PowerScale、Isilon OneFS: 「Isilon:IsilonでのHBaseパフォーマンス テスト(英語)」
Summary: この記事では、Yahoo Cloud Serving Benchmarking (YCSB) SuiteとCloudera Data Hub (CDH) 5.10を使用した、Isilon X410クラスターでのパフォーマンス ベンチマーク テストについて説明します。
This article applies to
This article does not apply to
This article is not tied to any specific product.
Not all product versions are identified in this article.
Symptoms
不要
Cause
不要
Resolution
メモ: このトピックは、OneFSでのHadoopの使用に関する情報ハブの一部です。
概要
YCSBベンチマーキング スイートとCDH 5.10.
を使用して、Isilon X410クラスターで一連のパフォーマンス ベンチマーク テストを実行しましたラボ テスト環境は、OneFS v8.0.0.4およびv8.0.1.1以降を実行する5つのIsilon x410ノードで構成されました。Network File System(NFS)ラージ ブロック ストリーミング ベンチマークが実行されました。テストで予想される理論上の最大値は、ノードあたり~700 MB/秒(3.5 GB/秒)の書き込みと~1 GB/秒の読み取り(5 GB/秒)でした
(9)コンピューティング ノードは、CentOS v7.3.1611を実行しているDell PowerEdge FC630サーバーで、それぞれ2x18C/36TインテルXeon® CPU E5-2697 v4 @ 2.30GHzと512GBのRAMで構成されています。ローカル ストレージは、オペレーティング システムとスクラッチ スペースまたはスピル ファイルの両方に対してXFSとしてフォーマットされたRAID 1の2xSSDです。
また、YCSBの負荷を駆動するために使用された3台の追加のエッジ サーバーもありました
コンピューティング ノードとIsilon間のバックエンド ネットワークは10 Gbpsで、NICとスイッチ ポートにジャンボ フレームが設定されています(MTU=9162)。
Hadoopテスト構成のコンポーネント(図1)
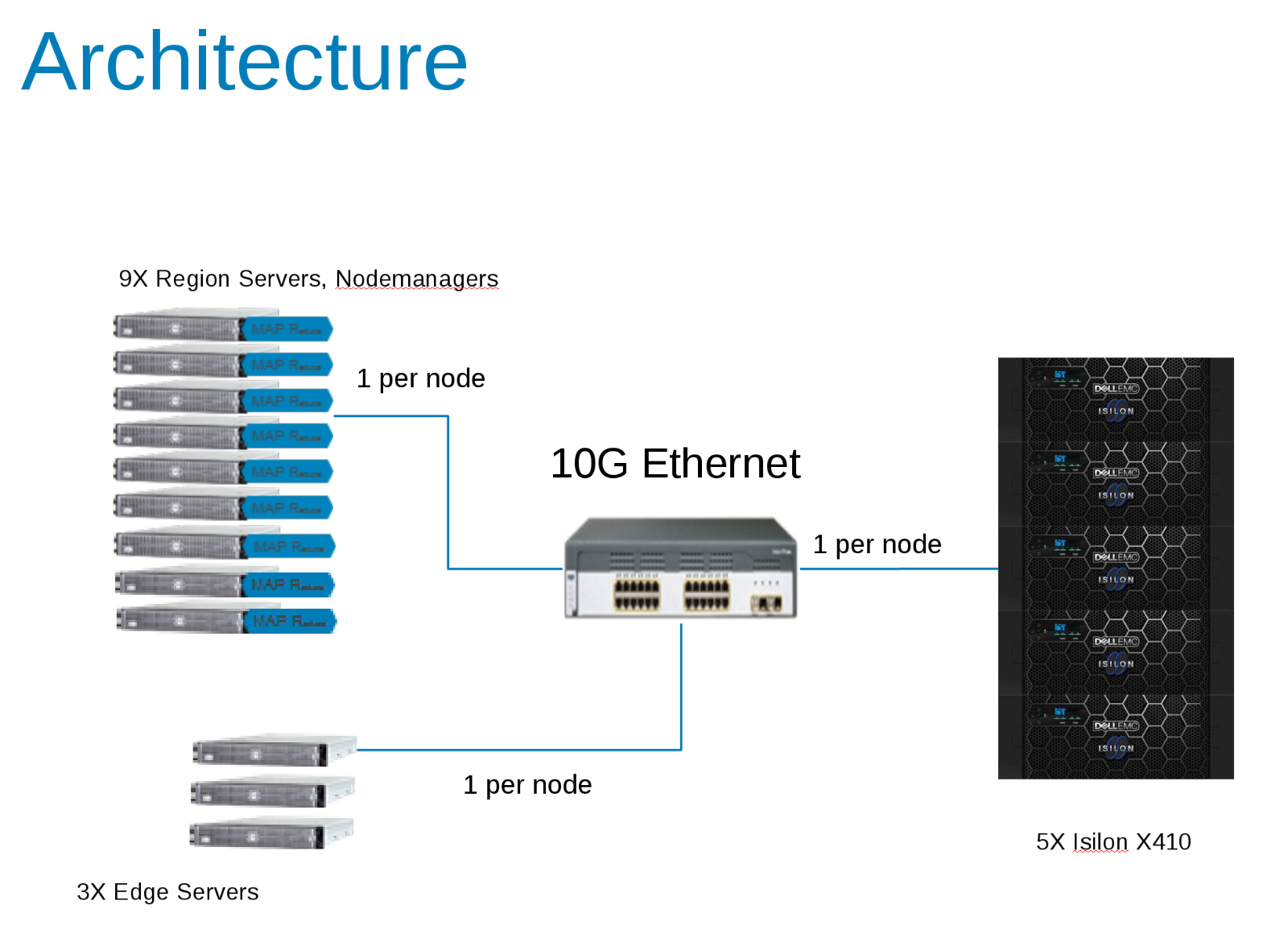
CDH 5.10は、Isilon Cluster上のアクセス ゾーンで実行するように構成されました。サービス アカウントは、Isilonローカル プロバイダーと、ローカルのクライアント/etc/passwdファイルで作成されました。すべてのテストは、特別な権限のない基本的なテストクライアントを使用して実行されました。
Isilonの統計情報は、IIQとGrafana/Data Insightsパッケージの両方で監視されました。CDH統計は、Cloudera ManagerとGrafanaを使用して監視しました。
初期テスト
最初の一連のテストでは、全体的な出力に影響を与えるHBASE側の関連パラメーターを特定しました。YCSB ツールを使用して、HBASE の負荷を生成しました。この初期テストは、YCSBと4,000万行の「ロード」フェーズを使用して、単一のクライアント(エッジサーバー)を使用して実行されました。このテーブルは、各実行の前に削除されました。
ycsb load hbase10 -P workloads/workloada1 -p table='ycsb_40Mtable_nr' -p columnfamily=family -threads 256 -p recordcount=40000000
- hbase.regionserver.maxlogs - Write-Ahead Log (WAL) ファイルの最大数 - この値に HDFS ブロック サイズ (dfs.blocksize) を掛けたものが、サーバーがクラッシュしたときに再生する必要がある WAL のサイズです。この値は、ディスクへのフラッシュの頻度に反比例します。
- hbase.wal.regiongrouping.numgroups - 複数のHDFS WALをWALProviderとして使用する場合、各RegionServerが実行する先行書き込みログの数を設定します。結果には、HDFSパイプラインの数が表示されます。特定のリージョンの書き込みは 1 つのパイプラインにのみ送信され、RegionServer の負荷の合計が分散されます。
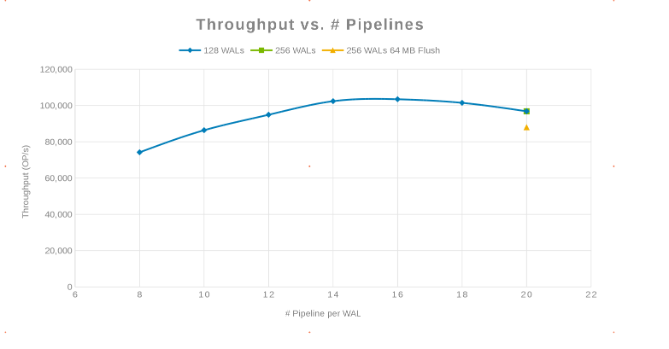
パイプラインの数と比較したスループット(図2)
パイプライン数と比較したレイテンシー(図3)
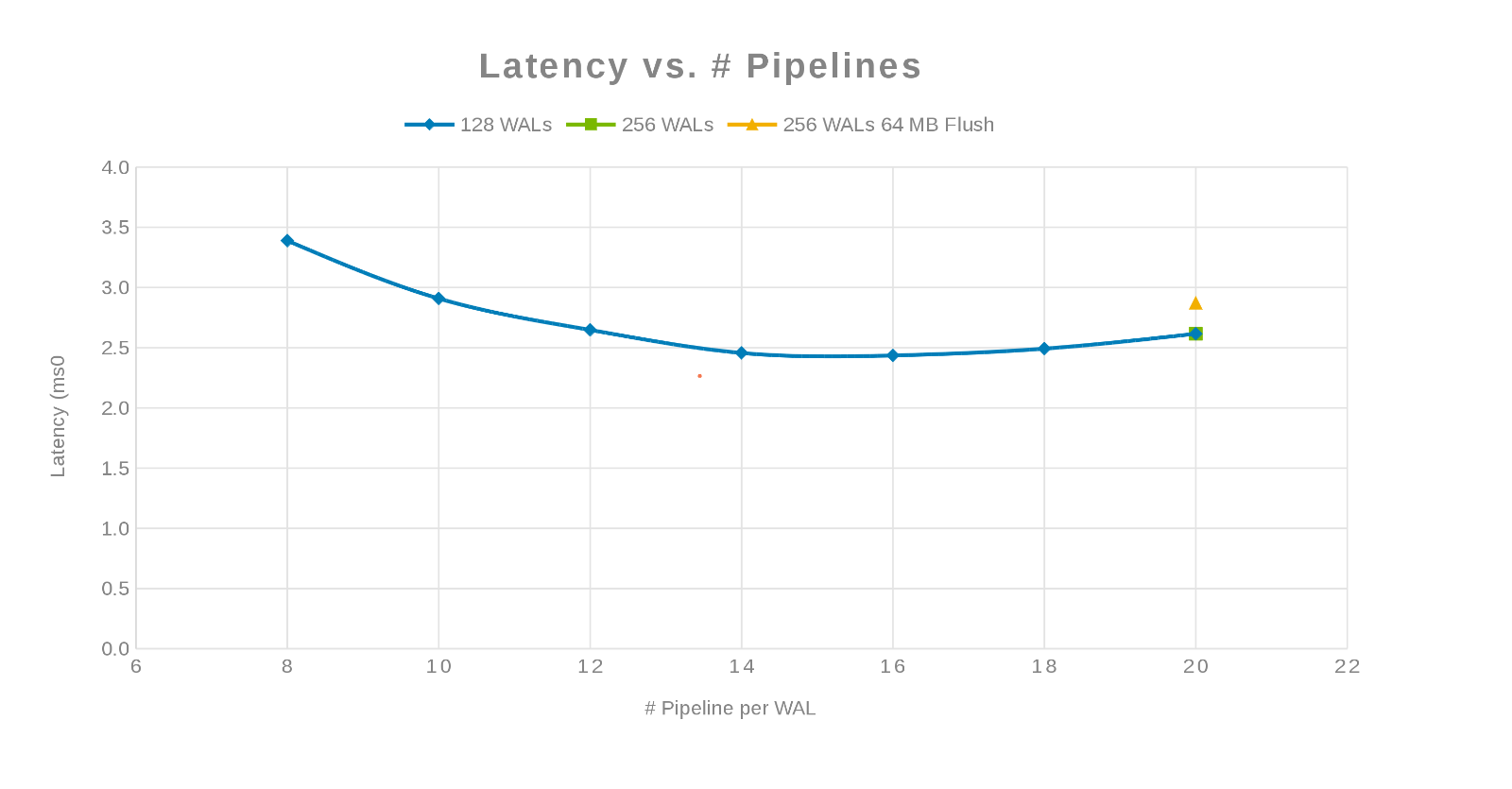
ここでの哲学は、できるだけ多くの書き込みを並列化することでした。WALの数を増やしてから、WALあたりのスレッド(パイプライン)の数を増やすことで、これを実現できます。前の 2 つのグラフは、「maxlogs」の特定の数 (128 または 256) に対して、実際の変化が示されていないことを示しています。これは、テストがクライアント側からの結果に実際には影響を与えていないことを示します。ファイルあたりの「パイプライン」の数にばらつきがあり、パラメーターが並列化の影響を受けやすい傾向が見られました。次の質問は、ディスクI/O、ネットワーク、CPU、OneFSのいずれかで、Isilonクラスターが「邪魔になる」点です。この質問に答えるには、Isilon統計レポートを参照してください。
テスト中のIsilonネットワークの使用率と負荷(図4)
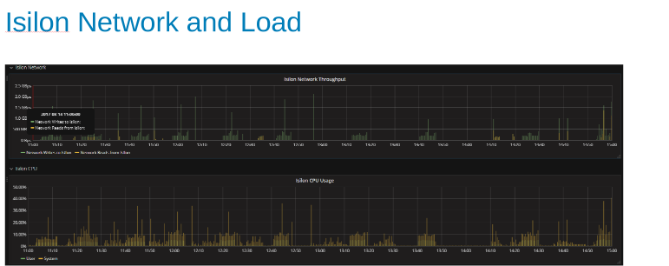
ネットワークとCPUのグラフは、Isilonクラスターが十分に活用されておらず、より多くの作業の余地があることを示しています。CPU は 80% > 、ネットワーク帯域幅は 3 GB/秒を超えます。
HDFSプロトコルの負荷がかかったときのHDFSプロトコル統計とCPUの利用率のプロット(図5)
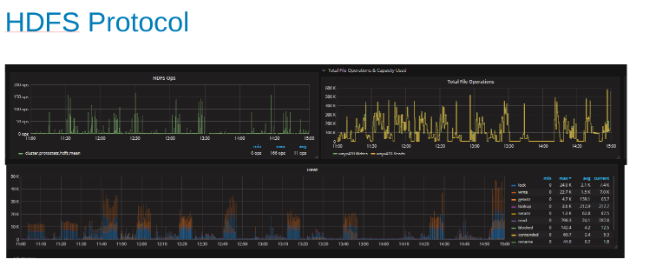
これらのプロットは、HDFSプロトコルの統計情報と、OneFSが出力を変換する方法を示しています。HDFS操作はdfs.blocksizeの倍数であり、ここでは256MBです。ここで興味深いのは、[Heat]グラフにOneFSのファイル操作が表示され、書き込みとロックの相関関係が示されていることです。この場合、HBaseはWALへの追加を行うため、OneFSは追加された書き込みごとにWALファイルをロックします。これは、クラスター化されたファイル システムでの安定した書き込みに期待される動作です。これらは、この一連のテストの制限要因に寄与しているように思われます。
HBase の更新
この次のテストでは、大規模に何が起こるかを調べるために、さらに実験を行いました。生成に1時間かかった10億行のテーブルが作成されます。「workloada」設定(読み取り/書き込み50/50)を使用して1,000万行を更新するYCSBテストを実行します。このテストは、単一のクライアントで実行されました。テストは、最大のスループットを生成できるように、YCSBスレッドの数の関数として実行されました。また、いくつかのチューニングが適用され、OneFSがv8.0.1.1にアップグレードされました。これにより、データ ノード サービスのパフォーマンスが調整されました。次のグラフは、以前の一連の実行と比較したパフォーマンスの向上を示しています。これらの実行では、hbase.regionserver.maxlogs は 256 に設定され、hbase.wal.regiongrouping.numgroups は 20 に設定されます。
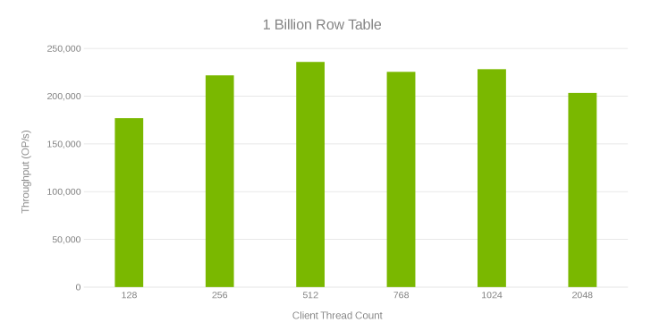
10億行のテーブルを更新する際のスループットとスレッド数(図6)
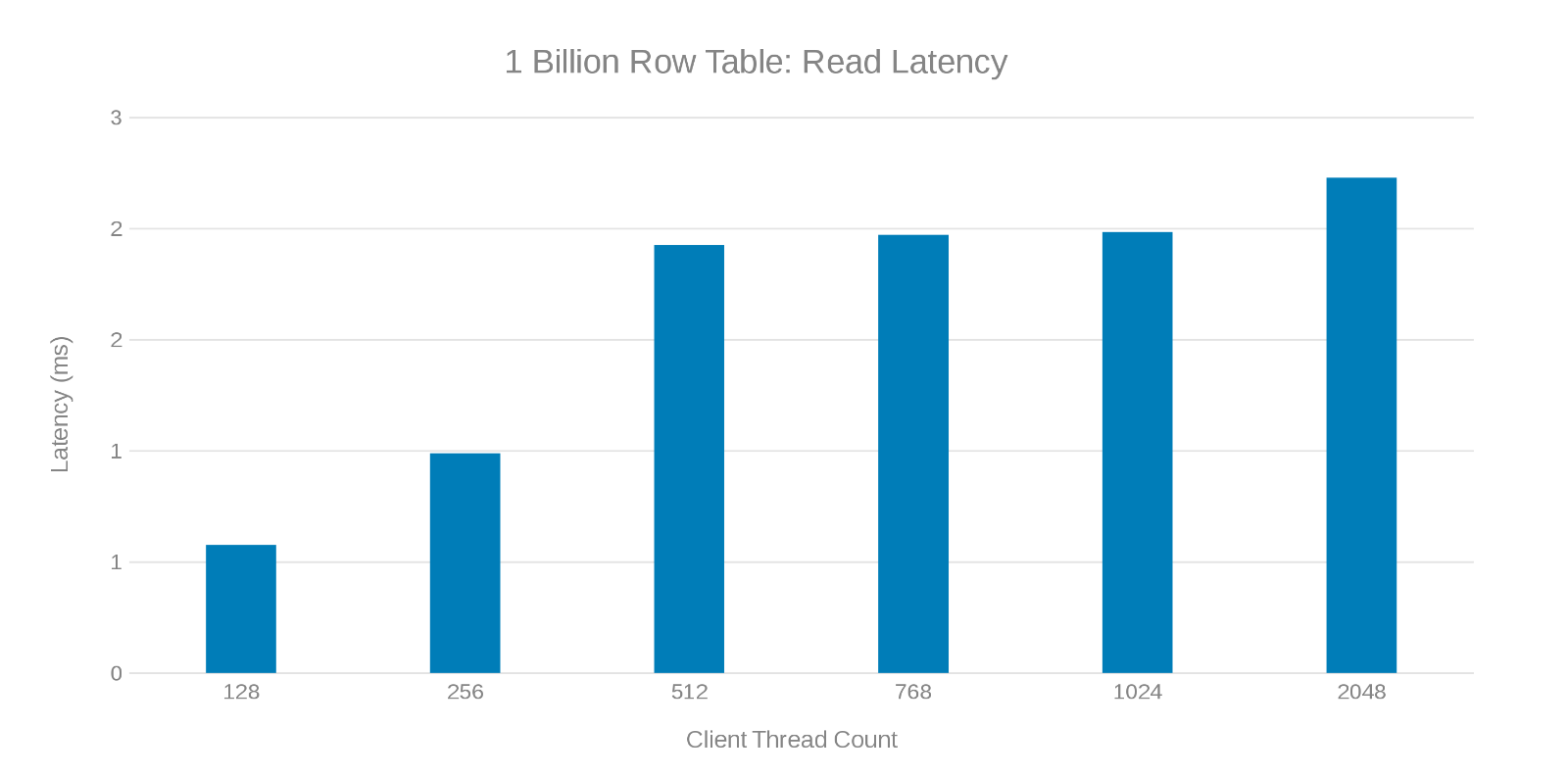
10億行のテーブル更新中の読み取りレイテンシー(図7)
10億行のテーブル更新中の更新レイテンシー(図8)

これらのテスト実行を確認すると、スレッド数が多い場合に明らかに減衰していることが示されています。これは、Isilonまたはクライアント側の問題である可能性があります。テストでは、 < 3ミリ秒のアップデート レイテンシーで毎秒20万回の操作が実施されました。各更新テストの実行は高速で、連続して実行することができました。次のグラフは、各テストの実行におけるIsilonノード間の均等なバランスを示しています。
Isilon Cluster内の各ノードのワークロードを示すヒート グラフ(図9)
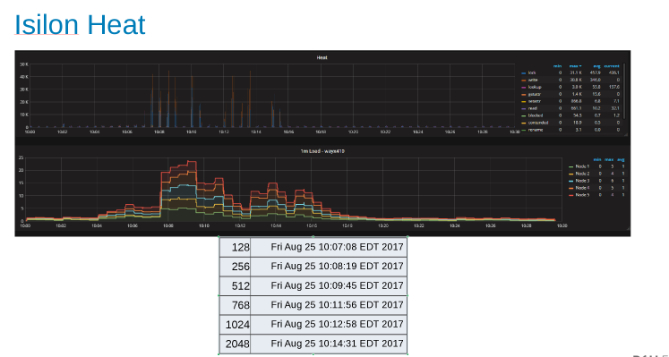
ヒート グラフは、ファイル操作がWALプロセスの追加特性に対応する書き込みとロックであることを示しています。
リージョン サーバーのスケーリング
次のテストでは、異なる数のリージョン サーバーに対してIsilonノード(5ノード)がどのように機能するかを判断しました。前のテストで実行したのと同じ更新スクリプトは、10 億行のテーブルと、'workloada' を使用した 1,000 万行の更新で実行されました。このテストでは、YCSB スレッドを 51 に設定した 1 つのクライアントを使用しました。maxlogsとpipelinesに同じ設定が適用されます(それぞれ256と20)。
リージョンサーバー間のスループット(図10)
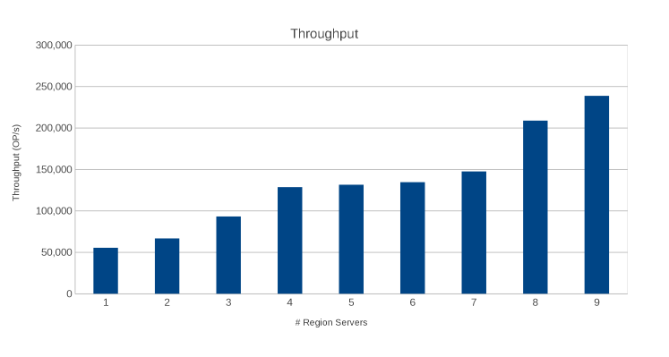
リージョンサーバー間のレイテンシー(図11)
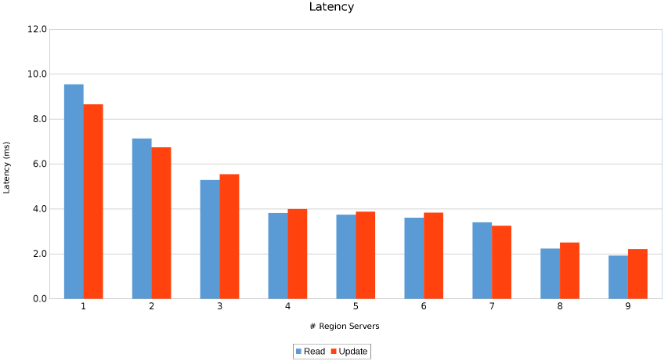
結果は、驚くことではありませんが、有益です。HBaseのスケールアウトの性質とIsilonのスケールアウトの性質を組み合わせると、多ければ多いほど良いということが分かりました。このテストは、クライアントが独自のサイジング演習の一環として、各自の環境で実行することをお勧めします。ここでは、9台のサーバーが5つのIsilonノードをプッシュしていますが、収穫逓減のポイントに達する前に、さらに多くのサーバーを投入する余地がまだあるように思われます。
より多くのクライアント
最後の一連のテストは、ハードウェア構成の限界をテストするのに役立ちました。これは、テスト対象のパラメーターの上限を決定するために行われました。この一連のテストでは、2つの追加サーバーを使用してからクライアントを実行します。さらに、各サーバーから 2 つの YCSB クライアントが実行され、それぞれ最大 6 つのクライアントが許可されます。各クライアントは512スレッドを駆動し、全体で4,096スレッドとなりました。2 つの異なるテーブルが作成されました。40億行のテーブルが600のリージョンに分割され、4億行のテーブルが90のリージョンに分割されます。
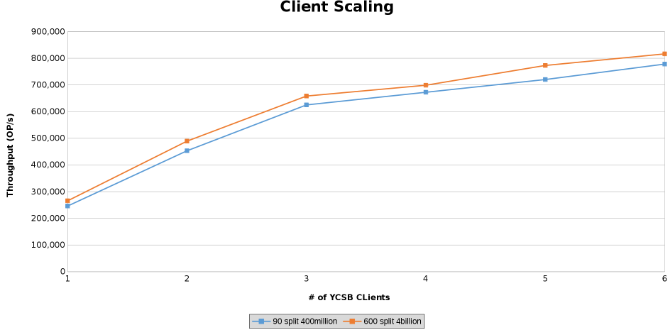
これは、クライアントのスケーリングをテストしている間の操作スループットをグラフ化したものです(図12)。
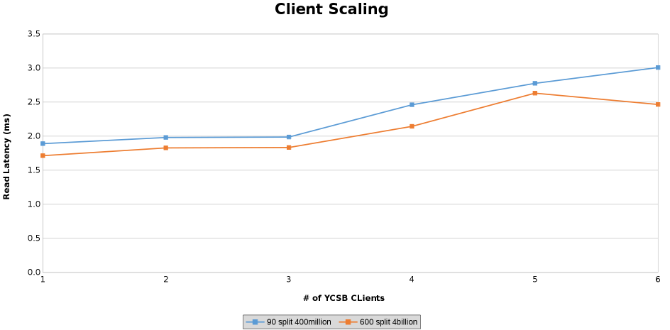
クライアントの拡張テスト中の読み取りレイテンシーの測定(図13)
クライアントの拡張テスト中の更新レイテンシーの測定(図14)
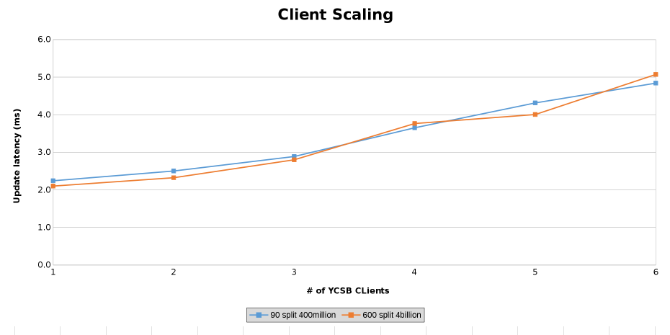
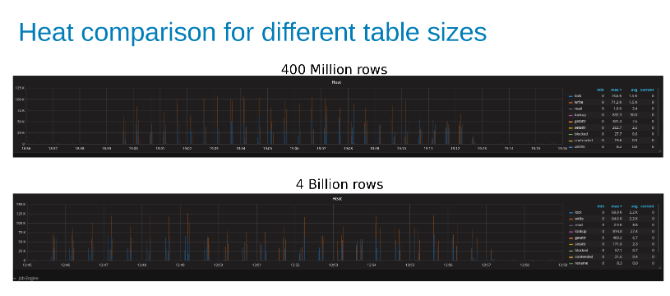
下のグラフは、このテストではテーブルのサイズがほとんど重要ではないことを示しています。Isilonヒート チャートでも、ファイル操作の数に数パーセントの差があることがわかります。ほとんどの違いは、40億行の表と4億行の表の差と一致していました。
4億行のテーブルの更新中のIsilonワークロードの熱を、40億行のテーブルと比較しました (図15)。
結論
HBaseは、主にスケールアウトからスケールアウトへのアーキテクチャのため、Isilon上で実行するのに適した候補です。HBase は多くの独自のキャッシュを行い、テーブルを多数のリージョンに分割することで、データを使用してスケールアウトできます。言い換えれば、独自のニーズを適切に処理し、ファイル システムはアプリケーションの耐障害性のために存在します。テストでは、物が壊れるほど負荷をかけることができませんでした。HBase が 3 ミリ秒未満の待機時間で 800,000 回の操作用に設計されている場合、このアーキテクチャでサポートされます。HBase では、クライアント側と HBase 自体の両方で、無数のパフォーマンスの調整と調整がサポートされています。これらすべての調整と調整のテストは、このテストの範囲を超えていました。Affected Products
Isilon, PowerScale OneFSArticle Properties
Article Number: 000128942
Article Type: Solution
Last Modified: 11 Mar 2026
Version: 7
Find answers to your questions from other Dell users
Support Services
Check if your device is covered by Support Services.