Dell VxRail Cluster에서 vCenter를 사용하여 디스크를 수동으로 교체하는 방법 가이드
Summary: vCenter를 사용하여 장애가 발생한 디스크를 식별하고, 디스크 또는 디스크 그룹을 제거하고, 장애가 발생한 디스크를 물리적으로 교체하고, 새 디스크를 로컬로 표시하고, 새 디스크 또는 디스크 그룹을 추가하는 단계별 가이드입니다.
This article applies to
This article does not apply to
This article is not tied to any specific product.
Not all product versions are identified in this article.
Instructions
고려사항
가능한 경우 SolVe 절차에 따라 디스크를 교체해야 합니다. 승인된 당사자는 SolVe Online 포털에서 이러한 절차에 액세스할 수 있습니다.vCenter Web Client를 사용하여 드라이브를 수동으로 교체하는 단계는 일반적으로 볼 수 있습니다. VXRM 데이터베이스를 수동으로 업데이트하는 단계는 Dell Technologies 직원 및 파트너만 볼 수 있습니다.
고객, 현장 지원 등에서 CRU(Customer Replaceable Unit)로 배송된 교체 디스크에 대한 지원이 필요한 경우 VxRail Manager의 하드웨어 교체 옵션에 장애가 발생했거나 사용할 수 없는 경우 VxRail Remote Support의 SR을 열고 이 문서를 참조하십시오. 권장되는 SR은 'Hardware' 유형으로 설정된 심각도 2 또는 3입니다. 적절한 SR 요약은 다음과 같습니다. 'VxRail drive replacement, assistance from VxRail Support is needed'.
드라이브 장애에 대한 세 가지 가능한 시나리오가 있으며 드라이브를 제거하고 vSAN에 다시 추가할 때 다양한 접근 방식이 있습니다.
드라이브 장애에 대한 세 가지 가능한 시나리오가 있으며 드라이브를 제거하고 vSAN에 다시 추가할 때 다양한 접근 방식이 있습니다.
- 용량 드라이브에 장애가 발생했습니다(디스크 제거에 대한 자세한 내용은 2단계 참조).
- 캐시 드라이브에 장애가 발생했습니다(디스크 그룹 제거 자세한 내용은 2단계 참조. 이렇게 하면 vSAN에서 모든 드라이브가 제거되며 나중에 새로 생성된 디스크 그룹에 추가해야 합니다. 자세한 내용은 5단계 참조)
- 캐시 또는 용량 드라이브에 장애가 발생했으며 중복 제거 및 압축 옵션이 활성화되었습니다 (디스크 그룹 제거. vSAN에서 모든 드라이브가 제거되며 나중에 새로 생성된 디스크 그룹에 추가해야 합니다. 자세한 내용은 5단계 참조).
1단계. 장애가 발생한 디스크 식별:
장애가 발생한 디스크를 알 수 없는 경우 물리적 슬롯을 식별하는 방법(예: vCenter는 디스크를 장애로 표시했지만 iDRAC/VxRail Manager는 표시하지 않은 경우)
vCenter Client를 사용하여 장애가 발생한 디스크를 식별할 수 있습니다.
- 호스트 및 클러스터 보기를 클릭합니다.
- 왼쪽 창에서 클러스터 수준을 클릭합니다.
- Configure(Manage) > vSAN > Disk Management를 클릭합니다.
- Disk Groups 패널에서 장애가 발생한 디스크가 있는 디스크 그룹을 찾고 해당 디스크 그룹을 클릭하여 아래의 Disk Group Disks 섹션에 개별 디스크를 표시합니다.
- 장애가 발생한 디스크를 식별 및/또는 확인하기 위한 두 가지 옵션이 있습니다.
- LED 깜박임을 통한 식별:

- Disk Group Disks 섹션에서 장애가 발생한 디스크를 클릭합니다.
- 그런 다음 세 점(...)을 클릭하고 LED 켜기를 선택합니다.
- naa 번호를 통한 식별:
- LED 깜박임을 통한 식별:
참고: 장애가 발생한 디스크는 일반적으로 naa 대신 vSAN UUID를 표시합니다.
- SSH를 통해 호스트에 연결하고 vSAN UUID와 일치시켜 디스크의 naa. #을 vSAN UUID와 일치시켜 제거합니다.
# vdq -qH
가능한 경우 naa # 및 vSAN UUID를 모두 표시합니다.

# esxcli vsan storage list
다음과 같은 경우 디스크 그룹의 naa #, vSAN UUID 및 UUID를 표시합니다.

둘 다 연결된 vSAN UUID에 대한 naa #를 표시할 수 없는 경우 아래 방법을 사용하여 제거 프로세스를 사용하여 디스크의 naa를 확인할 수 있습니다.
- 숫자의 마지막 4-6 숫자를 기록하는 디스크 그룹에 있는 다른 디스크의 naa 번호를 확인합니다. 호스트에 여러 디스크 그룹이 있는 경우 모든 디스크 그룹에 대해 이 작업을 수행합니다.
- VxRail Manager의 물리적 호스트 보기에서 vCenter의 naa 번호를 VxRail Manager의 GUID 번호와 연결합니다.
- 목록에 없는 naa. #가 있는 디스크를 찾을 때까지 검색합니다. 이것이 장애가 발생한 디스크입니다.
2단계. 디스크 또는 디스크 그룹 제거:
사전 검사:
이러한 종류의 유지 보수를 수행하기 전에 서비스 VM을 포함한 모든 VM(Virtual Machine)에 최신 백업(클러스터 제외)이 있는지 확인하는 것이 '모범 사례'입니다. 시작하기 전에 장애가 발생하여 교체할 드라이브와 관련된 알림을 제외하고 클러스터의 상태는 양호해야 합니다. vSAN에 수정이 필요한 하나 이상의 디스크 그룹 없이 전체 기능을 수행할 수 있는 충분한 공간이 없는 경우 이 절차를 수행해서는 안 됩니다 .
- vCenter 웹 클라이언트의 '호스트 및 클러스터' 보기에서 Ensure Accessibility를 사용하여 호스트를 유지 보수 모드로 전환합니다. 호스트를 마우스 오른쪽 버튼으로 클릭하고 유지 보수 모드 시작을 클릭합니다.

- 클러스터를 선택하고 Configure(또는 이전 버전에서는 'Manage') > SettingsDisk > Management로 이동합니다. (여기에서 이전 디스크 제거)
-
디스크 그룹에서 디스크를 제거하는 방법:
-
참고: 고객이 중복 제거 및 압축을 사용하는 경우 개별 용량 드라이브를개별적으로 제거/교체할 수 없으므로 디스크 그룹을 제거한 후 다시 생성해야 합니다. 디스크 그룹을 다시 생성하지 않고 중복 제거 및 압축된 디스크 그룹에 더 많은 용량의 드라이브를 추가할 수 있습니다.
참고: 장애가 발생한 드라이브가 캐시 계층 드라이브인 경우 디스크 그룹을 제거하고 다시 생성해야 합니다.
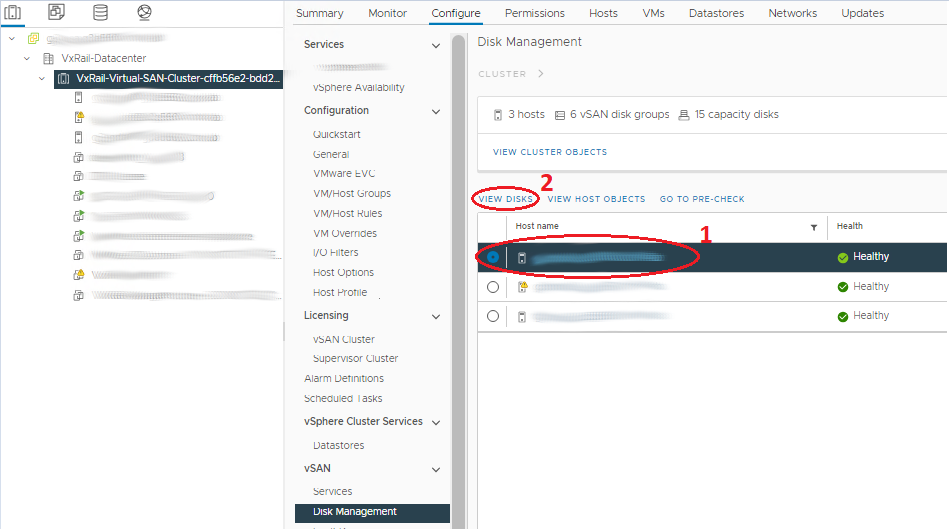
- Disk Groups 패널에서 올바른 호스트로 스크롤하고 장애가 발생한 디스크가 있는 디스크 그룹을 선택합니다.
- 호스트 목록 위에는 디스크 보기 버튼이 있습니다.
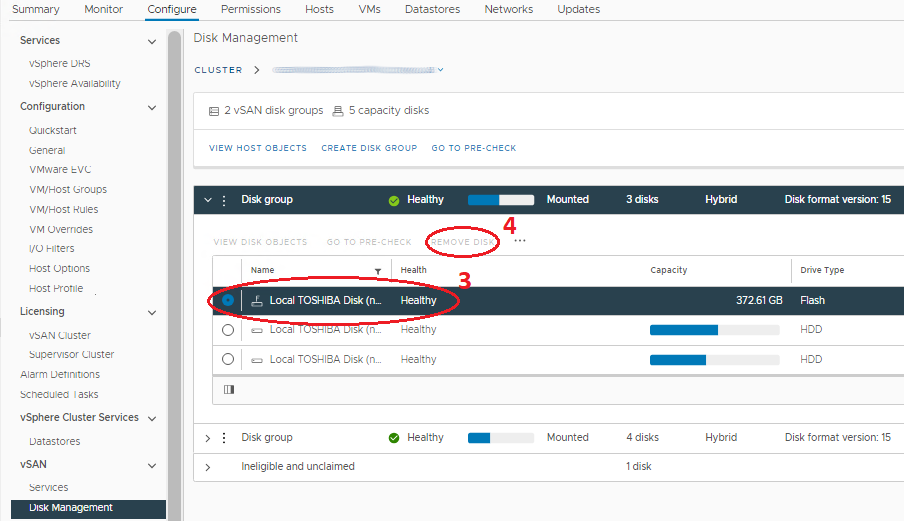
- 영향을 받는 드라이브가 있는 디스크 그룹에서 드라이브 목록을 열고 선택합니다.
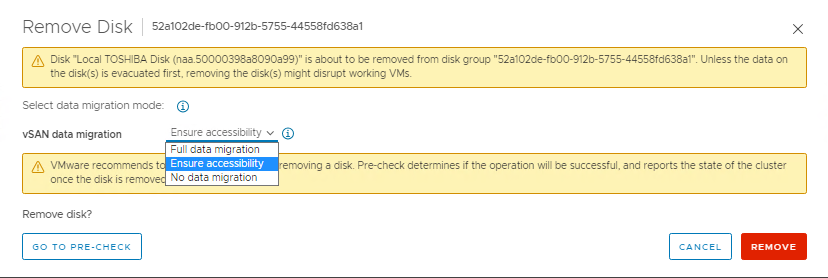
- 드라이브 목록 위에 있는 Remove disk 버튼을 클릭합니다. 'Full Data Migration', 'Ensure Accessibility' 및 'No Data Migration' 옵션이 있는 창이 표시됩니다(문구는 버전에 따라 다름). 호스트는 위의 1단계에서 'Ensure Accessibility'를 사용하여 이미 유지 보수 모드에 있어야 하므로 전체 호스트의 모든 VM 오브젝트 데이터에 복사본이 있거나 클러스터의 다른 위치에 있어야 합니다. 이 부분의 경우 'No Data Migration'을 선택합니다. 그런 다음 제거를 클릭합니다.
- 'Remove disks from use by Virtual SAN' 작업이 완료될 때까지 기다립니다. MonitorTasks > 로 이동하여 진행 상황을 확인합니다.
-
전체 디스크 그룹을 제거하는 방법:
장애가 발생한 드라이브가 캐시 계층 드라이브인 경우 디스크 그룹을 제거하고 다시 생성해야 합니다.- Disk Groups 패널에서 올바른 호스트로 스크롤하고 장애가 발생한 디스크가 포함된 디스크 그룹을 선택합니다.
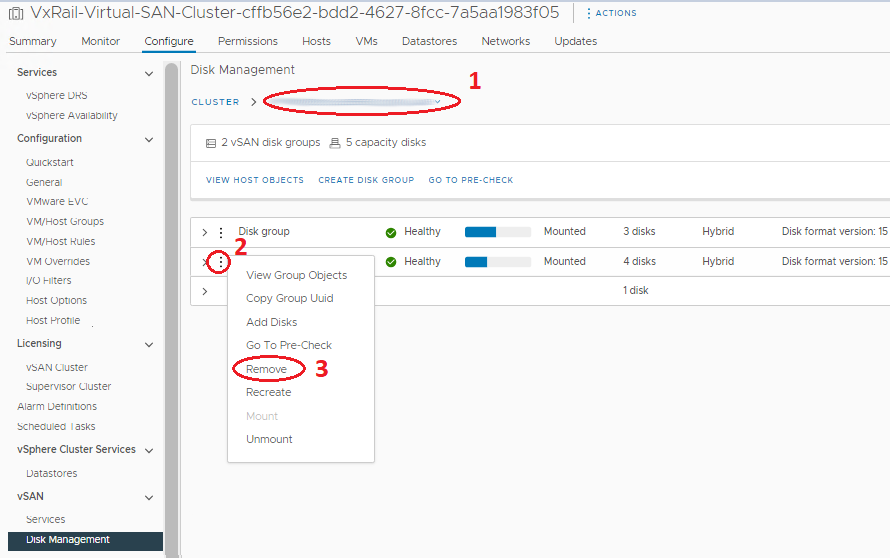
- 올바른 디스크 그룹을 선택하고 그 앞의 세 지점을 클릭합니다.
- Menu에서 Remove를 클릭합니다. 'Full Data Migration', 'Ensure Accessibility' 및 'No Data Migration' 옵션이 있는 창이 표시됩니다(문구는 버전에 따라 다름). 호스트는 위의 1단계에서 'Ensure Accessibility'를 사용하여 이미 유지 보수 모드에 있어야 하므로 전체 호스트의 모든 VM 오브젝트 데이터에 복사본이 있거나 클러스터의 다른 위치에 있어야 합니다. 이 부분의 경우 'No Data Migration'을 선택합니다. 그런 다음 제거를 클릭합니다.
- 'Remove disks from use by Virtual SAN' 작업이 완료될 때까지 기다립니다. MonitorTasks > 로 이동하여 진행 상황을 확인합니다.

3단계. 장애가 발생한 디스크를 물리적으로 교체합니다.
SolVe 절차에는 안전 지침 및 이 단계를 수행하는 방법에 대한 정보가 있습니다. 교체 드라이브는 일반적으로 캐리어와 함께 제공되지 않으므로 장애가 발생한 디스크에서 캐리어를 분리하고 교체 디스크를 그 안에 배치해야 합니다. I/O 트래픽이 발생할 수 있는 동안 실수로 잘못된 드라이브를 분리하지 않도록 이 단계에서 호스트는 여전히 MM에 있어야 합니다. 위험을 더 줄이려면 드라이브를 물리적으로 교체하기 전에 호스트의 전원을 끄십시오. 단, 필수는 아닌 것으로 간주합니다.
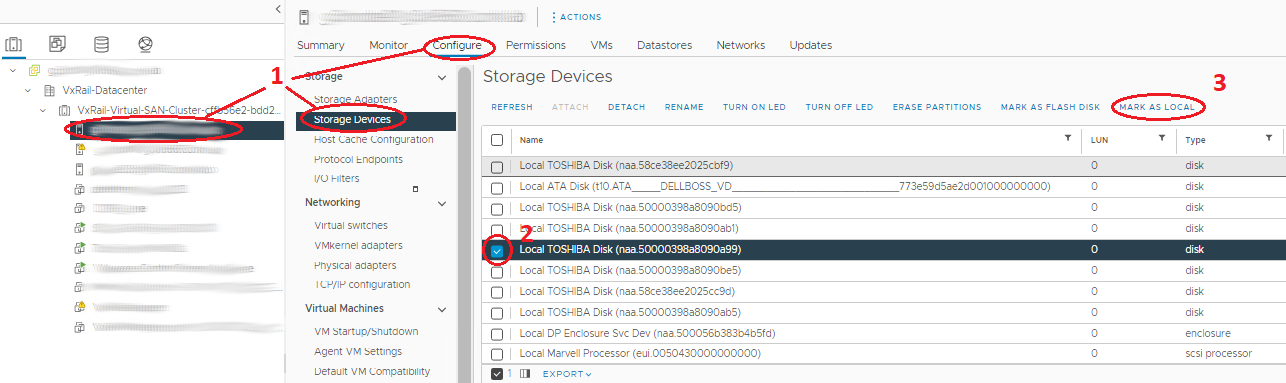
4단계. 새 디스크를 로컬로 표시:
- 탐색기에서 호스트를 선택하고 ManageStorageStorage >> Devices로 이동합니다.
- 'Storage Devices' 가운데 패널에서 올바른 디스크를 선택합니다. Type disk가 있고 데이터 저장소가 할당되지 않은 디바이스여야 합니다.
- 위에서 올바른 옵션을 선택하여 디바이스를 로컬로 표시합니다. 사용 가능한 옵션이 'Remote'로 표시되는 경우 디스크가 이미 로컬에 있는 것입니다.
5단계. 새 디스크 또는 디스크 그룹 추가:
디스크를 추가하거나 디스크 그룹을 다시 생성하기 전에 디스크가 로컬로 표시되어 있는지 확인합니다.
- 클러스터를 선택하고 Configure(또는 이전 버전의 경우 'Manage') > SettingsDisk > Management로 이동합니다. (여기에서 새 디스크 추가)
-
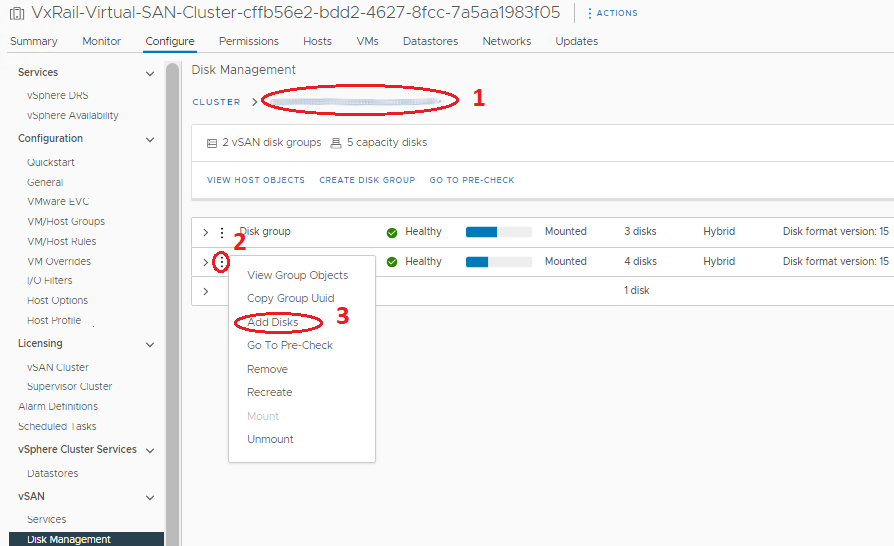
디스크 그룹에 디스크를 추가하는 방법:
-
참고: 디스크 그룹을 다시 생성하지 않고 중복 제거 및 압축된 디스크 그룹에 추가 용량의 드라이브를 추가할 수 있습니다.
- Disk Groups 패널에서 올바른 호스트로 스크롤하고 새 디스크를 추가할 디스크 그룹을 선택합니다.
- 올바른 디스크 그룹을 선택하고 그 앞의 세 지점을 클릭합니다.
- 나타나는 메뉴에서 Add Disks를 선택합니다. 디스플레이 창에서 드라이브를 표시하고(드라이브가 이 창에 표시되지 않으면 드라이브가 로컬로 표시되어 있는지 확인) Add를 클릭합니다.
- 'Add disks for use by Virtual SAN' 작업이 완료될 때까지 기다립니다. MonitorTasks > 로 이동하여 진행 상황을 확인합니다.
- 페이지 상단에서 새로 고치고 디스크 그룹이 올바르게 표시되는지 확인합니다(사용 중인 디스크에는 정확한 번호가 있고 상태는 Mounted로 표시됨).
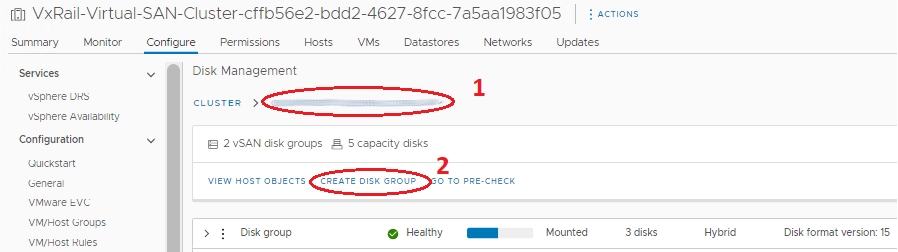
- 전체 디스크 그룹을 추가하거나 다시 생성하는 방법:
- Disk Groups 패널에서 디스크 그룹이 생성된 올바른 호스트로 스크롤합니다.
- Disk Groups 패널 위에서 Create Disk Group 버튼을 클릭합니다.
- 나타나는 창의 Cache Tier 섹션에서 캐시 디스크를 선택하고 Capacity Tier 섹션에서 용량 드라이브를 하나 이상 선택한 다음 'OK'를 클릭합니다.
- 'Add disks for use by Virtual SAN' 작업이 완료될 때까지 기다립니다. MonitorTasks> 로 이동하여 진행 상황을 확인합니다.
- 페이지 상단에서 새로 고치고 디스크 그룹이 올바르게 표시되는지 확인합니다(사용 중인 디스크에는 정확한 번호가 있고 상태는 Mounted로 표시됨).
참고: 이 시점에서 vCenter 및 호스트는 'In Use for VSAN' 및 정상 상태의 디스크를 표시해야 합니다. VxRail Manager 데이터베이스에는 교체된 이전 디스크에 대한 오래된 정보가 계속 유지되어 Physical Health 페이지에 누락된 디스크가 표시됩니다. 이제 VxRail Manager도 수동으로 업데이트하여 이전 드라이브를 제거하고 새 드라이브를 데이터베이스에 추가하여 Physical Health 상태인 새 드라이브를 표시할 수 있습니다. VxRail 지원에서는 서비스 요청을 통해 이 절차를 수행할 수 있습니다.
Additional Information
관련 자료
다음은 사용자가 관심 있을 만한, 이 주제와 관련된 몇 가지 권장 리소스입니다.
- Dell VxRail: esxcli 명령을 사용하여 vSAN 디스크 그룹을 수동으로 제거하고 다시 생성하는 방법
- Dell VxRail: VxRail Manager 플러그인의 물리적 보기에서 전원 공급 장치 또는 디스크를 연결할 수 없음
- Dell VxRail: 디스크를 교체한 후 VxRail 플러그인의 물리적 보기에 디스크 슬롯이 관리되지 않음으로 표시되고 드라이브 구성이 비어 있음
- Dell VxRail: vSAN 개체에 액세스할 수 없음, 디스크 장애, 과도한 I/O 레이턴시, 디스크 전체 상태 빨간색
- Dell VxRail: VxRail Manager 루트 암호를 분실했습니다.
이 비디오를 참조하십시오 :
YouTube에서이 비디오를 볼 수도 있습니다.
Affected Products
VxRail, VxRail Appliance SeriesProducts
VxRail 460 and 470 Nodes, VxRail Appliance Family, VxRail G410, VxRail G Series Nodes, VxRail E Series Nodes, VxRail E460, VxRail E560, VxRail E560F, VxRail G560, VxRail G560F, VxRail P470, VxRail P570, VxRail P570F, VxRail S470, VxRail S570
, VxRail V470, VxRail V570, VxRail V570F
...
Article Properties
Article Number: 000019481
Article Type: How To
Last Modified: 25 Apr 2024
Version: 20
Find answers to your questions from other Dell users
Support Services
Check if your device is covered by Support Services.