Article Number: 000124616
使用 TF 和 Horovod 优化多个 GPU 上工作流的提示和技巧
Summary: 本文详细介绍了使用 TF 和 Horovod 优化多个 GPU 上工作流的提示和技巧。
Article Content
Symptoms
-
Cause
-
Resolution
本文由 HPC AI 创新实验室的 Rakshith Vasudev 和 John Lockman 于 2019 年 10 月撰写
简介
Horovod 是一种分布式深度学习框架,可加快对 Tensorflow、Keras、Pytorch 和 MXNet 等其他深度学习框架的培训。开发它的目的是为了更轻松地建立分布式深度学习项目并利用 TensorFlow 加快项目的速度。Horovod 支持并行化培训过程。它支持数据并行化和模型并行化。当使用 horovod 的神经网络训练作业正在运行时,这些常见提示可用于调试和查看性能改进。
描述
本文以 CheXNet 为例,以供参考。CheXNet 是一种人工智能放射科医师辅助模型,可利用 DenseNet 从给定的胸部 x 射线图像中识别多达 14 类病理。
- 在尝试调试性能问题时,正确的环境设置可以节省大量时间。请确保正在使用深度学习框架的 GPU 版本。在此示例中,使用的是由 anaconda 打包的 tensorflow-gpu。
-
将 horovodrun 或 mpirun 与绑定参数一起使用可以提高性能。理想情况下,控制 GPU 的进程应绑定到最接近的 CPU 插槽。在 Dell EMC PowerEdge C4140 上,最佳选项是 --map-by socket。无需指定任何绑定选项。
它类似于以下内容:
mpirun --map-by socket -np x python pyfile.py - -pyoptions
- 作业的设置应使一个 MPI 进程在一个 GPU 上进行处理。如果进程数超过 GPU 数量,这些进程将争夺计算资源,并且无法以良好的性能运行作业。在以上示例中,x 应等于要使用的 GPU 数。
-
要设置每 GPU 一个进程,请使用 tensorflow 的 ConfigProto(),如下所示:
config.gpu_options.visible_device_list=str(hvd.local_size())
-
要检查使用 GPU 的进程数,可以使用“watch nvidia-smi”查看 GPU 显存使用情况。它还允许查看功耗。
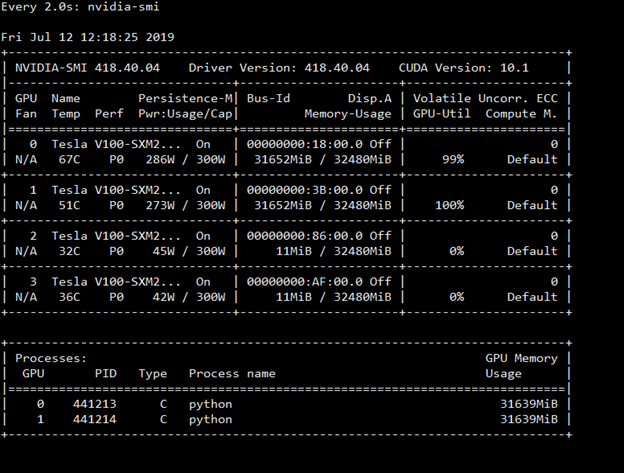
图 1:nvidia-smi 命令输出的屏幕截图,显示显存、电源和 GPU 利用率。
- 如果数据管道设置正确且 mpirun 参数正确,则在模型训练开始后,GPU 利用率应持续超过 90%。利用率偶尔降低到 10-25% 是可以接受的,但不应频繁出现这种情况。
- 设置批大小,以使其几乎占满 GPU 内存,但限制为最大不应超过内存要求。必须要考虑学习速率缩放的完成方式。学习速率缩放是一种概念,即随着 GPU 数量的增加,学习速率也必须乘以一个与 GPU 数量成正比的系数。这使模型可以有效地收敛。这样,在不牺牲模型收敛的情况下,通过将可能的最大图像数拟合到 GPU 来减少 I/O 操作的数目。必须注意的是,在分布式工作负载环境中,学习速率缩放并不是改善模型收敛性的最佳解决方案。
要检查是否需要进行学习速率缩放,请执行以下操作:
a) 在分布式模式下训练具有和不具有学习速率缩放的模型。
b) 如果不具有学习速率缩放的模型比具有学习速率缩放的模型表现更好,则不需要学习速率缩放。
尤其是在进行收敛性训练时,并非总是用一个强制规则来适应每批图像的最大可能数量。通常在批大小和收敛性(是否使用了学习速率缩放)之间存在一个折衷,数据科学家必须能够根据其用例来决定。
此外,您还可以使用“watch nvidia-smi”查看 GPU 显存使用情况。 在此案例研究中,未使用学习速率缩放,因为它使用 AUC 值且局部小批量大小为 64 生成了一个更好的模型。使用学习速率缩放时,通常要具有本文所述的典型预热阶段。
-
使用 horovod timeline 和 nvprof 来配置您的作业,以查看可能发生的任何瓶颈。 瓶颈很可能是由以下原因之一所致:
a) Tf 数据管道未设置好,因此需要花费大量时间来准备数据,而加速器则处于空闲状态。要解决此问题,必须更正 tf 管道。
请阅读本文,了解有关如何设置 tf 数据管道的信息。
b) 通信可能未使用正确的结构 — 请确保您使用的是 InfiniBand,以在运行 mpirun 时,包括 -x NCCL_DEBUG=INFO 来查看结构使用情况,如下所示:
mpirun -np 8 --map-by socket -x NCCL_DEBUG=INFO python $HOME/models/chexnet/chexnet.py --batch_size=128 --epochs=15
或使用 horovodrun,其中包括 –x binding。
- 要正确实施分发,GPU 需要有效地相互通信。如果无法有效地进行通信,则会导致通信瓶颈。要检查它们是否处于最佳通信状态,请使用以下过程:
首先,如上文第 8b 点所示,通过使用 -x binding 来了解 GPU 的通信方式
如果 GPU 正在通信:1) 在节点内,最佳方式如下所示:gpu002:1299562:1299573 [0] NCCL INFO Ring 00 : 0[0] -> 1[1] via P2P/IPC2) 在节点外,最佳方式如下所示:gpu028:149460:149495 [0] NCCL INFO Ring 01 : 16 -> 0 [send] via NET/IB/0gpu009:164181:164216 [0] NCCL INFO Ring 01 : 12 -> 8 [receive] via NET/IB/0gpu009:164181:164216 [0] NCCL INFO Ring 01 : 4 -> 8 [receive] via NET/IB/0
分发您的深度学习作业有时会颇具挑战性,特别是当使用的节点/GPU 的数量不能有效地转化为相应的性能时更是如此。为确保可从您的加速器投资中获得最大价值,请确保实施以下最佳做法:
- 正确的绑定选项已就位,
- 评估不会浪费 GPU 显存的多个进程,
- 使用现代流水线方法,
- 进行配置以查看 GPU 在作业运行时至少使用了 80%,
- 使用最新 CUDA 相关库
Article Properties
Affected Product
High Performance Computing Solution Resources, Poweredge C4140
Last Published Date
17 Sep 2021
Version
4
Article Type
Solution