Article originally appeared as Schema On Read vs. Schema On Write Explained.

What’s the difference between Schema on read vs. Schema on write?
How did Schema on read shift the way data is stored?
Since the inception of Relational Databases in the 70’s, schema on write has be the defacto procedure for storing data to be analyzed. However recently there has been a shift to use a schema on read approach, which has led to the exploding popularity of Big Data platforms and NoSQL databases. In this post let’s take a deep dive into what are the differences between schema on read vs. schema on write.
What is Schema On Write
Schema on write is defined as creating a schema for data before writing into the database. If you have done any kind of development with a database you understand the structured nature of Relational Database(RDBMS) because you have used Structured Query Language (SQL) to read data from the database.
One of the most time consuming task in a RDBMS is doing Extract Transform Load (ETL) work. Remember just because the data is structured doesn’t mean it starts out that way. Most of the data that exist is in an unstructured fashion. Not only do you have to define the schema for the data but you must also structure it based on that schema.
For example if I wanted to store menu data for a local restaurant how would I begin to set the schema and write the data into the database?

- First task is to setup the tables
- Item
- Ingredients
- Nutritional values
- Next index items to map relationships
- Then write a regular expression to extract fields for each table in the database
- Lastly write SQL insert statements for extracted data
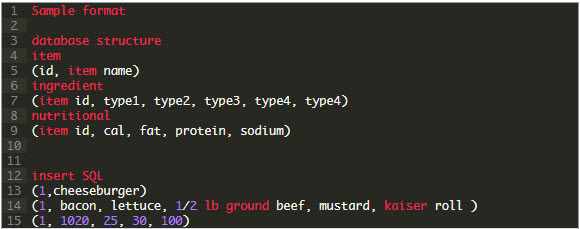
All those steps had to be done before being able to store the data and analyze it for new insights. The overhead for having to do the ETL is one of the reasons new data sets are hard to get into your Enterprise Data Warehouse(EDW) quickly.
What is Schema On Read
Schema on read differs from schema on write because you create the schema only when reading the data. Structured is applied to the data only when it’s read, this allows unstructured data to be stored in the database. Since it’s not necessary to define the schema before storing the data it makes it easier to bring in new data sources on the fly.
The exploding growth of unstructured data and overhead of ETL for storing data in RDBMS is the main reason for shift to schema on read. Many times analyst aren’t sure what types of insights they will gain from new data sources which is why getting new data source is time consuming. Remember back to our schema on write scenario let’s walk through it using schema on read.
- First step is to load our data into the database
Boom! We are done! All of the menu data is in the database. Any insights we want to investigate we can try and apply the schema while testing. Let’s be clear though, we are still doing ETL on the data to fit into a schema but only when reading the data. Think of this as schema on demand!
Key Differences Schema On Read vs. Schema On Write
Since schema on read allows for data to be inserted without applying a schema should it become the defacto database? No, there are pros and cons for schema on read and schema on write. For example when structure of the data is known schema on write is perfect because it can return results quickly. See the comparison below for a quick overview:

There is no better or best with schema on read vs. schema on write. Just like most things in development– it depends on the use case. Is the workload mostly data supporting a dashboard where the results need to be fast and repetitive? It’s going to need to use a schema on write database. Will there be a lot of unknowns with the data and constant new sources? Sounds like a schema on read will work.