My uncle Bill called engine oil “the poor man’s mechanic.” And he was right: refresh the oil every several thousand miles and your engine will perform better and last a lot longer. Admit it: you’ve put it off. (I have.) Now how about that 30K, 45K and 60K mile maintenance? Hmmm, maybe you can delay that too. The dealership will surely charge you big bucks for that tune up.
How punctual you are depends on the cost-benefit analysis you do in your head: Do you have the time? Do you want to part with the cash? The car is running fine right now. So why bother? Put it off.
We play the same mental game when it comes to upgrading and patching infrastructure. It gets more complicated too, when IT environments are siloed (say, versus all-in-one converged infrastructure systems).
Meeting with an enterprise IT team recently, I asked the CIO, “How do you handle upgrades and patches for all layers of infrastructure? Is it a big issue? The CIO said, “not really a problem.”
But one of his top managers replied, “I don’t mean to contradict my boss, but keeping infrastructure upgraded with new releases is our biggest nightmare, our biggest time-sink, when we get around to it.”
The Complications
“When we get around to it.” Sound familiar?
Based on my conversations with IT Operations teams (on average, for three different businesses per week), upgrading is one of the most hated IT tasks. They avoid it all costs. And the costs can be big.
Here are some examples:
- “If it ain’t broke, why fix it? Performance is okay, so why drop other projects to plan and do an upgrade? We have too many other priorities”
- “If it ain’t broke, why risk it? Why upgrade and risk an outage? We don’t have the time or the money for enough lab equipment to test new release interoperability across all the connected infrastructure.”
The Implications
Many organizations either get so far behind in upgrades that it gets them in trouble.
Here are some examples:
- “We had an outage, and I called my equipment vendor as we were trying to find the root cause. They said that couldn’t help us because we were several releases behind. And there wasn’t any one-hop upgrade to get us up to the current firmware level before they could really help us.”
- “We just don’t do upgrades — even for years. We just wait until the system gets so out of date that we retire the hardware. It’s easier that way.”
I really heard someone say that. He must have an unlimited CAPEX budget.
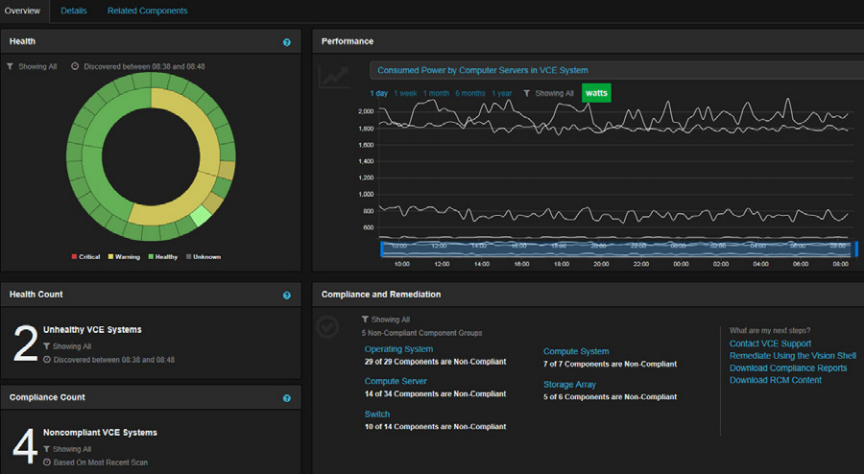
The Solution
The VCE philosophy is to have the compute, storage and network firmware and hypervisor release upgrade process engineered right into its converged systems. This includes:
- Ongoing system documentation of the required release level upgrade (the VCE Release Certification Matrix)
- Scheduled delivery of pre-tested releases, whose interoperability are validated by hundreds of hours of regression testing
- Deliver of patches to address new security vulnerablities or discovered technical glitches
- Management software (VCE Vision Intelligent Operations) that:
- Assesses infrastructure to tell you what needs to be upgraded with the new releases
- Downloads the new pre-tested releases and patches
- Validates that you correctly and thoroughly upgraded all the components
Peace of Mind
That’s what VCE users say about this process. This keeps their converged infrastructure stabilized (by continuously fixing bugs) and optimized (by regularly adding performance and functionality improvements) – without the risk and time-sink of traditional, siloed infrastructure upgrades.
So remember my uncle Bill’s advice, and change your oil.
Take Action
See this short video of VCE Vision Management software.
Download the analyst white paper, that includes VCE Customer interviews about the process.
Down the VCE white paper that outlines the process.