
Container technology and Docker, in particular, enables application development agility through their developer-centric tooling. As I discussed in my previous blog, the fundamental problem containers set out to address is to enable seamless portability of applications across machines.
The layered copy-on-write implementation of Container images enables faster application builds, efficient storage of images in repository and faster boot-up times for containers. However, the top-most writeable layer is a non-starter for data persistence. Due to the ephemeral nature of the containers, cloud native remained exclusive to stateless applications during their initial years. But, not anymore!
What was missing?
The local data volumes helped developers get past the data persistence problem but, when containers are deployed in large scale or in production, the local data volumes posed several challenges to the applications and operations teams:
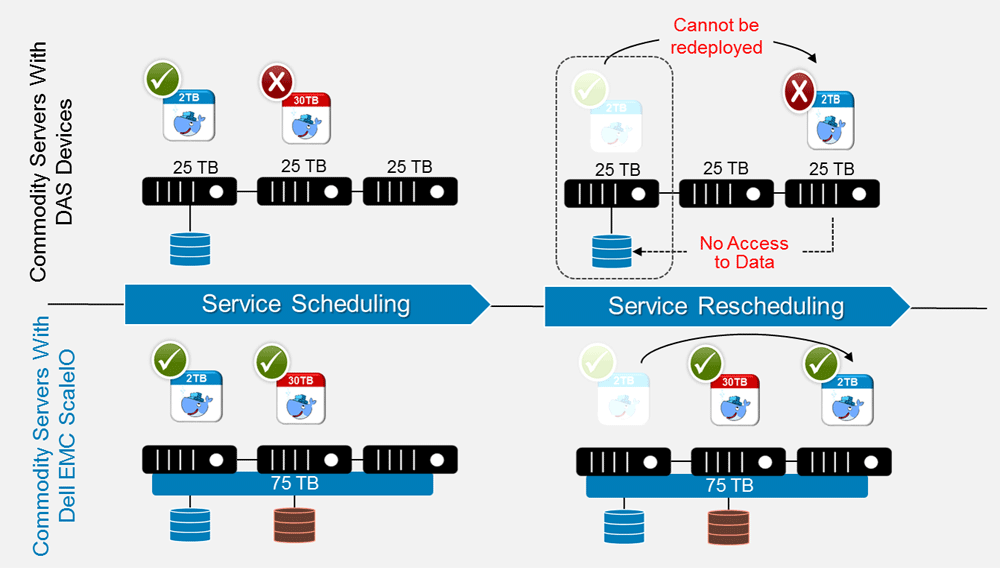
- Data inaccessibility: Container orchestrator (CO) platforms like Kubernetes schedule application services based upon the resources available within a cluster. However, by placing the application data on the storage devices available within the local server, container schedulers cannot flexibly schedule or reschedule services, as pointed out in the figure below.
- Limited scalability: The local data volume can scale in terms of both performance and capacity only to what is available in the local node.
- High availability for enterprise applications: Enterprise application require 6-9’s of data availability. However, local data volumes are prone to data loss should either the direct attached storage (DAS) devices or the entire server fail abruptly.
- Infrastructure inefficiency and management complexity: Keeping silos of data spread across random servers in the cluster lead to inefficient utilization of storage and complex enterprise data life cycle management.
Storage strategy for stateful containers:
A better deployment pattern for persistent layer would be to abstract storage devices available across multiple server nodes and create a virtual pool of storage, from which container schedulers can draw storage, as shown below.
Dell ScaleIO software defined storage helps you just achieve that while delivering very high performance, enterprise-class features and the ability to run infrastructure as a code.
- ScaleIO is hardware-agnostic and can take advantage of any type of media available in the industry-standard x86 hardware.
- The enterprise features such as data services, multi-tenancy, high resiliency and security enable deploying enterprise applications in cloud native architecture.
- As a software-based storage that can be deployed and operated through its API, ScaleIO integrates seamlessly into the cloud native ecosystem.
Got questions? Leave a comment or join our upcoming webcast on 11/09 at 9 AM Pacific to discuss. To try ScaleIO yourself, visit www.dellemc.com/getscaleio to start your evaluation today!