloque físico defectuoso o un error lógico de los datos.
La verificación de consistencia también mitigará el riesgo de una condición de falla doble en caso de que se produzcan errores adicionales.

Figura 1 Múltiples fallas únicas en un arreglo RAID 5: arreglo óptimo

Figura 2 Falla doble con una unidad fallida (pérdida de datos en las fracciones 1 y 2): arreglo degradado.
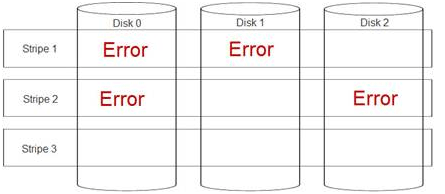
Figura 3 Fracciones perforadas (los datos en las fracciones 1 y 2 se pierden debido a una condición de falla doble): arreglo óptimo.
Perforaciones: ¿Qué son y a qué se deben?
Una perforación es una característica de las controladoras PERC de Dell, diseñada para permitir que la controladora restaure la redundancia del arreglo, a pesar de la pérdida de datos producida por una condición de falla doble.
- Una perforación también se conoce como "reconstrucción con errores".
- Un pinchazo puede ocurrir en una de dos situaciones: una doble falla ya existe o una doble falla no existe.
- Se puede producir una perforación en tres ubicaciones: un espacio en blanco, un espacio de datos no críticos o un espacio de datos al que se accede.
- Cualquier condición que impida el acceso a los datos en la misma banda en más de una unidad es una falla doble
- Las fallas dobles causan la pérdida de todos los datos dentro de la banda afectada
- Todas las perforaciones son fallas dobles, pero NO todas las fallas dobles son perforaciones
Prevención de problemas antes de que se presenten y resolución de perforaciones después de que ocurren
El mantenimiento proactivo puede corregir los errores existentes y evitar que se produzcan algunos de ellos.
- Actualizar controladores y firmware en controladoras, discos duros, backplanes y otros dispositivos.
- Realizar operaciones rutinarias de verificación de coherencia.
- Revise los registros para ver si hay indicios de problemas.
Nota: Si la verificación de consistencia se completa sin errores, puede suponer con seguridad que el arreglo se encuentra en buenas condiciones y que la perforación se ha eliminado. Los datos ahora se pueden restaurar al arreglo en buen estado.
Advertencia: Si existe una condición conocida o sospechada de doble falla o perforación, siga estos pasos para minimizar el riesgo de problemas más graves:
- Realice una rutina de verificación de congruencia (el arreglo debe ser óptimo)
- Determine si existen problemas de hardware
- Compruebe el registro de la controladora
- Realice diagnóstico de hardware
- Comuníquese con el soporte técnico de Dell si fuese necesario
Nota: Si estos pasos se realizaron, existen problemas adicionales que considerar. Con el paso del tiempo, las perforaciones pueden hacer que los discos duros entren en un estado de falla predictiva. Los errores de datos que se propagan a una unidad se informarán como errores de medios en la unidad, aunque no existan problemas de hardware.
Nota: El monitoreo del sistema permite detectar y corregir problemas de manera oportuna, lo que también reduce el riesgo de problemas más graves.
Videos instructivos para crear/eliminar un arreglo o importar/exportar una configuración externa
Cómo crear o eliminar un disco virtual en iDRAC 9
Duración: 00:01:53
Cuando esté disponible, se puede elegir la configuración de idioma de los subtítulos cerrados (subtítulos) mediante el ícono CC en este reproductor de video.
Cómo importar la configuración externa para Dell PERC
Duración: 00:02:07
Cuando esté disponible, se puede elegir la configuración de idioma de los subtítulos cerrados (subtítulos) mediante el ícono CC en este reproductor de video.
Cómo borrar la configuración externa de Dell PERC
Duración: 00:02:02
Cuando esté disponible, se puede elegir la configuración de idioma de los subtítulos cerrados (subtítulos) mediante el ícono CC en este reproductor de video.
Affected Products
OEMR R240, OEMR R250, OEMR R260, OEMR R340, OEMR R350, OEMR XE R350, OEMR R360, OEMR XE R360, OEMR R440, OEMR R450, OEMR R540, OEMR R550, OEMR R640, OEMR XL R640, OEMR R6415, OEMR R650, OEMR R650xs, OEMR R6515, OEMR R6525, OEMR R660, OEMR XL R660
, OEMR R660xs, OEMR R6615, OEMR R6625, OEMR R740, OEMR XL R740, OEMR R740xd, OEMR XL R740xd, OEMR R740xd2, OEMR R7415, OEMR R7425, OEMR R750, OEMR R750xa, OEMR R750xs, OEMR R7515, OEMR R7525, OEMR R760, OEMR R760xa, OEMR R760XD2, OEMR XL R760, OEMR R760xs, OEMR R7615, OEMR R7625, OEMR R840, OEMR R860, OEMR R940, OEMR R940xa, OEMR R960, OEMR T340, OEMR T350, OEMR T360, OEMR T440, OEMR T550, OEMR T560, OEMR T640, OEMR XL T640, OEMR XL R240, OEMR XL R340, OEMR XL R660xs, OEMR XL R6615, OEMR XL R6625, OEMR XL R760xs, OEMR XL R7615, OEMR XL R7625, PowerEdge RAID Controller H345, PowerEdge RAID Controller H355 Front SAS, PowerEdge RAID Controller H355 Adapter SAS, PowerEdge RAID Controller H750 Adapter SAS, PowerEdge RAID Controller H755 Adapter, PowerEdge RAID Controller H755 Front SAS, PowerEdge RAID Controller H965i Adapter, Poweredge C4140, PowerEdge C6400, PowerEdge C6420, PowerEdge C6520, PowerEdge C6525, PowerEdge C6600, PowerEdge C6615, PowerEdge C6620, PowerEdge FC640, PowerEdge HS5610, PowerEdge HS5620, PowerEdge M640, PowerEdge M640 (for PE VRTX), PowerEdge MX5016s, PowerEdge MX7000, PowerEdge MX740C, PowerEdge MX750c, PowerEdge MX760c, PowerEdge MX840C, PowerEdge R240, PowerEdge R250, PowerEdge R260, PowerEdge R340, PowerEdge R350, PowerEdge R360, PowerEdge R440, PowerEdge R450, PowerEdge R540, PowerEdge R550, PowerEdge R640, PowerEdge R6415, PowerEdge R650, PowerEdge R650xs, PowerEdge R6515, PowerEdge R6525, PowerEdge R660, PowerEdge R660xs, PowerEdge R6615, PowerEdge R6625, PowerEdge R670, PowerEdge R740, PowerEdge R740XD, PowerEdge R740XD2, PowerEdge R7415, PowerEdge R7425, PowerEdge R750, PowerEdge R750XA, PowerEdge R750xs, PowerEdge R7515, PowerEdge R7525, PowerEdge R760, PowerEdge R760XA, PowerEdge R760xd2, PowerEdge R760xs, PowerEdge R7615, PowerEdge R7625, PowerEdge R770, PowerEdge R840, PowerEdge R860, PowerEdge R940, PowerEdge R940xa, PowerEdge R960, PowerEdge RAID Controller H330, PowerEdge RAID Controller H730P, PowerEdge RAID Controller H740P, PowerEdge RAID Controller H965e Adapter, PowerEdge T340, PowerEdge T350, PowerEdge T360, PowerEdge T440, PowerEdge T550, PowerEdge T560, PowerEdge T640
...
Article Properties
Article Number: 000139251
Article Type: How To
Last Modified: 21 Feb 2025
Version: 10
Find answers to your questions from other Dell users
Support Services
Check if your device is covered by Support Services.