Caratterizzazione del BIOS per HPC con processori Intel Cascade Lake (in inglese)
Dieser Artikel gilt für
Dieser Artikel gilt nicht für
Dieser Artikel ist nicht an ein bestimmtes Produkt gebunden.
In diesem Artikel werden nicht alle Produktversionen aufgeführt.
Symptome
Articolo scritto da Varun Bawa, Savitha Pareek e Ashish K Singh di HPC and AI Innovation Lab nell'aprile 2019
Lösung
Con il rilascio dei processori della famiglia di processori scalabili Intel Xeon® di seconda generazione (architettura denominata in codice "Cascade Lake"), Dell EMC ha aggiornato i server PowerEdge di 14a generazione per beneficiare dell'aumento del numero di core e delle velocità di memoria più elevate, a vantaggio delle applicazioni HPC.
Questo blog presenta la prima serie di risultati e discute l'impatto delle diverse opzioni di ottimizzazione del BIOS disponibili su Dell EMC PowerEdge C6420 con i processori Intel Xeon® Cascade Lake più recenti per alcuni benchmark e applicazioni HPC. Di seguito viene fornita una breve descrizione del processore Cascade Lake, delle opzioni del BIOS e delle applicazioni HPC utilizzate in questo studio.
Cascade Lake è il successore di Skylake di Intel. Il processore Cascade Lake supporta fino a 28 core, sei canali di memoria DDR4 con velocità fino a 2933 MT/s. Analogamente a Skylake, Cascade Lake supporta una potenza di vettorizzazione aggiuntiva con il set di istruzioni AVX512 che consente 32 DP FLOP/ciclo. Cascade Lake introduce Vector Neural Network Instructions (VNNI), che accelera le prestazioni dei carichi di lavoro AI e DL come la classificazione delle immagini, il riconoscimento vocale, la traduzione linguistica, il rilevamento di oggetti e altro ancora. VNNI supporta anche l'istruzione a 8 bit per accelerare le prestazioni di inferenza.
Cascade Lake include mitigazioni hardware per alcune vulnerabilità del canale laterale. Si prevede che ciò possa migliorare le prestazioni sui carichi di lavoro di storage. Cerca studi futuri dell'Innovation Lab.
Poiché Skylake e Cascade Lake sono compatibili con i socket, le manopole di ottimizzazione del processore esposte nel BIOS di sistema sono simili in queste generazioni di processori. In questo studio sono state esplorate le seguenti opzioni di ottimizzazione del BIOS, analogamente al lavoro pubblicato in passato su Skylake.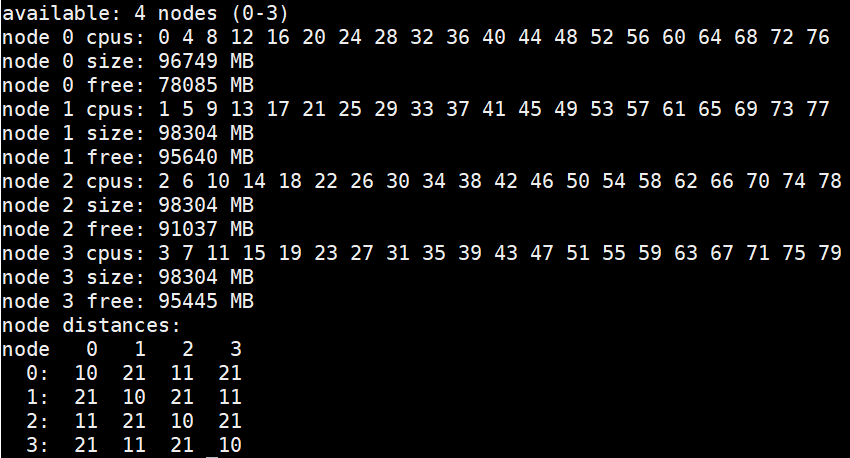
 OS - PerformancePerWattOS
OS - PerformancePerWattOS  DAPC - PerformancePerWattDAPC
DAPC - PerformancePerWattDAPC
Sub-NUMA Clustering: SNC = 0(SNC = disabilitato): SNC = 1(SNC = abilitato: Formattato come striped in graphs)
SW – Software Prefetcher: SW = 0 (SW = disabilitato): SW = 1 (SW = abilitato)

La Figura 2 confronta il risultato di HPL con Dimensione del problema = 90%, ovvero N = 144476 tra diverse opzioni del BIOS. Il grafico traccia i Gigaflops assoluti ottenuti durante l'esecuzione di HPL su diverse configurazioni del BIOS. Questi Gigaflops ottenuti sono tracciati sull'asse y, più alto è meglio.
Di seguito sono riportate le osservazioni tratte dal grafico:
La Figura 3 confronta il risultato di STREAM tra le diverse configurazioni del BIOS.
Il grafico mostra la larghezza di banda della memoria in gigabyte al secondo ottenuta durante l'esecuzione di STREAM Triad. La larghezza di banda della memoria (GB/sec) ottenuta viene tracciata sull'asse y: maggiore è il valore, migliore è. La configurazione del BIOS associata a valori specifici di Gigabyte al secondo viene tracciata sull'asse x.
Di seguito sono riportate le osservazioni tratte dal grafico:
La Figura 4 traccia il punteggio della larghezza di banda della memoria Stream Triad in tale configurazione. La larghezza di banda completa della memoria di sistema è ~220 GB/s. Quando 20 core su un socket locale accedono alla memoria locale, la larghezza di banda della memoria è ~ 109 GB/s, la metà della larghezza di banda completa del sistema. La metà di questo, ~56 GB/s, è la larghezza di banda della memoria di 10 thread sullo stesso nodo NUMA che accede alla memoria locale e su un nodo NUMA accede alla memoria appartenente all'altro nodo NUMA sullo stesso socket. Si verifica un calo del 42% nella larghezza di banda della memoria a ~33 GB/s quando i thread accedono alla memoria remota attraverso il collegamento QPI sul socket remoto. Questo ci indica che c'è una significativa penalità della larghezza di banda in modalità SNC quando i dati non sono locali.

La Figura 5 confronta il risultato di WRF tra diverse opzioni del BIOS, il dataset utilizzato è conus2.5km con il file "namelist.input" predefinito.
Il grafico traccia il timestep medio assoluto in secondi ottenuto durante l'esecuzione del dataset WRF-conus2.5km su diverse configurazioni del BIOS. Il timestep medio ottenuto è tracciato sull'asse y, più basso è meglio. I profili relativi associati a valori specifici del timestep medio vengono tracciati sull'asse x.
Di seguito sono riportate le osservazioni tratte dal grafico:

Dalla figura 6 alla figura 9 vengono tracciati i grafici della valutazione del risolutore ottenuta durante l'esecuzione di Fluent, rispettivamente con dataset Ice_2m, Combustor_12m, Aircraft_Wing_14m e Exhaust_System_33m. Il Solver Rating ottenuto viene tracciato sull'asse y, Più alto è il migliore. I profili relativi associati a valori specifici di Tempo medio vengono tracciati sull'asse x.
Di seguito sono riportate le osservazioni complessive tratte dai grafici di cui sopra:
In questo studio non viene discussa una funzionalità RAS della memoria denominata Adaptive Double DRAM Device Correction (ADDDC), disponibile quando un sistema è configurato con una memoria dotata di organizzazione x4 DRAM (32 GB, 64 GB DIMM). ADDDC non è disponibile quando un sistema dispone di DIMM basati su x8 (8 GB, 16 GB) ed è irrilevante in tali configurazioni. Per i carichi di lavoro HPC, si consiglia di impostare ADDDC su Disabled quando disponibile come opzione regolabile.
Questo blog presenta la prima serie di risultati e discute l'impatto delle diverse opzioni di ottimizzazione del BIOS disponibili su Dell EMC PowerEdge C6420 con i processori Intel Xeon® Cascade Lake più recenti per alcuni benchmark e applicazioni HPC. Di seguito viene fornita una breve descrizione del processore Cascade Lake, delle opzioni del BIOS e delle applicazioni HPC utilizzate in questo studio.
Cascade Lake è il successore di Skylake di Intel. Il processore Cascade Lake supporta fino a 28 core, sei canali di memoria DDR4 con velocità fino a 2933 MT/s. Analogamente a Skylake, Cascade Lake supporta una potenza di vettorizzazione aggiuntiva con il set di istruzioni AVX512 che consente 32 DP FLOP/ciclo. Cascade Lake introduce Vector Neural Network Instructions (VNNI), che accelera le prestazioni dei carichi di lavoro AI e DL come la classificazione delle immagini, il riconoscimento vocale, la traduzione linguistica, il rilevamento di oggetti e altro ancora. VNNI supporta anche l'istruzione a 8 bit per accelerare le prestazioni di inferenza.
Cascade Lake include mitigazioni hardware per alcune vulnerabilità del canale laterale. Si prevede che ciò possa migliorare le prestazioni sui carichi di lavoro di storage. Cerca studi futuri dell'Innovation Lab.
Poiché Skylake e Cascade Lake sono compatibili con i socket, le manopole di ottimizzazione del processore esposte nel BIOS di sistema sono simili in queste generazioni di processori. In questo studio sono state esplorate le seguenti opzioni di ottimizzazione del BIOS, analogamente al lavoro pubblicato in passato su Skylake.
Impostazioni del processore:
- Pre-fetch riga cache adiacente: Il meccanismo Adiacente Cache-Line Prefetch consente il pre-fetch automatico dell'hardware, funziona senza l'intervento del programmatore. Se questa opzione è abilitata, ospita due linee della cache da 64 byte in un settore da 128 byte, indipendentemente dal fatto che la riga della cache aggiuntiva sia stata richiesta o meno.
- Software Prefetcher: Evita lo stallo caricando i dati nella cache prima che sia necessario. Esempio: Per eseguire il pre-fetch dei dati dalla memoria principale alla cache L2 molto prima dell'utilizzo con un'istruzione di prefetch L2, quindi eseguire il pre-fetch dei dati dalla cache L2 alla cache L1 appena prima dell'utilizzo con un'istruzione di prefetch L1. Qui, quando l'impostazione è abilitata, il processore eseguirà il pre-fetch di una linea di cache aggiuntiva per ogni richiesta di memoria.
- SNC (ammasso sub-Numa): L'abilitazione di SNC è simile alla suddivisione del singolo socket in due domini NUMA, ciascuno con metà dei core fisici e metà della memoria del socket. Se vi suona familiare, è simile nell'utilità all'opzione Cluster-on-Die disponibile nei processori Intel Xeon E5-2600 v3 e v4. SNC è implementato in modo diverso da COD e queste modifiche migliorano l'accesso remoto al socket in Cascade Lake rispetto alle generazioni precedenti, che utilizzavano l'opzione Cluster-on-Die. A livello di sistema operativo, un server dual socket con SNC abilitato visualizzerà quattro domini NUMA. Due dei domini saranno più vicini l'uno all'altro (sullo stesso socket) e gli altri due saranno a una distanza maggiore, attraverso l'UPI fino al socket remoto. Questa situazione può essere visualizzata utilizzando strumenti del sistema operativo come: numactl –H ed è illustrato nella Figura 1.
Figura 1. Layout dei nodi NUMA
Profili di sistema:
I profili di sistema sono meta opzioni che, a loro volta, impostano più opzioni del BIOS incentrate sulle prestazioni e sulla gestione dell'alimentazione, come la modalità Turbo, Cstate, C1E, la gestione Pstate, la frequenza Uncore e così via. I diversi profili di sistema confrontati in questo studio includono:- Prestazioni
- PrestazioniPerWattDAPC
- PrestazioniPerWattOS
| Applicazioni | Domain | Versione | Benchmark |
|---|---|---|---|
| Linpack ad alte prestazioni (HPL) | Computazione: risoluzione di un sistema denso di equazioni lineari | Da Intel MKL - 2019 Update 1 | Dimensione del problema 90%, 92% e 94% della memoria totale |
| Flusso | Larghezza di banda della memoria | 5.4 | Triade |
| WRF | Ricerca e previsioni meteorologiche | 3.9.1 | Conus 2,5km |
| ANSYS® Fluent® | Fluidodinamica | 19.2 | Ice_2m, Combustor_12m, Aircraft_wing_14m, Exhaust_System_33m |
Tabella 1. Applicazioni e benchmark
| Componenti | Dettagli |
|---|---|
| Server | PowerEdge server C6420 |
| Processore | CPU Intel® Xeon® Gold 6230 @ 2,1 GHz, 20 core |
| Memoria | 192 GB - 12 da 16 GB 2933 MT/s DDR4 |
| Sistema operativo | Red Hat Enterprise Linux 7.6 |
| Kernel | 3.10.0-957.el7.x86_64 |
| Compilatore | Intel Parallel Studio Cluster Edition_2019_Update_1 |
Tabella 2 Configurazione server
Tutti i risultati qui mostrati si basano su test a server singolo; Le prestazioni a livello di cluster saranno vincolate dalle prestazioni del singolo server. Per confrontare le prestazioni sono state utilizzate le seguenti metriche:- Stream: punteggio della triade come riportato dal benchmark stream.
- HPL – GFLOP/secondo.
- Fluent - Valutazione del risolutore come riportato da Fluent.
- WRF - Passo temporale medio calcolato negli ultimi 719 intervalli per Conus 2,5 km
Benchmark e risultati delle applicazioni
Abbreviazioni delle notazioni grafiche:
Profili di sistema:
Perf - Performance OS - PerformancePerWattOS DAPC - PerformancePerWattDAPCSub-NUMA Clustering: SNC = 0(SNC = disabilitato): SNC = 1(SNC = abilitato: Formattato come striped in graphs)
SW – Software Prefetcher: SW = 0 (SW = disabilitato): SW = 1 (SW = abilitato)
Figura 2. Linpack ad alte prestazioni
La Figura 2 confronta il risultato di HPL con Dimensione del problema = 90%, ovvero N = 144476 tra diverse opzioni del BIOS. Il grafico traccia i Gigaflops assoluti ottenuti durante l'esecuzione di HPL su diverse configurazioni del BIOS. Questi Gigaflops ottenuti sono tracciati sull'asse y, più alto è meglio.
Di seguito sono riportate le osservazioni tratte dal grafico:
- Meno dell'1% di differenza nelle prestazioni HPL a causa del pre-fetch del software.
- Nessun effetto importante di SNC sulle prestazioni HPL (0,5% migliore con SNC=Disabled).
- Performance System Profile è fino al 6% migliore rispetto al sistema operativo e al DAPC.
Figura 3. Flusso
La Figura 3 confronta il risultato di STREAM tra le diverse configurazioni del BIOS.
Il grafico mostra la larghezza di banda della memoria in gigabyte al secondo ottenuta durante l'esecuzione di STREAM Triad. La larghezza di banda della memoria (GB/sec) ottenuta viene tracciata sull'asse y: maggiore è il valore, migliore è. La configurazione del BIOS associata a valori specifici di Gigabyte al secondo viene tracciata sull'asse x.
Di seguito sono riportate le osservazioni tratte dal grafico:
- Fino al 3% di larghezza di banda della memoria in più con SNC=enabled.
- Nessuna deviazione significativa nelle prestazioni a causa del pre-fetch del software sulla larghezza di banda della memoria STREAM.
- Nessuna deviazione tra i profili di sistema.
Figura 4. Larghezza di banda della memoria - SNC
La Figura 4 traccia il punteggio della larghezza di banda della memoria Stream Triad in tale configurazione. La larghezza di banda completa della memoria di sistema è ~220 GB/s. Quando 20 core su un socket locale accedono alla memoria locale, la larghezza di banda della memoria è ~ 109 GB/s, la metà della larghezza di banda completa del sistema. La metà di questo, ~56 GB/s, è la larghezza di banda della memoria di 10 thread sullo stesso nodo NUMA che accede alla memoria locale e su un nodo NUMA accede alla memoria appartenente all'altro nodo NUMA sullo stesso socket. Si verifica un calo del 42% nella larghezza di banda della memoria a ~33 GB/s quando i thread accedono alla memoria remota attraverso il collegamento QPI sul socket remoto. Questo ci indica che c'è una significativa penalità della larghezza di banda in modalità SNC quando i dati non sono locali.
Figura 5. WRF
La Figura 5 confronta il risultato di WRF tra diverse opzioni del BIOS, il dataset utilizzato è conus2.5km con il file "namelist.input" predefinito.
Il grafico traccia il timestep medio assoluto in secondi ottenuto durante l'esecuzione del dataset WRF-conus2.5km su diverse configurazioni del BIOS. Il timestep medio ottenuto è tracciato sull'asse y, più basso è meglio. I profili relativi associati a valori specifici del timestep medio vengono tracciati sull'asse x.
Di seguito sono riportate le osservazioni tratte dal grafico:
- 2% di prestazioni migliori con SNC=Enabled.
- Nessuna differenza di prestazioni per la prelettura software abilitata o disabilitata.
- Il profilo delle prestazioni è migliore dell 1% rispetto ai profili PerformancePerWattDAPC
Dalla figura 6 alla figura 9 vengono tracciati i grafici della valutazione del risolutore ottenuta durante l'esecuzione di Fluent, rispettivamente con dataset Ice_2m, Combustor_12m, Aircraft_Wing_14m e Exhaust_System_33m. Il Solver Rating ottenuto viene tracciato sull'asse y, Più alto è il migliore. I profili relativi associati a valori specifici di Tempo medio vengono tracciati sull'asse x.
Di seguito sono riportate le osservazioni complessive tratte dai grafici di cui sopra:
- Prestazioni migliorate fino al 4% con SNC=Enabled.
- La prelettura software non ha alcun effetto sulle prestazioni.
- Prestazioni fino al 2% migliori con il profilo Performance rispetto ai profili DAPC e OS.
Conclusione
In questo studio abbiamo valutato l'impatto di diverse opzioni di ottimizzazione del BIOS sulle prestazioni quando si utilizza il processore Intel Xeon Gold 6230. Osservando le prestazioni delle diverse opzioni del BIOS in diversi benchmark e applicazioni, si giunge alla conclusione seguente:- Software Prefetch non ha un impatto significativo sulle prestazioni dei dataset testati. Pertanto, si consiglia a Software Prefetcher di rimanere come predefinito, ovvero abilitato
- Con SNC=Enabled aumento delle prestazioni del 2-4% in Fluent e Stream, circa l'1% in WRF rispetto a SNC = Disabled. Pertanto, si consiglia di abilitare SNC per ottenere prestazioni migliori.
- Il profilo delle prestazioni è migliore del 2-4% rispetto a PerformancePerWattDAPC e PerformancePerWattOS. Pertanto, consigliamo il profilo delle prestazioni per HPC .
In questo studio non viene discussa una funzionalità RAS della memoria denominata Adaptive Double DRAM Device Correction (ADDDC), disponibile quando un sistema è configurato con una memoria dotata di organizzazione x4 DRAM (32 GB, 64 GB DIMM). ADDDC non è disponibile quando un sistema dispone di DIMM basati su x8 (8 GB, 16 GB) ed è irrilevante in tali configurazioni. Per i carichi di lavoro HPC, si consiglia di impostare ADDDC su Disabled quando disponibile come opzione regolabile.
Betroffene Produkte
High Performance Computing Solution Resources, Poweredge C4140, Red Hat Enterprise Linux Version 7Artikeleigenschaften
Artikelnummer: 000176921
Artikeltyp: Solution
Zuletzt geändert: 03 März 2025
Version: 5
Antworten auf Ihre Fragen erhalten Sie von anderen Dell NutzerInnen
Support Services
Prüfen Sie, ob Ihr Gerät durch Support Services abgedeckt ist.