Now that the obvious, cheezy title of this blog is past us; let’s get focused on what exactly MetroPoint is and how it works. This blog assumes the reader understands the basic use cases and functionality of VPLEX Metro and RecoverPoint replication topologies.
There is nothing more exciting than bringing two great things that complement one another together and then take that premise and build upon it by listening to customers’ ideas. Let’s go back to when VPLEX and RecoverPoint were unified May of 2012, this released solution allowed VPLEX Metro with RecoverPoint splitter connect to a “3rd site” at supported RecoverPoint asynchronous distances, but only from a single VPLEX site cluster. Essentially , this provided a great way to protect virtual volumes and be able inject RecoverPoint Remote Replication ‘point-in-time’ recovery operations for distances up to 200ms RTT. Next, bring in some really smart customers and subject matter experts, whiteboards and discussions around triangulating these two products by adding the second cluster into the mix; it created fuller continuous availability and operational recovery. This was the OBVIOUS next technological step.
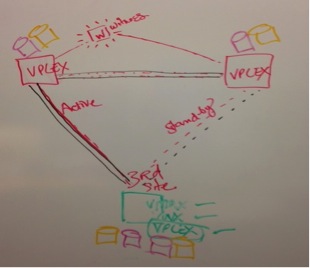
This is kind of what the whiteboard picture would have looked like. It makes all the underlying development and integration look so simple – doesn’t it?
Fast forward to June of this year (2014 for those of you who aren’t paying attention) MetroPoint has been made generally available and provides a 3-site solution that takes a VPLEX Metro (distances within 5-10ms RTT application dependent) and gives the customer a 3rd site provided by RecoverPoint appliance to a target VMAX, VNX or another VPLEX with RP splitter AND you can failover (switchover between 2 Metro sites without impacting protection) between sites. This makes both VPLEX clusters data protected AND continuously available. You can also protect VPLEX Metro DR1 locally using 2 local copies, 1 at each Metro site.
Not the 1st EMC 3-site solution for DR
So, one may ask the question and our savvy Symmetrix customers will; but what about SRDF/Star? Many customers aren’t ready for VPLEX, they have perfectly fine working SRDF/Star which is a 3-site solution for continuous replication and failover. Also, large scale consistency groups and purely homogenous Symmetrix environments benefit from the all-in SRDF solution. So we never discredit the awesome technology behind SRDF. BUT, for customers who want zero RTO, VPLEX makes more sense and also can load balance out an environment with all types of block storage arrays behind it for heterogeneous data mobility, etc.Let’s go back to the business value that VPLEX creates. VPLEX takes the notion of replication out of the equation between data centers. Everything as we know has become active/active and SLAs are no longer attached to the active/passive model. It always comes down to this; what type of outage length and duration are you willing to endure? If you did have an outage, how long would it take you to decide to invoke an actual failover? (more on this philosophy in the next blog)
Real Talks with Real Customers
Most of my conversations with customers whether it be enterprise or mid-tier carries very similar themes. They have business needs that VPLEX Metro can solve whether it be data migrations, tech refresh with also the added benefit of availability 100% uptime with Witness capabilities. The conversation usually starts off with the assessment of the Metro solution and where the customer’s efforts are focused whether it be consolidation to (2) data centers with the desire to have a bunker site or they have too many data centers to consolidate at this time but Metro and 3rd site would help with migrations and moves to consolidation. Other customers may just be continuously expanding and with that they may need multiple implementations of a given solution. Either way, I am always whiteboarding the picture above.
Bring forward the bunker site.
The conversation that we don’t want to have with customers but it comes up a little more these days since we have had unusual activity and weather in North America; is also around resiliency and security of data should a regional disaster occur. We have had tornados, hurricanes, ice storms of epic sizes which have recorded multiple data centers being impacted. Also, there doesn’t have to be a “regional” disaster to warrant the dependency on a 3rd-site but maybe maintenence and failure testing for regulation needs to occur. I am a HUGE proponent of testing what you own and VPLEX Metro is going to give you 7-9s or higher availability then periodic health checks and resiliency testing is ideal. The benefits are all pretty clear as to how MetroPoint can enhance a Metro solution.
Breaking down the behavior
1. Topology. As a customer, I implement VPLEX Metro with active / active access to my devices via distributed virtual volume. I can also activate/enable RecoverPoint CDP (continuous data protection) to BOTH sides of my Metro with the release of RP 4.1.
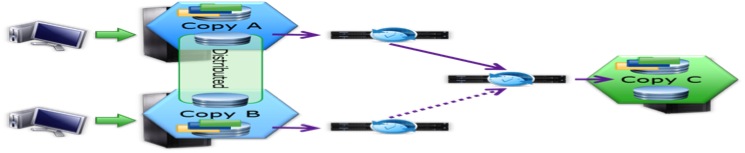
2. Creating Consistency. In the above drawing, it shows that we have (3) copies of data. Copy A and B make up the distributed virtual device configuration per normal Metro creation. Add in Copy C to the remote target via RecoverPoint and contain within a consistency group. A single Consistency Group is configured which contains the (2) Production copies as mentioned, A & B and Replica Copy C. The production copies will differ in functionality as indicated a Primary and a Seconday (Active/Standby). Replication is from the primary to the replica copies and every copy has a journal. The design of the solution for consistency assures that when a “role swap” is done between an Active and Standby leg, it is all done non-disruptedly.
3. Splitters & RPAs. Functionally, the RecoverPoint splitters (enabled in VPLEX) are attached to the volume on both production sites or legs of the Metro cluster. This was not technologically capable previously so is introduced for the MetroPoint functionality. IOs are sent to the RecoverPoint appliances on both legs. On the Primary leg, replication is active; on the Secondary leg, the IOs are being marked.
4. Witness is used and configured per consistency group. The same considerations are applied as these preferred and non-preferred rules are established. End users will choose the preferred site rules and apply to the CG.
5. Failure, Failover When site contact fails or there is a site outage as example, automatic failover occurs, based on bias rules establisehd and guided by witness all of the CGs will invoke the rules applied to continue to take IO and also remote replica to Copy C. Same would occur if the Secondary and Target site failed to communicate, replication continues without interuption.In other words, the remaining cluster remains online and continues to take IO while RP protection whether locally or remotely or both will continue.
This is pretty high-level but breaks down the added layers to the solution. If this gets you thinking about the possibilities for your working environments take a look at these links:
RecoverPoint and VPLEX Technote – nice breakdown of disaster recovery scenarios in the Disaster Recovery section
Video demo of MetroPoint from the RecoverPoint Unisphere management interface
