

L’IA générative (GenAI) a fait une entrée fracassante dans le monde de l’informatique. Nos clients nous le disent assez clairement : ils souhaitent commencer à travailler avec les grands modèles de langage (LLM, Large Language Model) pour innover et développer des applications qui leur offriront davantage de productivité et d’efficacité, ou leur donneront un avantage concurrentiel décisif sur leur marché.
Nous avons chez Dell Technologies le plus large portefeuille de solutions et services dédiés à l’intelligence artificielle*, qui va du poste de travail jusqu’au cloud et qui est pensé pour accompagner les entreprises, quel que soit leur niveau de maturité sur le sujet.
Et une question revient souvent chez nos clients : comment savoir si un PC est capable de prendre en charge tel ou tel LLM ?
Le meilleur PC pour l’IA ? La station de travail !
Tout d’abord, quelques considérations de base sur ce qui est nécessaire pour travailler avec un LLM sur un PC… Ou plutôt une station de travail ! Spécifiquement conçue pour prendre en charge les traitements de données intensifs, la workstation est en effet l’outil idéal pour ce genre de tâche.
Bien que de plus en plus d’opérations puissent être pris en charge par le CPU ou un NPU (Neural Processing Unit), les GPU NVIDIA RTX tiennent aujourd’hui la pole position en matière de traitement de l’IA dans les PC, notamment grâce à des circuits dédiés : les Tensor Cores.
Ces cœurs sont conçus pour les calculs en précision mixte, c’est-à-dire qu’ils peuvent faire cohabiter différents modèles de calcul et niveaux de précision (FP8, FP16, TF32, FP64…). La gamme de GPU NVIDIA offre différentes options sur le nombre de cœurs Tensor et la quantité de mémoire vidéo (VRAM).
Et c’est au sein des stations de travail fixes et mobiles que vous trouverez le plus large choix de configurations. Certaines workstations peuvent même accueillir plusieurs GPU pour offrir un maximum de ressources. Car pour optimiser la performance de votre modèle, vous allez vouloir que votre traitement LLM puisse « rentrer » dans la VRAM du GPU.
La juste quantité de VRAM
On voit aujourd’hui de plus en plus de LLM arriver sur le marché. Et l’un des critères les plus importants pour déterminer la configuration matérielle dont vous aurez besoin est le nombre de paramètres du LLM. Prenez Llama-2 de Meta par exemple. Le LLM est disponible avec 7, 13 ou 70 milliards de paramètres.
De manière générale, comme le montre le tableau ci-dessous, plus le nombre de paramètres est grand, plus la précision sera grande.
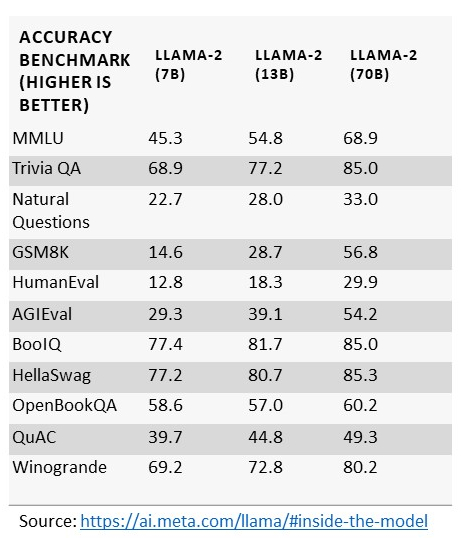
Et assez logiquement, plus le nombre de paramètres est grand, plus les besoins en mémoire seront également importants. La quantification permet de réduire la taille et les besoins des LLM en diminuant la précision des paramètres (nous y reviendront plus en détail dans un prochain article).
Mais que votre objectif soit de prendre le modèle de base et de l’exécuter tel quel à des fins d’inférence ou bien de l’adapter à votre cas d’usage et à vos données spécifiques, il faut bien avoir conscience des exigences que le LLM imposera à la machine.
Une Dell Precision pour chaque niveau de précision
Regardons par exemple l’impact de la quantification sur un modèle comme Llama-2 :

Concrètement, les clients qui souhaitent exécuter le modèle quantifié avec une précision de 4 bits doivent disposer de 4 à 36 Go de mémoire GPU, en fonction du nombre de paramètres. Encore plus concrètement, cela signifie qu’ils trouveront leur bonheur dans la gamme de stations de travail Dell Precision :

L’exécution du modèle avec une précision plus élevée (BF16) augmente donc les besoins en mémoire, mais nous avons des solutions qui peuvent prendre en charge n’importe quelle taille de LLM, quelle que soit la précision requise.

Dans ce cas, la mémoire GPU minimum demandée étant de 70 Go, il ne sera pas possible d’opter pour une station de travail mobile. Mais les stations de travail fixes vous permettent de cumuler jusqu’à 4 GPU NVIDIA RTX 6000 Ada pour atteindre jusqu’à 192 Go de mémoire dédiée et seront donc dans bien des cas le choix le plus adéquat.
Et si vos besoins sont encore supérieurs, les infrastructures PowerEdge pourront aisément prendre le relais !
