

膨大に存在する生成AIのユースケース
2022年11月にChatGPTが公開されたことで、ビジネス界でも大きな注目を集めるようになった生成AI。ChatGPT以外にも様々な生成AIが登場しており、その進化は現在も急速に進んでいる。生成AIを業務に活用しようという動きも始まっており、今後は生成AI抜きにビジネスを語ることはできなくなるといっても、決して過言ではないだろう。一般企業による生成AIへの投資も、これからさらに本格化していくはずだ。
それではなぜ生成AIが、これだけ注目されるようになったのか。それは特定の専門領域だけではなく、極めて広範なビジネス領域で活用できる可能性を秘めているからだ。しかしこうした特徴は、投資の失敗を誘発する危険性も高い。やみくもに導入していくことで投資が増大してしまい、その割には効果が薄いユースケースが散見されることで、急速に「幻滅期」に突入する可能性があるからだ。
実際に、生成AIで実現できると考えられているユースケースは、実に多様だ。その一例を示したのが下の表である。

これらにやみくもに取り組んでしまうと、投資ばかりかさんでしまい、期待したほどの効果が得られない危険性が高い
事業戦略や運営管理、製品企画や研究開発、製造やサプライチェーン、マーケティング・販売・顧客サービス、さらにはITや人事、財務に至るまで、実に多様なユースケースが挙げられている。これらすべてに生成AIを導入することは、現実的とはいえない。まずは、自社で取り組むべきユースケースを絞り込み、そこに投資を集中すべきだろう。
それでは生成AIのユースケースの絞り込みを、どのように行うべきなのか。ここで最初に提言したいのが、まずユースケースを大まかにカテゴライズし、それらの中で具体的なユースケースをリストアップした上で、2つの軸で優先順位を決めていくというアプローチだ。
ユースケースの優先順位付けを行うための方法論
まず生成AIの一般的なユースケースは、大きく6種類考えられる。「ドキュメントオートメーション」「コンテンツ生成」「デジタルアシスタント」「設計とデータ作成」「自然言語検索」「コード生成」だ。
「ドキュメントオートメーション」は、既に存在する膨大な情報を解釈し、その要約や翻訳、解説を行うというもの。生成AIを活用した翻訳は既に一般的なものになっており、コールセンターでのやり取りをテキスト化して要約するといった取り組みも、既に複数の企業で始まっている。
「コンテンツ生成」は、文書や画像などを自動的に生成するというものだ。例えば、メール文面や企画書などの作成支援や、ホームページに掲載する文面や画像の自動生成などが考えられる。
「デジタルアシスタント」は、ユーザーからの質問に回答する、過去の情報から推奨事項を提案する、といったものだ。企業内での利用方法としては、社内の各種ドキュメントの内容をベースに、業務に関する質問に回答する、といった使い方が考えられる。また顧客に対して生成AIによるチャットボットで支援を行い、セルフサービス型での問題解決を容易にする、という使い方もあるだろう。
「設計とデータ生成」は文字通り、設計業務とそれに付随するデータ生成を行うというもの。例えば、ゲノムに関する知見を活用した創薬といった使い方が考えられる。もちろんそのほかの設計領域でも、大きな効果を発揮することが期待される。
「自然言語検索」も文字通り、生成AIによって検索を自然言語で行えるようにすること。そして「コード生成」は、ソフトウエア開発(プログラミング)に生成AIを活用するというユースケースである。
これら6カテゴリーを視野に入れた上で、自社で考えられるユースケースをリストアップ。その上で、「実現可能性」と「事業価値」という2つの軸で、優先順位を決めていくわけだ。
まず「実現可能性」だが、これが低ければ実現までの時間やコストがかかりやすくなり、成功までの道のりが遠くなってしまう。最初の段階でこのようなユースケースに着手してしまうと、次の一歩に進むことが難しくなり、生成AIへの取り組み全体が頓挫する危険性が高い。そのため「実現可能性の高い」ユースケースから着手すべきだ。
次に「事業価値」については、当然ながら事業価値の高いユースケースの方が、投資効果が大きくなる。つまり「実現可能性」が高く、「事業価値」も高いユースケースから着手すべきなのである。
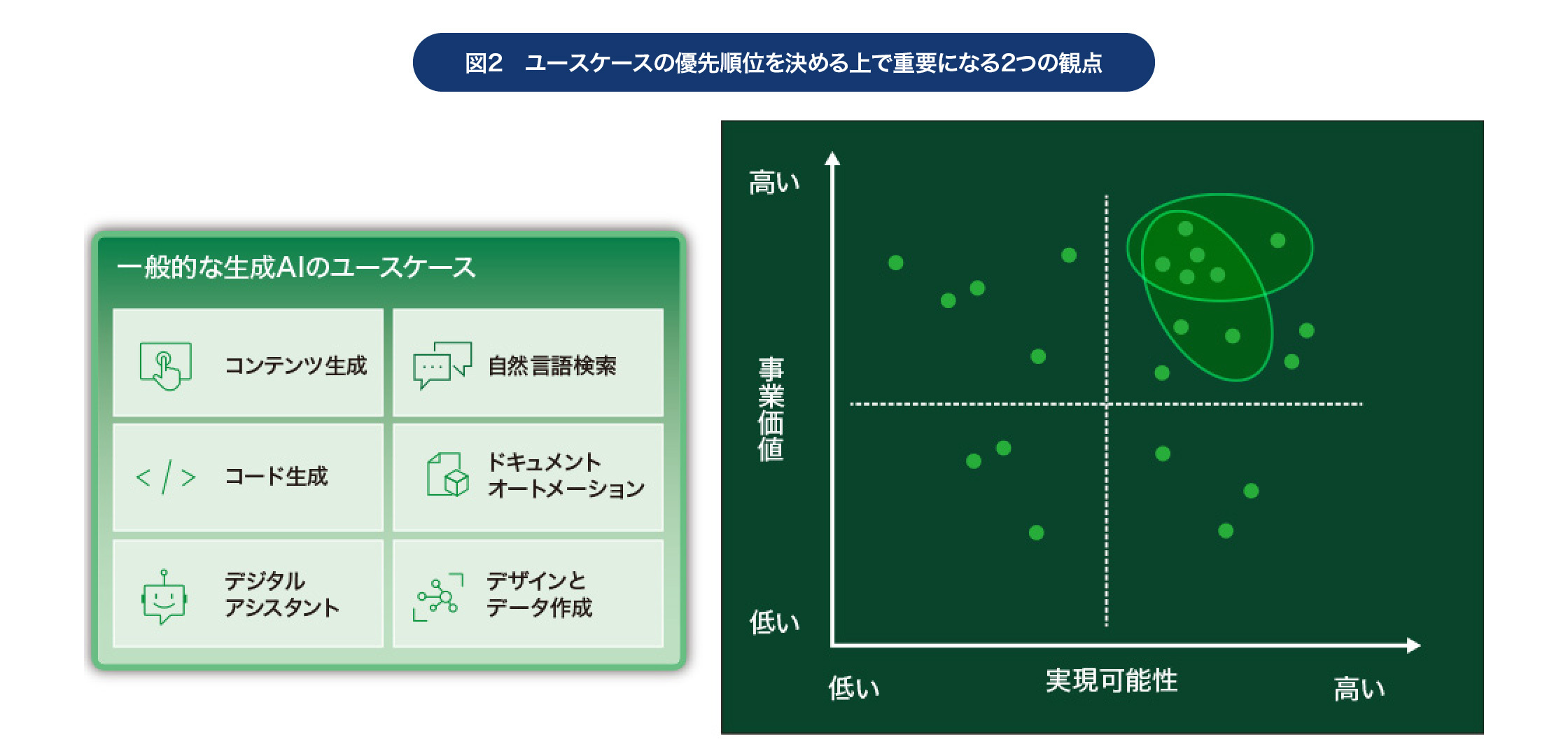
その後、それらのユースケースを「実現可能性」と「事業価値」の2軸でマッピングし、いずれも高い「右上のもの」から取り組んでいくとよいだろう
生成AIの4つの「導入パターン」から最適なものを選択
優先すべきユースケースが決まったら、次はそれをどのように実現するかを考える必要がある。つまり最適な「導入パターン」を選択する必要があるわけだ。
生成AIの導入パターンは、大きく4種類ある。「事前トレーニングされたモデル」をそのまま使うパターン、「モデルの拡張」を行うパターン、「ファインチューニング」を行うパターン、そして「独自モデルをトレーニング」するパターンだ。
ここでこれらの導入モデルがどのような特徴を持っており、どのユースケースカテゴリーに適しているのかを見ていこう。
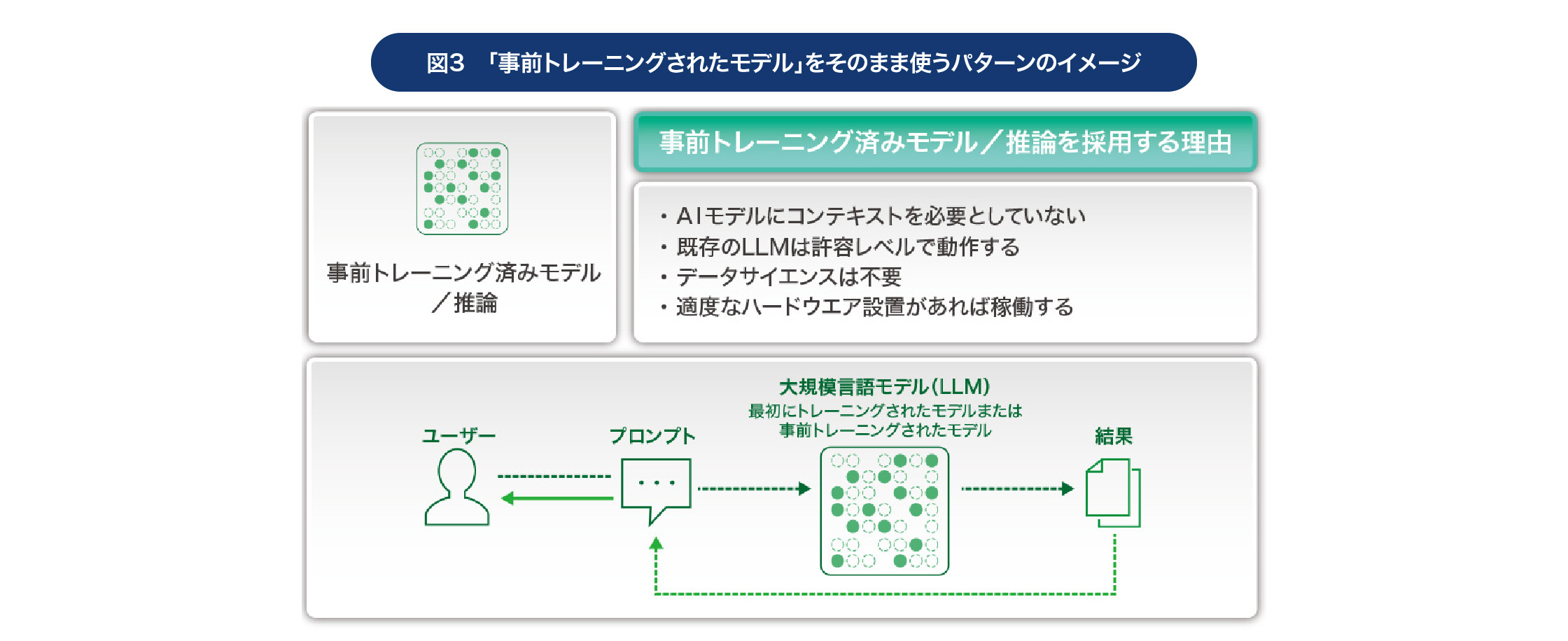
まず「事前トレーニングされたモデル」の導入パターンは、文字通り既存の生成AIモデル(大規模言語モデル:LLM)をそのまま使うというものだ。例えば、ChatGPTをそのまま使う、といったケースが考えられる。
企業固有の専門知識が必要なく、一般的な知識だけで運用できるのであれば、このパターンが最も導入スピードが早く、コストもかからない。またデータサイエンティストも必要なく、多くの場合はシステム開発者も不要だ。前述のユースケースカテゴリーでいえば「ドキュメントオートメーション」がこの導入パターンに適しているといえるだろう。
第2は「モデルの拡張」パターンだが、これは大規模言語モデルによるテキスト生成に外部情報の検索を組み合わせることで、回答精度を高めるという方法だ。このような方法を一般に「RAG( Retrieval-Augmented Generation)」という。
データサイエンティストは必要ないが、生成AIを社内の検索システムと連携させるために、システム開発者が必要なケースが多い。そのため「事前トレーニングされたモデル」をそのまま使うパターンに比べて手間とコストがかかるが、企業固有の知識を比較的短時間で取り込むことができる。前述のユースケースカテゴリーでいえば、「コンテンツ生成」に適したアプローチだといえる。

データサイエンティストは必要ないが、検索システムとの連携のためにシステム開発者が必要になることが多い
第3の「ファインチューニング」パターンは、事前トレーニングされたモデルを別のデータセットを使って「再トレーニング」することで、より正確な結果を得られるようにする、という方法だ。生成AIの活用では、もっともらしい嘘をつく「ハルシネーション」という現象が問題になることが少なくないが、ファインチューニングを行うことでこの問題を軽減できる。また、コンプライアンス上の問題を回避する上でも、有力な選択肢になるといえるだろう。
当然ながら、既存の大規模言語モデルを再トレーニングするには、データサイエンティストの知見が不可欠だ。また再トレーニングは継続的に繰り返す必要があることも忘れてはならない。そのため「モデルの拡張」に比べて手間やコストがかかるが、後述する「独自モデルをトレーニング」に比べれば負荷は小さい。前述のユースケースカテゴリーでいえば「デジタルアシスタント」に向いている。
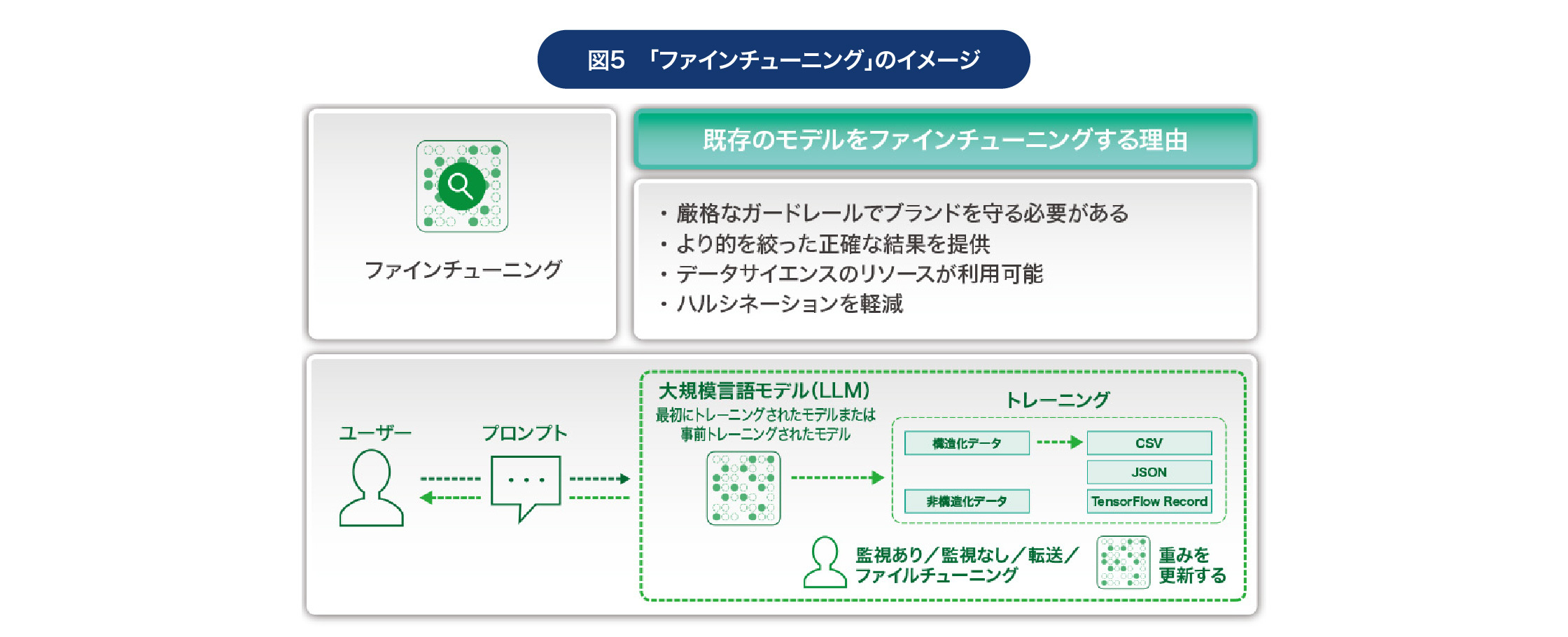
当然ながらデータサイエンティスの参加が不可欠だ
そして第4の「独自モデルをトレーニング」は、最も高度な生成AIの導入パターンだといえる。「モデルの拡張」や「ファインチューニング」を行っても正確な回答が得られない場合には、このパターンを選択することになるだろう。その企業に特化した「最も差別化された生成AI」を生み出すことができる反面、膨大なリソースが必要になる。ユースケースカテゴリーとしては「設計とデータ生成」に適しているといえる。
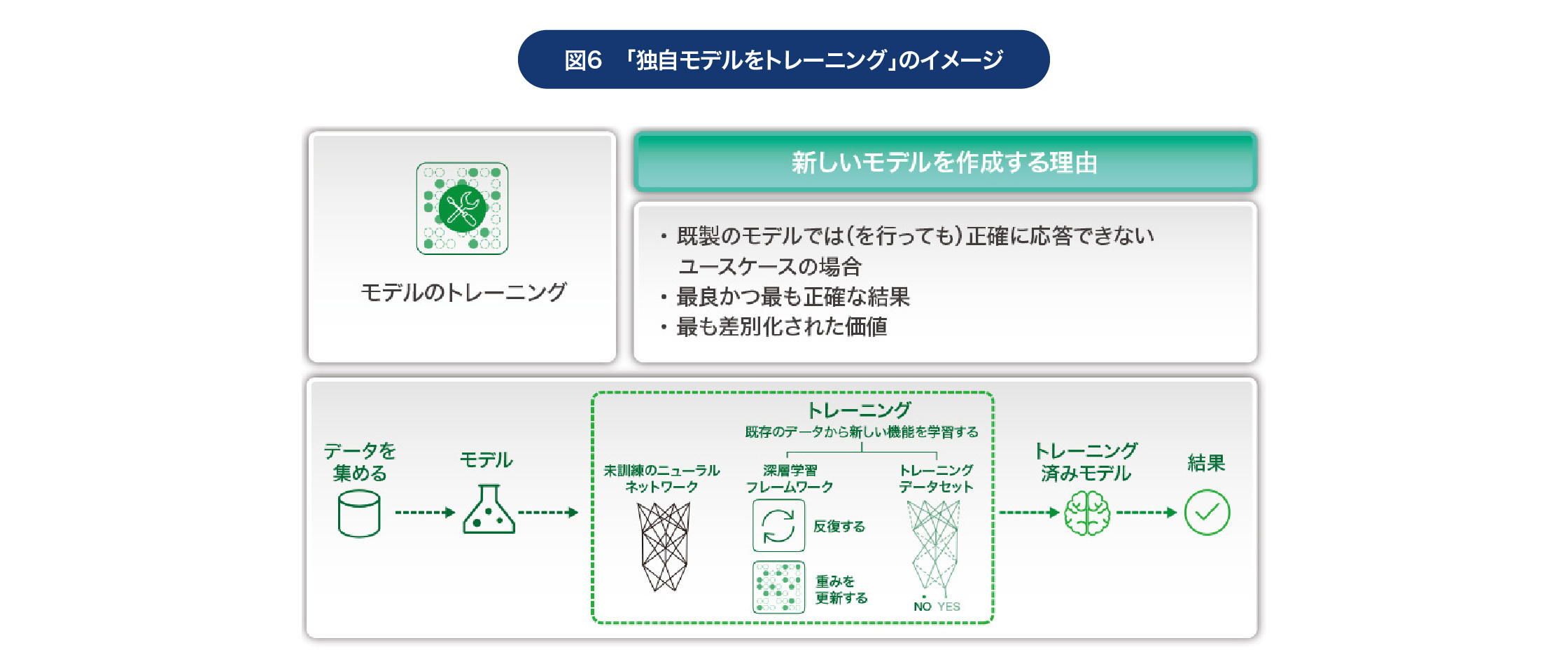
なお実際に取り組む際には、「小さな大規模言語モデル」にするというアプローチが適しているといえるだろう
このパターンを採用する際に注意したいのが、必ずしもChatGPTなどのような、大規模な言語モデルにする必要はないということだ。大規模言語モデルの規模はパラメーター数で表現され、ChatGPT-3では1750億、ChatGPT-4では非公開ではあるものの約5000億といわれているが、これは汎用的な利用を想定したものだということを忘れてはならない。特定の業界やビジネスに特化した「ドメイン固有」の大規模言語モデルであれば数百億、企業固有の知識を学習させたものであれば数十億程度のパラメーターでも、十分に価値のある生成AIをつくり出せる可能性がある。
実際に最近では、小さな大規模言語モデル(small-LLM:sLLM)という考え方も一般化しつつある。企業内で独自モデルを作成するのであれば、このsLLMが最適なアプローチになるといえるだろう。
RAG以降ではデータマネジメントも不可欠に
これらの4つの導入パターンのうち、現在ではほとんどのユーザー企業が「事前トレーニングされたモデル」をそのまま利用しており、一部のユーザー企業が「モデルの拡張(RAG)」に取り組んでいる段階だといえる。今後はRAGに取り組む企業が一気に増えていくことになると予想される。
ここで重要なことが、大きく2点ある。1つは「RAGの目的を明確にする」こと。目的や期待される効果が明確でなければ、どのような外部情報を組み合わせるべきか、そのためにどの程度の投資を行うべきなのか、判断が難しいからだ。もう1つは、そのためにどのようなデータが社内で利用できるのかを明確にすることである。その際には、データの適合性や品質、十分な量のデータが確保できるのか、といったことに留意したい。
また、データマネジメントをどのように実現するのか、そのためのシステムをいかにして構築するかも、考慮すべきだといえるだろう。なおデータマネジメントは、「ファインチューニング」や「独自モデルをトレーニング」を行う際にも不可欠になるため、長期的な視野にもとづいて検討するといいだろう。
以上、生成AIを導入する際のユースケースの選定と、それを実現するための「導入パターン」について解説してきた。これらをしっかり意識することで、生成AI導入の投資効果を高めることが可能になり、次のステップにも進みやすくなるはずだ。

日経BP社(https://techtarget.itmedia.co.jp)の許可により、2024年6月11日~ 2024年8月10日掲載の日経 xTECH Special を再構成したものです。
https://special.nikkeibp.co.jp/atclh/NXT/24/delltechnologies0611/