AMD Rome: ¿es real? Arquitectura y rendimiento inicial de HPC
Summary: En el mundo de los HPC de hoy, presentamos la última generación de procesadores EPYC de AMD, cuyo nombre en código es Rome.
This article applies to
This article does not apply to
This article is not tied to any specific product.
Not all product versions are identified in this article.
Symptoms
Garima Kochhar, Deepthi Cherlopalle, Joshua Weage. Laboratorio de innovación en HPC e IA, octubre de 2019
Cause
No corresponde
Resolution
En el mundo actual de HPC, la última generación del procesador  EPYC de AMD, cuyo nombre en código es Rome, apenas necesita presentación. Hemos estado evaluando los sistemas basados en Rome en el Laboratorio de innovación en HPC e IA en los últimos meses, y Dell Technologies anunció
EPYC de AMD, cuyo nombre en código es Rome, apenas necesita presentación. Hemos estado evaluando los sistemas basados en Rome en el Laboratorio de innovación en HPC e IA en los últimos meses, y Dell Technologies anunció  recientemente servidores que admiten esta arquitectura de procesador. En este primer blog de la serie Rome, se analizará la arquitectura del procesador Rome, cómo se puede ajustar para el rendimiento de HPC y se presentará el rendimiento inicial de los análisis comparativos. En los siguientes blogs, se describirá el rendimiento de las aplicaciones en los dominios de CFD, CAE, dinámica molecular, simulación meteorológica y otras aplicaciones.
recientemente servidores que admiten esta arquitectura de procesador. En este primer blog de la serie Rome, se analizará la arquitectura del procesador Rome, cómo se puede ajustar para el rendimiento de HPC y se presentará el rendimiento inicial de los análisis comparativos. En los siguientes blogs, se describirá el rendimiento de las aplicaciones en los dominios de CFD, CAE, dinámica molecular, simulación meteorológica y otras aplicaciones.
Arquitectura
Rome es la CPU EPYC de 2.ª generación de AMD, que actualiza la Naples de 1.ª generación. Hablamos de Nápoles en este blog el año pasado.
Una de las mayores diferencias arquitectónicas entre Nápoles y Roma que beneficia a la HPC es la nueva matriz de I/O en Roma. En Rome, cada procesador es un paquete de varios chips compuesto por hasta 9 chiplets , como se muestra en la Figura 1. Hay una matriz central de I/O de 14 nm que contiene todas las funciones de E/S y memoria: piense en controladoras de memoria, enlaces de fabric Infinity dentro del conector y conectividad entre conectores, y PCI-e. Hay ocho controladoras de memoria por conector que admiten ocho canales de memoria que ejecutan DDR4 a 3200 MT/s. Un servidor de un solo conector puede admitir hasta 130 canales PCIe de 4.ª generación. Un sistema de dos conectores puede admitir hasta 160 canales PCIe de 4.ª generación.

(Figura 1:Paquete Rome de múltiples chips con una matriz de I/O central y hasta ocho matrices de núcleo)
Alrededor de la matriz de I/O central hay hasta ocho chiplets de núcleo de 7 nm. El chiplet de núcleo se denomina matriz de caché de núcleo o CCD. Cada CCD tiene núcleos de CPU basados en la microarquitectura Zen2, caché L2 y caché L3 de 32 MB. El CCD en sí tiene dos complejos de caché de núcleo (CCX), cada CCX tiene hasta cuatro núcleos y 16 MB de caché L3. La Figura 2 muestra un CCX.
cada CCX tiene hasta cuatro núcleos y 16 MB de caché L3. La Figura 2 muestra un CCX.

(Figura 2: Un CCX con cuatro núcleos y una caché L3 compartida de 16 MB)
Los diferentes modelos  de CPU Rome tienen diferentes números de núcleos,
de CPU Rome tienen diferentes números de núcleos,  pero todos tienen una matriz de I/O central.
pero todos tienen una matriz de I/O central.
En el extremo superior se encuentra un modelo de CPU de 64 núcleos, por ejemplo, el EPYC 7702. La salida de lstopo nos muestra que este procesador tiene 16 CCX por conector, cada CCX tiene cuatro núcleos como se muestra en la Figura 3 y 4, lo que produce 64 núcleos por conector. 16 MB de L3 por CCX, es decir, 32 MB de L3 por CCD, le da a este procesador un total de 256 MB de caché L3. Sin embargo, tenga en cuenta que la caché L3 total en Rome no es compartida por todos los núcleos. La caché L3 de 16 MB en cada CCX es independiente y solo la comparten los núcleos en el CCX, como se muestra en la Figura 2.
Una CPU de 24 núcleos como el EPYC 7402 tiene 128 MB de caché L3. La salida de lstopo en las Figuras 3 y 4 ilustra que este modelo tiene tres núcleos por CCX y 8 CCX por conector.


(Figura 3 y 4 Salida lstopo para CPU de 64 y 24 núcleos)
Independientemente de la cantidad de CCD, cada procesador Rome se divide lógicamente en cuatro cuadrantes , con CCD distribuidos de la manera más uniforme posible entre los cuadrantes y dos canales de memoria en cada cuadrante. Se puede considerar que la matriz de I/O central soporta lógicamente los cuatro cuadrantes del zócalo.
Opciones de BIOS basadas en la arquitectura de Rome
El troquel de I/O central en Roma ayuda a mejorar las latencias  de la memoria con respecto a las medidas en Nápoles. Además, permite que la CPU se configure como un solo dominio NUMA, lo que permite un acceso uniforme a la memoria para todos los núcleos en el conector. Esto se explica a continuación.
de la memoria con respecto a las medidas en Nápoles. Además, permite que la CPU se configure como un solo dominio NUMA, lo que permite un acceso uniforme a la memoria para todos los núcleos en el conector. Esto se explica a continuación.
Los cuatro cuadrantes lógicos en un procesador Rome permiten particionar la CPU en diferentes dominios NUMA. Esta configuración se denomina NUMA por conector o NPS.
- NPS1 implica que la CPU Rome es un único dominio NUMA, con todos los núcleos en el conector y toda la memoria en este único dominio NUMA. La memoria se intercala en los ocho canales de memoria. Todos los dispositivos PCIe en el conector pertenecen a este único dominio de NUMA
- NPS2 divide la CPU en dos dominios NUMA, con la mitad de los núcleos y la mitad de los canales de memoria en el conector en cada dominio NUMA. La memoria se intercala a través de los cuatro canales de memoria en cada dominio de NUMA
- NPS4 divide la CPU en cuatro dominios NUMA. Cada cuadrante es aquí un dominio de NUMA y la memoria se intercala a través de los dos canales de memoria en cada cuadrante. Los dispositivos PCIe serán locales en uno de los cuatro dominios de NUMA en el conector según el cuadrante de la matriz de I/O que tenga la raíz PCIe para ese dispositivo
- No todas las CPU son compatibles con todos los ajustes de NPS
Cuando está disponible, se recomienda NPS4 para HPC, ya que se espera que proporcione el mejor ancho de banda de memoria y las latencias de memoria más bajas, y nuestras aplicaciones tienden a ser compatibles con NUMA. Cuando NPS4 no está disponible, recomendamos el NPS más alto compatible con el modelo de CPU: NPS2 o incluso NPS1.
Dada la multitud de opciones de NUMA disponibles en las plataformas basadas en Rome, el BIOS de PowerEdge permite dos métodos diferentes de enumeración de núcleos bajo la enumeración de MADT. La enumeración lineal enumera los núcleos en orden, llenando un conector CCX y CCD antes de pasar al siguiente conector. En una CPU 32c, los núcleos del 0 al 31 estarán en el primer conector y los núcleos del 32 al 63 en el segundo. La enumeración round-robin numera los núcleos en las regiones NUMA. En este caso, los núcleos con numeración par estarán en el primer conector y los núcleos con numeración impar en el segundo. Para simplificar, se recomienda la enumeración lineal para HPC. Consulte la Figura 5 para ver un ejemplo de enumeración de núcleos lineales en un servidor 64c de dos conectores configurado en NPS4. En la figura, cada caja de cuatro núcleos es un CCX, cada conjunto de ocho núcleos contiguos es un CCD.

(Figura 5 : Enumeración lineal de núcleos en un sistema de dos conectores, 64c por conector, configuración NPS4 en un modelo de CPU de 8 CCD)
Otra opción del BIOS específica de Rome se denomina Dispositivo de E/S preferido. Esta es una perilla de ajuste importante para el ancho de banda y la velocidad de mensajes de InfiniBand. Permite que la plataforma priorice el tráfico para un dispositivo de I/O. Esta opción está disponible en plataformas Rome de uno y dos conectores, y el dispositivo InfiniBand en la plataforma debe seleccionarse como el dispositivo preferido en el menú del BIOS para lograr la velocidad de mensajes completa cuando todos los núcleos de CPU estén activos.
Al igual que Naples, Rome también es compatible con hyper-threadingo procesador lógico. Para HPC, dejamos esta opción deshabilitada, pero algunas aplicaciones pueden beneficiarse de habilitar el procesador lógico. Busque nuestros blogs posteriores sobre estudios de aplicación de la dinámica molecular.
Al igual que en Nápoles, Roma también permite CCX como dominio NUMA. Esta opción expone cada CCX como un nodo NUMA. En un sistema con CPU de dos conectores con 16 CCX por CPU, esta configuración expondrá 32 dominios NUMA. En este ejemplo, cada conector tiene 8 CCD, es decir, 16 CCX. Cada CCX se puede habilitar como su propio dominio NUMA, lo que proporciona 16 nodos NUMA por conector y 32 en un sistema de dos conectores. Para HPC, se recomienda dejar CCX como dominio de NUMA en la opción predeterminada deshabilitado. Se espera que habilitar esta opción ayude a los entornos virtualizados.
Al igual que en Naples, Rome permite configurar el sistema en los modos Determinismo de rendimiento o Determinismo de alimentación . En el determinismo de rendimiento, el sistema funciona a la frecuencia esperada para el modelo de CPU, lo que reduce la variabilidad entre varios servidores. En Determinismo de alimentación, el sistema funciona con la TDP máxima disponible del modelo de CPU. Esto amplifica la variación de una pieza a otra en el proceso de fabricación, lo que permite que algunos servidores sean más rápidos que otros. Todos los servidores pueden consumir la alimentación nominal máxima de la CPU, lo que hace que el consumo de energía sea determinista, pero permite cierta variación de rendimiento entre varios servidores.
Como es de esperar de las plataformas PowerEdge, el BIOS tiene una opción de metadatos denominada Perfil del sistema. Si selecciona el perfil del sistema Rendimiento optimizado , se habilitará el modo Turbo Boost, se deshabilitarán los estados C y se establecerá el control deslizante Determinismo de alimentación en Determinismo de alimentación, con lo cual se optimizará el rendimiento.
Resultados de rendimiento: microparámetros de referencia STREAM, HPL e InfiniBand
Es posible que muchos de nuestros lectores hayan saltado directamente a esta sección, así que nos sumergiremos de lleno.
En el Laboratorio de innovación en HPC e IA, creamos un clúster de 64 servidores basado en Roma al que llamamos Minerva. Además del clúster homogéneo de Minerva, tenemos algunas otras muestras de CPU de Rome que pudimos evaluar. Nuestro banco de pruebas se describe en la Tabla 1 y en la Tabla 2.
(Tabla 1 modelos de CPU de Rome evaluados en este estudio)
| CPU | Núcleos por conector | Config | Reloj base | TDP |
|---|---|---|---|---|
| 7702 | 64 C | 4c por CCX | 2,0 GHz | 200W |
| 7502 | 32 quater | 4c por CCX | 2.5 GHz | 180W |
| 7452 | 32 quater | 4c por CCX | 2,35 GHz | 155 W |
| 7402 | 24c | 3c por CCX | 2.8 GHz | 180W |
(Tabla 2 Banco de pruebas)
| Componente | Detalles |
|---|---|
| Servidor | PowerEdge C6525 |
| Procesador | Como se muestra en la Tabla.1 Conector doble |
| Memoria | DDR4 de 256 GB, 16 x 16 GB, 3200 MT/s |
| Interconexión | ConnectX-6 Mellanox Infini Band HDR100 |
| Sistema operativo | Red Hat Enterprise Linux 7.6 |
| Núcleo | 3.10.0.957.27.2.e17.x86_64 |
| Disco | Módulo M.2 SSD SATA de 240 GB |
CORRIENTE
En la Figura 6, se presentan las pruebas de ancho de banda de memoria en Rome. Estas pruebas se ejecutaron en modo NPS4. Medimos el ancho de banda de memoria de ~270-300 GB/s en nuestro PowerEdge C6525 de dos conectores cuando se utilizaron todos los núcleos del servidor en los cuatro modelos de CPU que se enumeran en la Tabla 1. Cuando solo se utiliza un núcleo por CCX, el ancho de banda de la memoria del sistema es ~9-17 % mayor que el medido con todos los núcleos.
La mayoría de las cargas de trabajo de HPC suscribirán completamente todos los núcleos del sistema o los centros de HPC se ejecutarán en modo de alto rendimiento con varios trabajos en cada servidor. Por lo tanto, el ancho de banda de memoria de todos los núcleos es la representación más precisa del ancho de banda de memoria y las funcionalidades de ancho de banda de memoria por núcleo del sistema.
En la figura 6, también se representa el ancho de banda de memoria medido en la plataforma EPYC Naples de la generación anterior, que también admitía ocho canales de memoria por conector, pero se ejecutaba a 2667 MT/s. La plataforma Rome proporciona entre un 5 % y un 19 % más de ancho de banda de memoria total que Naples, y esto se debe principalmente a una memoria más rápida de 3200 MT/s. Incluso con 64c por conector, el sistema Rome puede entregar más de 2 GB/s/núcleo.
NOTA: Se midió una variación de rendimiento del 5 al 10 % en los resultados de STREAM Triad en varios servidores con sede en Roma configurados de manera idéntica; por lo tanto, se debe suponer que los resultados a continuación son el extremo superior del rango.
Al comparar las diferentes configuraciones de NPS, se midió un ancho de banda de memoria ~13 % mayor con NPS4 en comparación con NPS1, como se muestra en la Figura 7.

(Figura 6 : Ancho de banda de memoria de la tríada NPS4 STREAM de dos conectores)

(Figura 7 NPS1 frente a NPS2 frente a NPS 4 Ancho de banda de memoria)
Ancho de banda y velocidad de mensajes de InfiniBand
En la Figura 8 se representa el ancho de banda InfiniBand de un solo núcleo para pruebas unidireccionales y bidireccionales. El banco de pruebas utilizó HDR100 que se ejecuta a 100 Gbps y el gráfico muestra el rendimiento de velocidad de línea esperado para estas pruebas.

Figura 8 Ancho de banda de InfiniBand (un núcleo)
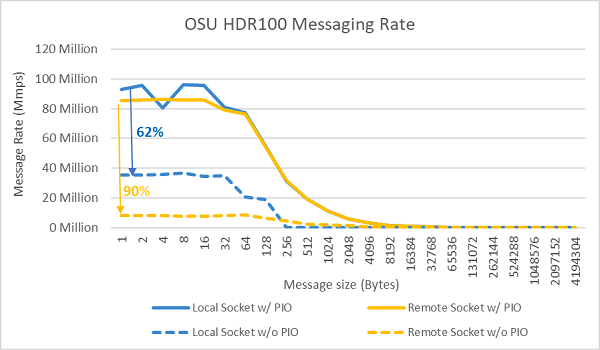
Figura 9 Velocidad de mensajes InfiniBand (todos los núcleos)
A continuación, se realizaron pruebas de velocidad de mensajes utilizando todos los núcleos de un conector en los dos servidores sometidos a prueba. Cuando la I/O preferida está habilitada en el BIOS y el adaptador ConnectX-6 HDR100 está configurado como el dispositivo preferido, la velocidad de mensajes de todos los núcleos es significativamente mayor que cuando la I/O preferida no está habilitada, como se muestra en la Figura 9. Esto ilustra la importancia de esta opción de BIOS cuando se ajusta para HPC y, especialmente, para la escalabilidad de aplicaciones de múltiples nodos.
HPL
La microarquitectura Rome puede retirar 16 DP FLOP/ciclo, el doble que Naples, que era de 8 FLOPS/ciclo. Esto le da a Roma 4 veces el pico teórico de FLOPS sobre Nápoles, 2 veces desde la capacidad de punto flotante mejorada y 2 veces desde el doble de núcleos (64c frente a 32c). En la figura 10, se muestran los resultados de HPL medidos para los cuatro modelos de CPU Rome que probamos, junto con nuestros resultados anteriores de un sistema basado en Naples. La eficiencia de Rome HPL se indica como el valor porcentual por encima de las barras en el gráfico y es mayor para los modelos de CPU TDP más bajos.
Las pruebas se ejecutaron en modo de determinismo de alimentación y se midió un delta de ~5 % en el rendimiento en 64 servidores configurados de manera idéntica; los resultados aquí se encuentran en esa banda de rendimiento.

(Figura 10 : HPL de un solo servidor en NPS4)
A continuación, se ejecutaron pruebas de HPL de múltiples nodos y esos resultados se representan en la Figura 11. Las eficiencias de HPL para EPYC 7452 se mantienen por encima del 90 % en una escala de 64 nodos, pero las caídas en la eficiencia del 102 % al 97 % y de vuelta al 99 % necesitan una evaluación adicional

(Figura 11 : HPL de múltiples nodos, EPYC 7452 de dos conectores sobre InfiniBand HDR100)
Resumen y lo que viene a continuación
Los estudios de rendimiento iniciales en servidores basados en Rome muestran el rendimiento esperado para nuestro primer conjunto de parámetros de referencia de HPC. El ajuste del BIOS es importante cuando se configura para obtener el mejor rendimiento, y las opciones de ajuste están disponibles en nuestro perfil de carga de trabajo de HPC del BIOS que se puede configurar en la fábrica o establecer mediante las utilidades de administración de sistemas de Dell EMC.
El Laboratorio de innovación en HPC e IA tiene un nuevo clúster de PowerEdge Minerva de 64 servidores basado en Roma. Esté atento a este espacio para ver los siguientes blogs que describen los estudios de rendimiento de las aplicaciones en nuestro nuevo clúster Minerva.
Article Properties
Article Number: 000137696
Article Type: Solution
Last Modified: 31 Jan 2025
Version: 7
Find answers to your questions from other Dell users
Support Services
Check if your device is covered by Support Services.