

Computational Storage is the next evolution in data-centric computing to improve data and compute locality and improve economies of scale. The focus is to federate data processing by bringing application-specific processing closer to data instead of moving data to the application. It benefits the overall data center environment by freeing up host CPU and memory for running customer applications, reducing network and I/O traffic by moving processing to data, and improving security by minimizing data movement thus lowering the overall carbon footprint from a sustainability perspective.
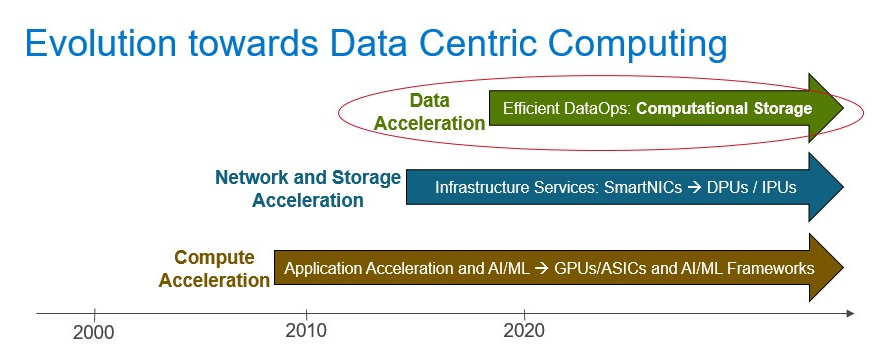
The evolution towards data-centric computing started with “Compute Acceleration” in the last decade which focused on Application Acceleration and AI/ML, leading to an industry focus on GPUs, ASICs, AI/ML frameworks and AI-enabled applications. GPUs/ASICs are now broadly deployed in the AI/ML use cases. The second phase of data-centric computing focused on “Network and Storage Acceleration”. It started with focusing on FPGAs and SmartNICs and evolved over the last two years, with a broader industry focus on DPUs (Data Processing Units) and IPUs (Infrastructure Processing Units).
These enable disaggregation of data center hardware infrastructure and software services to enable logically composable systems and optimized dataflows. DPUs/IPUs are broadly adopted in cloud and gaining momentum in enterprise deployments. “Data Acceleration” is the next step in the evolution towards data-centric computing and Computational Storage is the key underlying technology to enable this Data Acceleration.
 The focus of Computational Storage technologies is to move computation closer to data by best leveraging silicon diversity and distributed computing. It will enable an evolution from “data storage” system of today to “data-aware” systems of future for more efficient data discovery, data processing, data transformation and analytics. In the next few years, we will see it reach a similar level of maturity and industry momentum as we see with GPUs/ASICs for AI/ML, and with DPUs/IPUs for network and storage processing.
The focus of Computational Storage technologies is to move computation closer to data by best leveraging silicon diversity and distributed computing. It will enable an evolution from “data storage” system of today to “data-aware” systems of future for more efficient data discovery, data processing, data transformation and analytics. In the next few years, we will see it reach a similar level of maturity and industry momentum as we see with GPUs/ASICs for AI/ML, and with DPUs/IPUs for network and storage processing.
Computational Storage Drives (CSD), Computational Storage Processors (CSP), Data Processing Units (DPU) are underlying technology enablers to move data processing in hardware and improve overall economics of the data center deployment. FPGAs (Field-Programmable Gate Arrays) will also play a role by providing a software-programmable element for application-specific processing and future innovation. These are being integrated into CSDs and CSPs for high-performance application-specific processing.
There has been industry activity across startups, system vendors, solution vendors and cloud service providers in last two years for computational storage solutions. The challenge is the integration of computational storage interfaces with applications and the broad availability of hardware acceleration capabilities in storage devices and platforms.
Multiple standards efforts are underway in NVM Express and SNIA to standardize the architecture model and command set for block storage. SNIA architecture for computational storage covers CSD, CSP and CSA (Computational Storage Array), where a CSA typically includes one or more CSDs, CSPs and the software to discover, manage and utilize the underlying CSDs / CSPs. The integrated solutions are an example of CSA. The standardization and open-source efforts will further evolve to object and file protocols since most applications access and store data using files and objects.
Since computation can only be moved to a point where there is an application-level context of data or where that context can be created, you will also see computational interfaces emerge for file and object storage systems. There are opportunities to extend the file and object access methods to federate application-specific processing closer to data and only send the results to the application. Integration with emerging software-defined databases and data-lake architectures will make it transparent for user applications that run on top of the data-lake and improve performance and economics of the solution.
The increased adoption of Edge deployments creates further opportunities to federate application-specific processing to Edge locations where data is generated. Computational Memory is also emerging as an adjacent technology to move computation to data in memory. This will enable computation in future persistent memory fabrics. HBM (High Bandwidth Memory) will be interesting not only for GPUs, but also for the data transformation engines integrated in storage platforms.
The data operations will be both fixed function and programmable. Modern storage systems are built using a software-defined architecture based on containerized micro-services. This creates an opportunity to run application specific computation in the form of secured micro-services on the horizontally scalable storage system nodes or all the way on the computational storage disk drive or computational persistent memory. We will see future databases and data lake architectures take advantage of computational storage concepts for more efficient data processing, data discovery and classification. Here is a view from last year on Computational Storage in Data Decade.
Dell Technologies is working with industry standards groups and partners to further evolve computational storage technologies and delivering integrated solutions for customers. Architectures for federated data processing will further evolve in 2022 and pave the way for the next evolution in data-centric computing.
We will see “data storage” systems of today evolve to “data-aware” systems of future. These systems will be able to auto-discover, classify and transform data based on policies and enable organizations to move from digital-first to data-first organizations. The application specific data processing will federate closer to data and optimize the overall economics of data center and edge-to-cloud architectures. Stay tuned for more on this later in 2022 and 2023.