AMD ROME — czy to prawda? Architektura i wstępna wydajność HPC
Summary: W dzisiejszym świecie HPC przedstawiamy najnowszą generację procesorów AMD EPYC o nazwie kodowej Rome.
This article applies to
This article does not apply to
This article is not tied to any specific product.
Not all product versions are identified in this article.
Symptoms
Garima Kochhar, Deepthi Cherlopalle, Joshua Weage. Laboratorium innowacji HPC i AI, październik 2019 r.
Cause
Nie dotyczy
Resolution
W dzisiejszym świecie HPC procesora AMD EPYC  najnowszej generacji o nazwie kodowej Rome nie trzeba nikomu przedstawiać. W ostatnich miesiącach w Laboratorium innowacji HPC i AI ocenialiśmy systemy znajdujące się w Rzymie, a niedawno firma Dell Technologies ogłosiła
najnowszej generacji o nazwie kodowej Rome nie trzeba nikomu przedstawiać. W ostatnich miesiącach w Laboratorium innowacji HPC i AI ocenialiśmy systemy znajdujące się w Rzymie, a niedawno firma Dell Technologies ogłosiła  serwery obsługujące tę architekturę procesorów. W pierwszym wpisie na blogu z serii Rome omówimy architekturę procesora Rome, sposoby jej dostrojenia do wydajności HPC oraz przedstawimy wstępną wydajność mikrotestów porównawczych. Kolejne blogi będą opisywać wydajność aplikacji w domenach CFD, CAE, dynamiki molekularnej, symulacji pogody i innych zastosowań.
serwery obsługujące tę architekturę procesorów. W pierwszym wpisie na blogu z serii Rome omówimy architekturę procesora Rome, sposoby jej dostrojenia do wydajności HPC oraz przedstawimy wstępną wydajność mikrotestów porównawczych. Kolejne blogi będą opisywać wydajność aplikacji w domenach CFD, CAE, dynamiki molekularnej, symulacji pogody i innych zastosowań.
Architektura
Rome to procesor AMD EPYC drugiej generacji, odświeżający procesor Naples pierwszej generacji. O Neapolu pisaliśmy na tym blogu w zeszłym roku.
Jedną z największych różnic architektonicznych między Neapolem a Rzymem, która przynosi korzyści HPC, jest nowa matryca IO w Rzymie. W Rzymie każdy procesor jest pakietem wieloukładowym składającym się z maksymalnie 9 chipletów , jak pokazano na rysunku 1. Istnieje jedna centralna matryca IO 14 nm, która zawiera wszystkie funkcje we/wy i pamięci - pomyśl o kontrolerach pamięci, łączach szkieletowych Infinity w gnieździe i łączności między gniazdami oraz PCI-e. W każdym gnieździe znajduje się osiem kontrolerów pamięci obsługujących osiem kanałów pamięci DDR4 z szybkością 3200 MT/s. Serwer jednogniazdowy może obsługiwać do 130 torów PCIe czwartej generacji. System z dwoma gniazdami może obsługiwać do 160 torów PCIe czwartej generacji.

(Rysunek 1. Rzymski pakiet wieloukładowy z jedną centralną matrycą IO i maksymalnie ośmiordzeniowymi matrycami)
Wokół centralnej matrycy IO znajduje się do ośmiu chipletów rdzeniowych 7 nm. Chiplet rdzenia nazywany jest matrycą pamięci podręcznej rdzenia lub CCD. Każdy CCD ma rdzenie procesora oparte na mikroarchitekturze Zen2, pamięć podręczną L2 i 32 MB pamięci podręcznej L3. Sam przetwornik CCD ma dwa kompleksy pamięci podręcznej rdzenia (CCX), z których każdy ma do czterech rdzeni i 16 MB pamięci podręcznej L3. Rysunek 2 przedstawia CCX.
z których każdy ma do czterech rdzeni i 16 MB pamięci podręcznej L3. Rysunek 2 przedstawia CCX.

(Rysunek 2 . CCX z czterema rdzeniami i współużytkowaną pamięcią podręczną L3 o pojemności 16 MB)
Różne modele  procesorów Rome mają różną liczbę rdzeni,
procesorów Rome mają różną liczbę rdzeni, ale wszystkie mają jedną centralną kość wejścia/wyjścia.
ale wszystkie mają jedną centralną kość wejścia/wyjścia.
Na najwyższym poziomie znajduje się model z 64-rdzeniowym procesorem, na przykład EPYC 7702. Dane wyjściowe lstopo pokazują nam, że procesor ma 16 CCX na gniazdo, każdy CCX ma cztery rdzenie, jak pokazano na rysunku 3 i 4, co daje 64 rdzenie na gniazdo. 16 MB L3 na CCX, czyli 32 MB L3 na CCD, daje temu procesorowi łącznie 256 MB pamięci podręcznej L3. Należy jednak pamiętać, że całkowita pamięć podręczna L3 w Rzymie nie jest współdzielona przez wszystkie rdzenie. Pamięć podręczna L3 o pojemności 16 MB w każdym systemie CCX jest niezależna i współużytkowana tylko przez rdzenie w systemie CCX, jak pokazano na rysunku 2.
24-rdzeniowy procesor, taki jak EPYC 7402, ma 128 MB pamięci podręcznej L3. Dane wyjściowe lstopo na rysunku 3 i 4 pokazują, że model ten ma trzy rdzenie na CCX i 8 CCX na gniazdo.


(Rysunek 3 i 4 Wyjście lstopo dla procesorów 64-rdzeniowych i 24-rdzeniowych)
Bez względu na liczbę przetworników CCD, każdy procesor Rome jest logicznie podzielony na cztery ćwiartki , przy czym przetworniki CCD są rozmieszczone tak równomiernie, jak to tylko możliwe, oraz dwa kanały pamięci w każdej ćwiartce. Centralna matryca we/wy może być traktowana jako logicznie podtrzymująca cztery ćwiartki gniazda.
Opcje systemu BIOS oparte na architekturze Rome
Centralna matryca we/wy w Rzymie pomaga poprawić opóźnienia  pamięci w porównaniu z tymi mierzonymi w Neapolu. Ponadto umożliwia skonfigurowanie procesora jako jednej domeny NUMA, co zapewnia jednolity dostęp do pamięci dla wszystkich rdzeni w gnieździe. Zostało to wyjaśnione poniżej.
pamięci w porównaniu z tymi mierzonymi w Neapolu. Ponadto umożliwia skonfigurowanie procesora jako jednej domeny NUMA, co zapewnia jednolity dostęp do pamięci dla wszystkich rdzeni w gnieździe. Zostało to wyjaśnione poniżej.
Cztery kwadranty logiczne w procesorze Rome umożliwiają partycjonowanie procesora na różne domeny NUMA. To ustawienie nosi nazwę NUMA na gniazdo lub NPS.
- NPS1 oznacza, że procesor Rome jest pojedynczą domeną NUMA ze wszystkimi rdzeniami w gnieździe i całą pamięcią w jednej domenie NUMA. Pamięć jest przeplatana przez osiem kanałów pamięci. Wszystkie urządzenia PCIe w gnieździe należą do jednej domeny NUMA
- Serwer NPS2 dzieli procesor na dwie domeny NUMA, z połową rdzeni i połową kanałów pamięci w gnieździe w każdej domenie NUMA. Pamięć jest przeplatana czterema kanałami pamięci w każdej domenie NUMA
- Serwer NPS4 dzieli procesor na cztery domeny NUMA. Każdy kwadrant jest tutaj domeną NUMA, a pamięć jest przeplatana w dwóch kanałach pamięci w każdym kwadrancie. Urządzenia PCIe będą lokalne w jednej z czterech domen NUMA w gnieździe, w zależności od tego, który kwadrant kości we/wy zawiera katalog główny PCIe dla tego urządzenia
- Nie wszystkie procesory mogą obsługiwać wszystkie ustawienia serwera NPS
Serwer NPS4 jest zalecany do HPC, ponieważ oczekuje się, że zapewni najlepszą przepustowość pamięci i najniższe opóźnienia pamięci, a nasze aplikacje zwykle obsługują technologię NUMA. Jeśli NPS4 nie jest dostępny, zalecamy najwyższy NPS obsługiwany przez model CPU — NPS2, a nawet NPS1.
Biorąc pod uwagę mnogość opcji NUMA dostępnych na platformach opartych na Rome, system BIOS serwera PowerEdge umożliwia korzystanie z dwóch różnych metod wyliczania rdzeni w ramach wyliczania MADT. Wyliczenie liniowe numeruje rdzenie w kolejności, wypełniając jedno gniazdo CCX, CCD przed przejściem do następnego gniazda. W przypadku procesora 32c rdzenie od 0 do 31 będą znajdować się w pierwszym gnieździe, a rdzenie 32-63 w drugim gnieździe. Wyliczenie działania okrężnego numeruje rdzenie w regionach NUMA. W takim przypadku rdzenie parzyste będą znajdować się w pierwszym gnieździe, a rdzenie nieparzyste w drugim gnieździe. Dla uproszczenia zalecamy wyliczenie liniowe dla HPC. Na rys. 5 przedstawiono przykład liniowego wyliczenia rdzenia na dwuprocesorowym serwerze 64c skonfigurowanym w NPS4. Na rysunku każde pudełko z czterema rdzeniami to CCX, każdy zestaw ciągłych ośmiu rdzeni to CCD.

(Rysunek 5 . Liniowe wyliczenie rdzeni w systemie z dwoma gniazdami, 64 rdzenie na gniazdo, konfiguracja NPS4 w modelu z 8 procesorami CCD)
Inną opcją systemu BIOS specyficzną dla Rome jest preferowane urządzenie we/wy. Jest to ważne pokrętło dostrajania przepustowości i szybkości komunikatów InfiniBand. Umożliwia platformie priorytetyzację ruchu dla jednego urządzenia IO. Ta opcja jest dostępna zarówno na jednoprocesorowych, jak i dwuprocesorowych platformach Rome, a urządzenie InfiniBand na platformie musi być wybrane jako preferowane urządzenie w menu BIOS, aby osiągnąć pełną szybkość komunikatów, gdy wszystkie rdzenie procesora są aktywne.
Podobnie jak Neapol, Rzym również obsługuje hiperwątkowośćlub procesor logiczny. W przypadku HPC pozostawiamy tę opcję wyłączoną, ale niektóre aplikacje mogą skorzystać z włączenia procesora logicznego. Zajrzyj do naszych kolejnych blogów na temat badań aplikacyjnych dynamiki molekularnej.
Podobnie jak w przypadku Neapolu, Rzym również zezwala na CCX jako domenę NUMA. Ta opcja uwidacznia każdy CCX jako węzeł NUMA. W systemie z procesorami dwugniazdowymi z 16 modułami CCX na procesor to ustawienie spowoduje uwidocznienie 32 domen NUMA. W tym przykładzie każde gniazdo ma 8 przetworników CCD, czyli 16 CCX. Każdy CCX można włączyć jako własną domenę NUMA, co daje 16 węzłów NUMA na gniazdo i 32 w systemie dwugniazdowym. W przypadku HPC zalecamy pozostawienie CCX jako domeny NUMA w domyślnej opcji wyłączonej. Włączenie tej opcji powinno pomóc w środowiskach zwirtualizowanych.
Podobnie jak w Neapolu, Rzym pozwala na ustawienie systemu w trybie determinizmu wydajności lub determinizmu władzy . W przypadku determinizmu wydajności system działa z częstotliwością oczekiwaną dla modelu CPU, zmniejszając zmienność między wieloma serwerami. W przypadku determinizmu mocy system działa z maksymalnym dostępnym TDP modelu procesora. Zwiększa to zmienność poszczególnych części w procesie produkcyjnym, dzięki czemu niektóre serwery są szybsze od innych. Wszystkie serwery mogą zużywać maksymalną moc znamionową procesora, co sprawia, że zużycie energii jest deterministyczne, ale pozwala na pewne różnice wydajności w przypadku wielu serwerów.
Jak przystało na platformy PowerEdge, system BIOS ma metaopcję o nazwie Profil systemu. Wybranie profilu systemu zoptymalizowanego pod kątem wydajności spowoduje włączenie trybu doładowania turbo, wyłączenie stanów C i ustawienie suwaka determinizmu na determinizm mocy, optymalizując go pod kątem wydajności.
Wyniki wydajności — mikrobenchmarki STREAM, HPL, InfiniBand
Wielu z naszych czytelników mogło od razu przejść do tej sekcji, więc przejdziemy od razu.
W Laboratorium Innowacji HPC i AI stworzyliśmy 64-serwerowy klaster o nazwie Minerva. Oprócz jednorodnego klastra Minerva, mamy kilka innych próbek procesorów Rome, które udało nam się ocenić. Nasze stanowisko testowe jest opisane w Tabeli 1 i Tabeli 2.
(Tabela 1 Modele procesorów Rome ocenione w tym badaniu)
| Procesor | Liczba rdzeni na gniazdo | Konfiguracja | Zegar bazowy | TDP |
|---|---|---|---|---|
| 7702 | 64c | 4 centy na CCX | 2,0 GHz | 200W |
| 7502 | 32c | 4 centy na CCX | 2,5 GHz | 180 W |
| 7452 | 32c | 4 centy na CCX | 2,35 GHz | 155 W |
| 7402 | 24c | 3 centy na CCX | 2,8 GHz | 180 W |
(Tabela 2 Stanowisko testowe)
| Komponent | Szczegóły |
|---|---|
| Serwer | PowerEdge C6525 |
| Procesor | Jak pokazano w tabeli 1 z dwoma gniazdami |
| Pamięć | 256 GB, 16 x 16 GB pamięci DDR4 3200 MT/s |
| Połączenia | ConnectX-6 Mellanox Infini Band HDR100 |
| System operacyjny | Red Hat Enterprise Linux 7.6 |
| Jądro | 3.10.0.957.27.2.e17.x86_64 |
| Dysku | Moduł M.2 SATA SSD 240 GB |
STRUMIENIA
Testy przepustowości pamięci w Rome przedstawiono na rysunku 6, testy te zostały przeprowadzone w trybie NPS4. Zmierzyliśmy przepustowość pamięci ~270–300 GB/s na naszym dwugniazdowym serwerze PowerEdge C6525 przy użyciu wszystkich rdzeni serwera w czterech modelach procesorów wymienionych w tabeli 1. Gdy używany jest tylko jeden rdzeń na CCX, przepustowość pamięci systemowej jest ~9-17% wyższa niż zmierzona dla wszystkich rdzeni.
Większość obciążeń roboczych HPC albo w pełni subskrybuje wszystkie rdzenie systemu, albo centra HPC działają w trybie wysokiej przepływności z wieloma zadaniami na każdym serwerze. W związku z tym przepustowość pamięci dla wszystkich rdzeni jest dokładniejszym odzwierciedleniem przepustowości pamięci i przepustowości pamięci na rdzeń systemu.
Rysunek 6 przedstawia również przepustowość pamięci zmierzoną na platformie EPYC Naples poprzedniej generacji, która również obsługiwała osiem kanałów pamięci na gniazdo, ale działała z prędkością 2667 MT/s. Platforma Rome zapewnia od 5% do 19% lepszą całkowitą przepustowość pamięci niż Neapol, a wynika to głównie z szybszej pamięci 3200 MT/s. Nawet przy 64 rdzeniach na gniazdo, system Rome może dostarczyć ponad 2 GB/s/rdzeń.
UWAGA: Odchylenie wydajności o 5-10% w wynikach STREAM Triad zostało zmierzone na wielu identycznie skonfigurowanych serwerach opartych na Rzymie, dlatego należy założyć, że poniższe wyniki są górną granicą zakresu.
Porównując różne konfiguracje NPS, przy NPS4 zmierzono ~13% większą przepustowość pamięci w porównaniu z NPS1, jak pokazano na rysunku 7.

(Rysunek 6 . Przepustowość pamięci triady dwugniazdowego NPS4 STREAM)

(Rysunek 7 . Przepustowość pamięci NPS1 i NPS2 vs NPS 4)
Przepustowość sieci InfiniBand i szybkość wysyłania wiadomości
Rysunek 8 przedstawia jednordzeniową przepustowość pasma InfiniBand dla testów jednokierunkowych i dwukierunkowych. W środowisku testowym użyto formatu HDR100 działającego z szybkością 100 Gb/s, a wykres pokazuje oczekiwaną wydajność łącza dla tych testów.
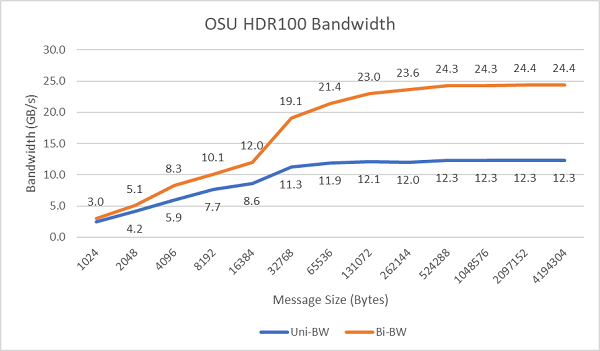
Rysunek 8 . Przepustowość InfiniBand (pojedynczy rdzeń)

Rysunek 9 . Szybkość komunikatów InfiniBand (wszystkie rdzenie)
Następnie przeprowadzono testy szybkości przesyłania wiadomości przy użyciu wszystkich rdzeni gniazda na dwóch testowanych serwerach. Gdy preferowane we/wy jest włączone w systemie BIOS, a karta ConnectX-6 HDR100 jest skonfigurowana jako preferowane urządzenie, szybkość przesyłania wiadomości przez wszystkie rdzenie jest znacznie wyższa niż w przypadku, gdy preferowane we/wy nie jest włączone, jak pokazano na rysunku 9. Ilustruje to znaczenie tej opcji systemu BIOS podczas dostrajania pod kątem HPC, a zwłaszcza skalowalności aplikacji wielowęzłowych.
HPL
Mikroarchitektura Rome może wycofać 16 DP FLOP/cykl, dwa razy więcej niż w Neapolu, który wynosił 8 FLOPS na cykl. Daje to Rzymowi 4 razy więcej teoretycznych szczytowych FLOPS nad Neapolem, 2 razy więcej niż zwiększona zdolność zmiennoprzecinkowa i 2 razy więcej rdzeni (64 rdzenie w porównaniu z 32 rdzeniami). Rysunek 10 przedstawia zmierzone wyniki HPL dla czterech testowanych przez nas modeli procesorów Rome wraz z naszymi poprzednimi wynikami z systemu opartego na Neapolu. Wydajność Rome HPL jest odnotowywana jako wartość procentowa nad słupkami na wykresie i jest wyższa dla modeli procesorów o niższym TDP.
Testy przeprowadzono w trybie determinizmu mocy, a ~5% delta wydajności została zmierzona na 64 identycznie skonfigurowanych serwerach, a zatem wyniki tutaj są w tym paśmie wydajności.

(Rysunek 10 . HPL pojedynczego serwera w NPS4)
Następnie wykonano wielowęzłowe testy HPL, których wyniki przedstawiono na rysunku 11. Sprawność HPL dla EPYC 7452 utrzymuje się na poziomie powyżej 90% w skali 64-węzłowej, ale spadki wydajności ze 102% do 97% i wstecz do 99% wymagają dalszej oceny

(Rysunek 11 . Wielowęzłowa platforma HPL, dwugniazdowy procesor EPYC 7452 przez HDR100 InfiniBand)
Podsumowanie i kolejne plany
Wstępne badania wydajności serwerów zlokalizowanych w Rzymie wykazały oczekiwaną wydajność naszego pierwszego zestawu testów porównawczych HPC. Dostrajanie systemu BIOS jest ważne podczas konfigurowania w celu uzyskania najlepszej wydajności, a opcje dostrajania są dostępne w naszym profilu obciążenia roboczego HPC systemu BIOS, który można skonfigurować fabrycznie lub ustawić za pomocą narzędzi do zarządzania systemami Dell EMC.
Laboratorium innowacji HPC i AI dysponuje nowym klastrem PowerEdge Minerva z 64 serwerami w Rzymie. Obserwuj to miejsce, aby zapoznać się z kolejnymi blogami opisującymi badania wydajności aplikacji w naszym nowym klastrze Minerva.
Article Properties
Article Number: 000137696
Article Type: Solution
Last Modified: 31 Jan 2025
Version: 7
Find answers to your questions from other Dell users
Support Services
Check if your device is covered by Support Services.