I use the phrase “fail fast / learn faster” to describe the iterative nature of the data science exploration, testing and validation process. In order to create the “right” analytic models, the data science team will go through multiple iterations testing different variables, different data transformations, different data enrichments and different analytic algorithms until they have failed enough times to feel “comfortable” with the model that they have developed.
However an early variant of this process has been employed a long time: it’s called the Scientific Method. The scientific method is a body of techniques for investigating phenomena, acquiring new knowledge, or correcting and integrating previous knowledge. To be termed scientific, a method of inquiry is commonly based on empirical or measurable evidence subject to specific principles of reasoning[1] (see Figure 1).
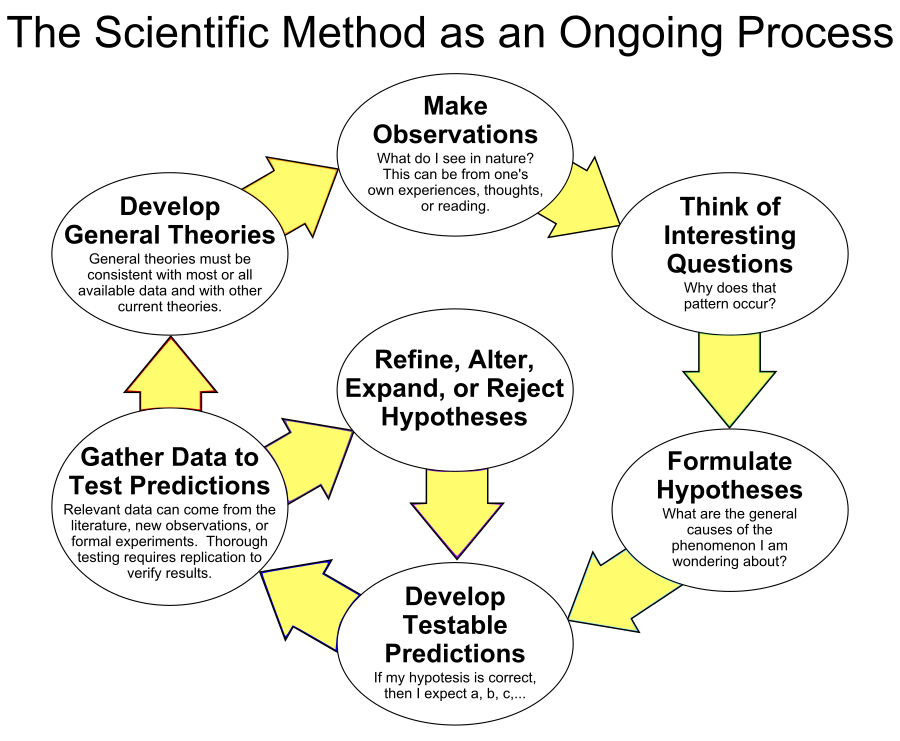
The Scientific Method is comprised of the following components:
- Process: The overall process involves making hypotheses, deriving predictions from them as logical consequences, and then carrying out experiments based on those predictions to determine whether the original hypothesis was correct.
- Hypothesis Formulation: This stage involves finding and evaluating evidence from previous experiments, personal observations, and the work of other scientists. Sufficient time and effort should be invested in formulating the “right” hypothesis, as it will directly impact the process and potential outcomes.
- Hypothesis: Terms commonly associated with statistical hypotheses are null hypothesis and alternative hypothesis. A null hypothesis is the conjecture that the statistical hypothesis is false. Researchers normally want to show that the null hypothesis is false. The alternative hypothesis is the desired outcome. Hypothesis testing is confusing because it’s a proof by contradiction. For example, if you want to prove that a clinical treatment has an effect, you start by assuming there are no treatment effects—the null hypothesis. You assume the null and use it to calculate a p-value (the probability of measuring a treatment effect at least as strong as what was observed, given that there are no treatment effects). A small p-value is a contradiction to the assumption that the null is true; that is, it casts doubt on the null hypothesis[2].
- Prediction: This step involves creating multiple predictions (predictive models) using different data sources and analytic algorithms in order to determine the logical consequences of the hypothesis. One or more predictions are selected for further testing in the next step.
- Testing: The purpose of an experiment is to determine whether observations of the real world agree with or conflict with the predictions derived from the hypothesis. If the observations agree, confidence in the hypothesis increases; otherwise, confidence decreases.
- Analysis: This involves analyzing the results of the testing to determine next testing steps and/or actions.
Data Science Engagement Process
We have expanded upon the Scientific Method to take advantage of new data science technologies (e.g., machine learning, neural networks, reinforcement learning) and new big data capabilities (e.g., Hadoop, data lake, elastic data platform). Our data science team uses the Data Science engagement process outlined in Figure 2 to identify those variables and metrics that might be better predictors of performance.
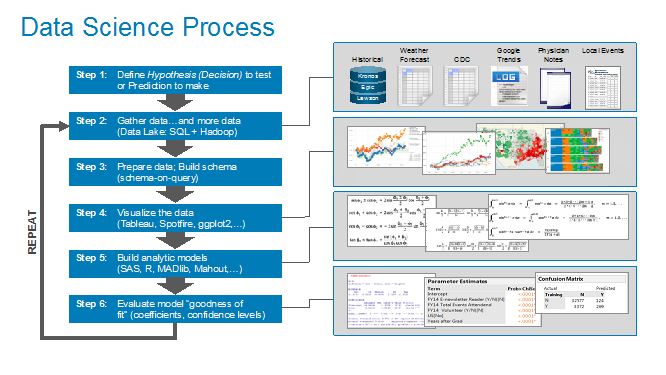
Our data science engagement process is comprised of the below steps:
- Define Hypothesis. Step 1 identifies and validates the prediction or hypothesis to test. The hypothesis is created in collaboration with the business users to understand the sources of business differentiation (e.g., how the organization delivers value) and then brainstorming variables and metrics that might yield better predictors of business or operational performance.
- Gather Data. Step 2 is where the data science team gathers relevant and/or interesting data from a multitude of sources – both internal and external to the organization. The data lake is essential to this process, as the data scientist can grab any data they want, test it, ascertain its value given the hypothesis or prediction, and then decide whether to include that data in the predictive model or throw it away.
- Build Data Model. Step 3 builds the schema (typically a flat file due to expediency and flexibility reasons) necessary to start testing the hypothesis. Note: this “schema on query” process is notably different than the traditional data warehouse “schema on load” process. The data scientist can’t afford to spend weeks or months integrating the interesting different data sources together into a formal data model first. Instead, the data scientist will define the schema as needed based upon the type of analysis being performed.
- Explore The Data. Step 4 of the Data Science process leverages data visualization tools to uncover potential correlations and outliers in the data. The data visualization tools are not focused on building dashboards, but instead are focused on identifying variables and metrics that might be better predictors of performance.
- Build and Refine Analytic Models. Step 5 is where the real data science work begins – where the data scientist uses tools like SAS, SAS Miner, R, Mahout, MADlib, and TensorFlow to build the analytic models. The data scientist will explore different data transformations, data enrichments, and analytic algorithms to try to create the most predictive models.
- Ascertain Goodness of Fit. Step 6 in the data science process is where the data science team will try to ascertain the model’s goodness of fit. The goodness of fit of a statistical model describes how well the model fits a set of observations. A number of different analytic techniques will be used to determine the goodness of fit including Kolmogorov–Smirnov test, Pearson’s chi-squared test, analysis of variance (ANOVA) and confusion (or error) matrix.
- Repeat. And maybe the most important step in the process is to Repeat – continue to repeat the analysis process until the data science team – in collaboration with the business stakeholders – feel comfortable with the resulting model.
See the blog “Dynamic Duo of Analytic Power: Business Intelligence Analyst PLUS Data Scientist” for a comparison of the Business Intelligence and Data Science approaches.
Scientific Method Summary
“It’s tough to make predictions, especially about the future” to quote Yogi Berra
Because the future is hard to predict, data science team must embrace a highly iterative, highly creative methodology where they test enough different data transformations, data enrichments and analytic models in order to feel comfortable with the analytic results; to fail enough times to feel “comfortable” with the model that has been built.
But this is process is really nothing new as different scientific disciplines have embraced the Scientific Method for centuries. We are just tweaking what we’ve learned to take advantage of the new tools (machine learning, reinforcement learning, artificial intelligence) and methodologies (data lake) to morph that process for the discipline of advanced analytics.
