

It’s often said that someone or something has “one job” to do. But when that job is an ETL, it’s more like three. An extract-transform-load process involves copying or migrating data from source to target, while making it more suitable for further queries.
Picture a Chief Information Officer (CIO) with a team of 500, trying to manage 15,000 ETL jobs. Each ETL job is responsible for acquiring, aggregating, standardizing, aligning and moving data across the organization’s operational and customer-facing systems. Add to that, constrained batch processing windows, tight Service Level Agreements (SLAs), and the fact that if any of these ETL jobs fail, downstream data consumers can’t do their jobs. This includes management reporting, operational dashboards, business analytics, and data science. Essentially, the CIO is now functioning as their own systems integrator—cobbling together loosely-coupled, one-off, purpose-built tools and building a brittle, Rube Goldberg-eque contraption to move data to the right repositories at the right time on a consistent basis.
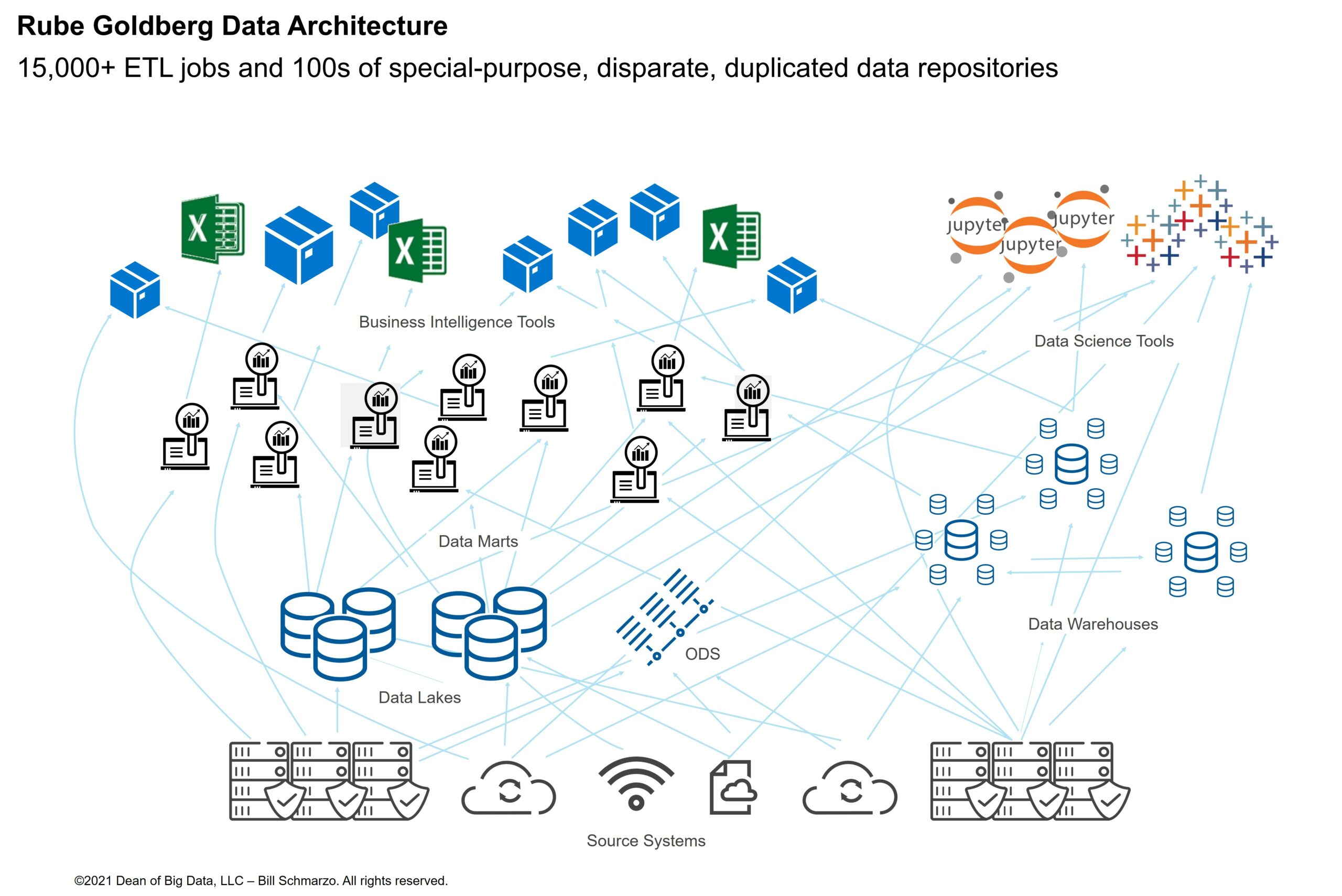
It’s not a pretty picture. More so, it’s the ugly truth about data management—the inefficiencies of which are impacting the businesses’ ability to quickly respond to the ever-changing market, industry, economic, environmental and customer changes and business disruptions. How can businesses solve this massive problem? How can we expect the modern, data-driven business to be agile – with the ability to respond quickly to new business opportunities – when the underlying data management solutions are brittle and batch-centric? And in the process, how can we transform data management from an Information Technology (IT) task into a business-centric discipline to empower the business to unleash the economic value of their organization’s data?
The Data Management Reality
Let’s start with the pain points of data management. For starters:
-
- It is difficult for data consumers (business analysts, report generators, data scientists) to easily find the right data and understand its relevance and applicability due to poor data visibility.
- Data consumers spend too much time on finding data, accessing data, preparing data, and manual cataloging, all activities that get in the way of uncovering and applying those customer, product and operational insights to drive quantifiable business value.
- Distributed data silos lead to isolated insights and heavier lifting for cross-silo data value creation. (In other words, the data does not self-identify).
- New data science toolkits, AI / ML algorithms and analytic capabilities are changing rapidly that must be enabled by the data management framework.
- Duplicated data sources lead to reporting and analytics confusion, distrust of the analytic results, and destroys the unique economics of data enabled thought the sharing, reusing and continuous refinement of the organization’s data assets.
- Finally, the rapid growth of low-latency data at the edge due to the Internet of Things (IoT) is only acerbating the data management problem.
How do you overcome all these challenges?
The Next-Gen Data Management Solution
The next-generation data management solution requires an integrated, end-to-end platform (orchestration layer) embracing distributed data, operating with intelligent (AI/ML-enabled) data pipelines, automating data discovery and tagging, and accelerating data science feature engineering and feature sharing—all while supporting data consumers’ tool choices and analytics operationalization. Specifically, the next-generation data management solution must be able to:
-
- Automate catalog population directly from metadata on distributed sources.
- Leverage event streams and integrate AI/ML to create intelligent data pipelines that automatically update data catalogs while leaving data in place to reduce or eliminate brittle (and expensive) ETL processes.
- Embrace data silos and the accelerating growth of data at the IoT edge, by enabling in-place data processing across hybrid and multi-cloud data sources; that is, bring the applications and the analytics to the data versus the expensive process of duplicating and moving large data sets (remember those 15,000 ETL jobs?).
- Support Feature Stores and an analytics engine and runtime environment with integrated 3rd-party tools to support data consumers’ tools of choice.
Our new whitepaper, The Ugly Truth About Data Management and the Journey to Unleashing the Economic Value of Data, uncovers this ugly truth and the data management reality it creates for modern enterprises. This whitepaper will help business leaders and technical practitioners:
-
- Explore the IT evolutions that necessitate modern data management.
- Undertake shifts in valuation and implementation perspectives required to enable modern data management.
- Understand the path to overcome these challenges and unlock economic value from data in the decade ahead.
Read the whitepaper here.
