Originally posted as Bound vs. Unbound Data in Real Time Analytics.
Breaking The World of Processing
Streaming and Real-Time analytics are pushing the boundaries of our analytic architecture patterns. In the big data community we now break down analytics processing into batch or streaming. If you glance at the top contributions most of the excitement is on the streaming side (Apache Beam, Flink, & Spark).
What is causing the break in our architecture patterns?
A huge reason for the break in our existing architecture patterns is the concept of Bound vs. Unbound data. This concept is as fundamental as the Data Lake or Data Hub and we have been dealing with it long before Hadoop. Let’s break down both Bound and Unbound data.

Bound Data
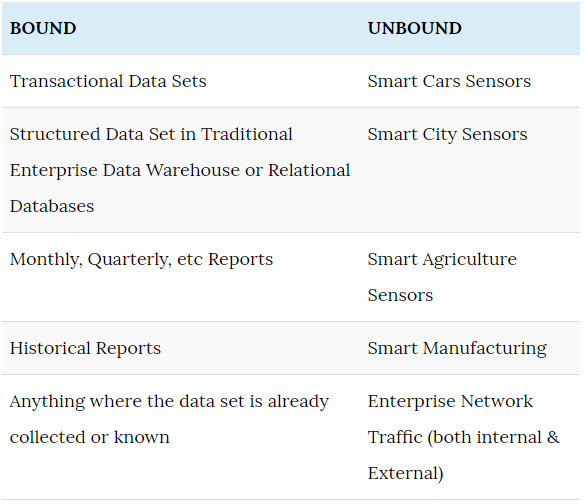
Bound data is finite and unchanging data, where everything is known about the set of data. Typically Bound data has a known ending point and is relatively fixed. An easy example is what was last year’s sales numbers for Telsa Model S. Since we are looking into the past we have a perfect timebox with a fixed number of results (number of sales).
Traditionally we have analyzed data as Bound data sets looking back into the past. Using historic data sets to look for patterns or correlation that can be studied to improve future results. The timeline on these future results were measured in months or years.
For example, testing a marketing campaign for the Telsa Model S would take place over a quarter. At the end of the quarter sales and marketing metrics are measured deeming a success or failure for the campaign. Tweaks for the campaign are implemented for next quarter and the waiting cycle continues. Why not tweak and measure the campaign from the first onset?
Our architectures and systems were built to handle data in this fashion because we didn’t have the ability to analyze data in real-time. Now with the lower cost for CPU and explosion in Open Source Software for analyzing data, future results can be measured in days, hours, minutes, and seconds.
Unbound Data
Unbound data is unpredictable, infinite, and not always sequential. The data creation is a never ending cycle, similar to Bill Murray in Ground Hog Day. It just keeps going and going. For example, data generated on a Web Scale Enterprise Network is Unbound. The network traffic messages and logs are constantly being generated, external traffic can scale-up generating more messages, remote systems with latency could report non-sequential logs, and etc. Trying to analyze all this data as Bound data is asking for pain and failure (trust me I’ve been down this road).

Our world is built on processing unbound data. Think of ourselves as machines and our brains as the processing engine. Yesterday I was walking across a parking lot with my 5 year old daughter. How much Unbound data (stimuli) did I process and analyze?
- Watching for cars in the parking lot and calculating where and when to walk
- Ensuring I was holding my daughter’s hand and that she was still in step with me
- Knowing the location of my car and path to get to car
- Puddles, pot holes, and pedestrians to navigate
Did all this data (stimuli) come in concise and finite fashion for me to analyze? Of course not!
All the data points were unpredictable and infinite. At any time during our walk to the car more stimuli could be introduced(cars, weather, people, etc). In the real world all our data is Unbound and has always been.
Better Architectures for Bound vs. Unbound Data
What does this mean? It means we need better systems and architectures for analyzing Unbound data, but we also need to support those Bound data sets in the same system. Our systems, architectures, and software has been built to process bound data sets. Since the 1970’s where relations database were built to hold data collected. The problem is in the next 2-4 years we are going to have 20 – 30 billion connected devices. All sending data that we as consumers will demand instant feedback on!
On the processing side the community has shifted to true streaming analytics projects with Apache Flink, Apache Beam and Spark Streaming to name a few. Flink is a project showing strong promise of consolidating our Lambda Architecture into a Kappa Architecture. By switching to a Kappa Architecture developers/administrators can support on code base for both streaming and batch workloads. Not only does this help with the technical debt of managing two system, but eliminates the need for multiple writes for data blocks.
Will your architecture support 10 TBs more? How about 4 PBs?
Isilon’s Scale-Out architecture provides a Data Lake that can scale independently with CPU or Storage. Need to add more data to the cluster, but don’t need add processing? No problem add more Isilon nodes to add the capacity needed while keeping CPU levels the same. Scale-out is not just Hadoop clusters that allow for Web Scale, but the ability to scale compute intense workloads vs. storage intense. Most Hadoop cluster are extremely CPU top heavy because each time storage is needed CPU is added as well.
Both Bound and Unbound data will need true steaming and Scale-out architectures to support the 30 Billion devices coming……